基于混合注意力机制的SAR图像车辆目标识别方法
本发明涉及计算机视觉,更具体地说,它涉及基于混合注意力机制的sar图像车辆目标识别方法。
背景技术:
1、sar图像目标识别是sar图像目标检测的接续任务,是实现遥感图像智能解译的关键技术。
2、许多基于模板和基于机器学习的sar图像目标识别算法被提出并取得了一定的成效。然而,这些传统sar图像目标识别算法存在以下缺点:(1)特征提取不充分,传统sar图像目标识别算法通常使用手工设计的特征提取方法,这些方法往往只能提取图像的局部特征,无法全局考虑目标的特征,导致提取的特征不够充分。(2)特征冗余,由于传统sar图像目标识别算法采用的是手工设计的特征提取方法,往往存在大量的冗余特征,这些冗余特征不仅会降低识别准确率,还会增加计算量。(3)特征选择困难,由于传统sar图像目标识别算法中存在大量的冗余特征,因此需要进行特征选择以减少特征的数量。但是由于特征之间存在复杂的相互作用关系,因此往往很难选择最优的特征子集。(4)特征组合困难,传统sar图像目标识别算法通常使用的是基于浅层模型的分类器,这些分类器只能处理简单的线性特征组合,无法处理复杂的非线性特征组合,导致识别精度较低。这些缺点给sar图像目标识别的实际应用带来了巨大的挑战。
3、卷积神经网络模型可以自动提取不同目标的重要特征,通过具有强大特征表达能力的卷积神经网络模型提取目标特征,显著减少了sar图像目标识别过程中的工作量。同时可以避免人工设计目标特征的局限性,显著提高sar图像目标的识别能力。与此同时,卷积神经网络在sar图像目标识别领域的应用也成为了一个研究热点。
4、在深度学习中,模型通常需要处理高维、复杂的输入数据。这些输入数据中包含了大量的信息,但并不是所有的信息都对模型的输出结果有贡献。因此,模型需要在处理输入数据时,将更多的注意力放在与任务相关的部分上,从而提高模型识别的准确率和效率。注意力机制就是一种对输入数据进行加权处理的方法,通过加权突出目标重要特征,使得模型可以更好地关注图像中与目标识别相关的部分,从而提高识别的准确率。研究者们也提出了一些新的注意力机制模块,主要可分为三个类别:空间注意力、通道注意力和空间与通道协调注意力。与此同时,在sar图像目标识别领域,一些研究人员也致力于应用注意力机制提高网络的识别性能。zhang等人提出了一种有效的sar自动目标识别轻量级注意力机制卷积神经网络模型(an effectively lightweight attention mechanism convolutionalneural network,am-cnn),与传统的卷积神经网络和最先进的方法相比,此模型在提高性能和效率方面具有显著优势。li等人提出了一种全卷积注意力块(fully convolutionalattention block,fcab),它可以与卷积神经网络相结合,以细化合成孔径雷达sar图像中的重要特征并抑制不必要的特征,为sar识别带来了显著的性能增益。wang等人提出了一种基于googlenet结构、结合不对称金字塔非局部块(asymmetric pyramidnon-local block,apnb)和senet的非局部通道注意力网络sar图像目标识别方法(googlenet-apnb-iseb),通过senet可以获得基于不同尺度特征融合的信道依赖性,提升识别精度。xu等人提出了一种坐标注意的多尺度胶囊网络(multi-scale capsule network with coordinateattention,ca-mcn),部署了多尺度特征提取器和协调注意力,通过多个扩张卷积层来提取鲁棒特征。
5、然而,上述方法对卷积神经网络注意力部分的改进仅仅考虑了空间信息和通道信息,或者仅仅考虑了空间与通道协调信息,没有考虑空间信息、通道信息和空间与通道协调信息三者的综合加权。
技术实现思路
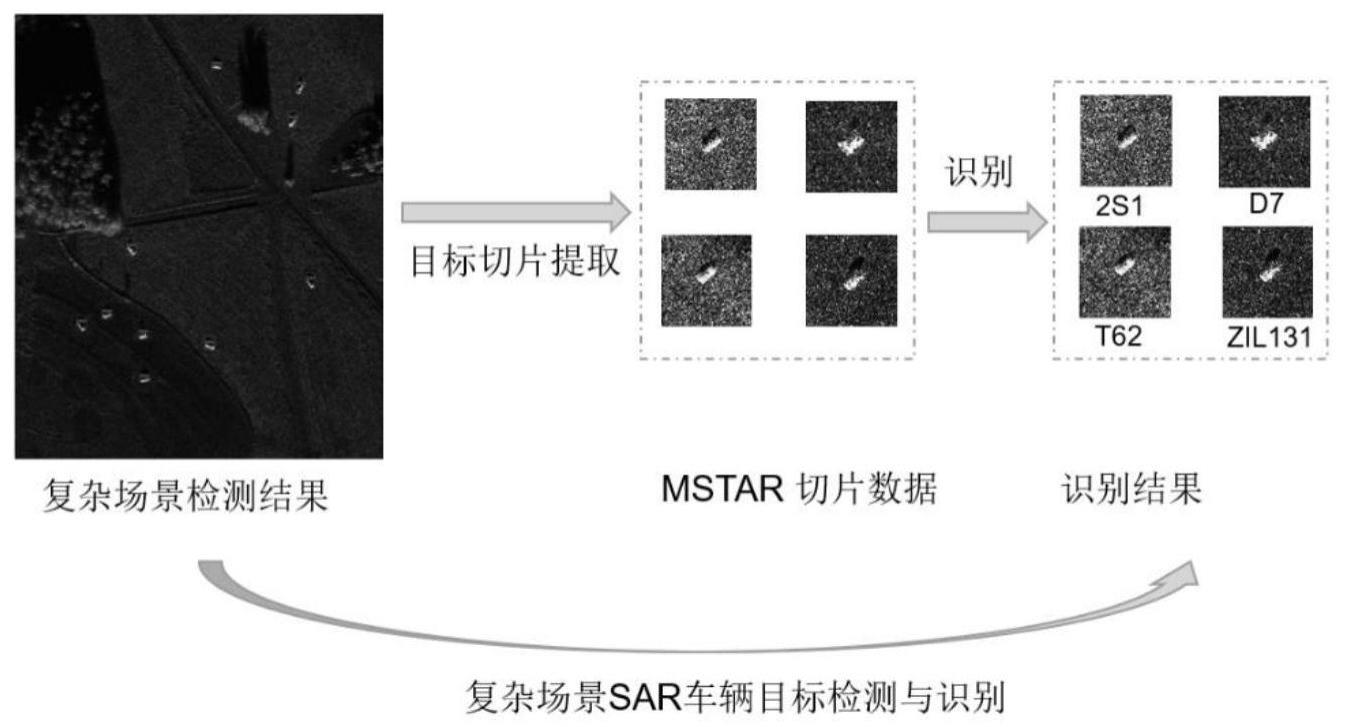
1、本发明的目的是为了解决上述问题,提供基于混合注意力机制的sar图像车辆目标识别方法,提出了一种基于混合注意力(mixed attention,ma)机制的sar图像车辆目标识别网络(mixed attention mobilenetv2,ma-mobilenetv2),在mobilenetv2网络中引入混合注意力机制。混合注意力机制可以充分考虑空间注意力(spatial attention,spa)、通道注意力(channel attention,cha)以及空间与通道协调注意力(coordinate attention,ca)的计算,互补地对输入特征图进行加权,以增强感兴趣区域特征的表示。本章算法在深度神经网络sar图像车辆目标识别中考虑了空间注意力、通道注意力以及空间与通道协调注意力的计算,有效提升了sar图像车辆目标识别的准确率。由于实测场景下的sar图像车辆目标数据集不完备,故在mstar数据集上开展实验。首先在复杂场景mstar仿真sar图像上测试dc-yolox的目标检测性能,接着在mstar切片数据集上验证ma-mobilenetv2的识别性能。结果显示,ma-mobilenetv2的识别性能优越,对10类目标的平均识别准确率可达99.85%。平均识别准确率较未改进的mobilenetv2网络提升了3.1%,也优于最近报道的基于注意力相关改进的sar图像车辆目标识别算法。
2、本发明的上述技术目的是通过以下技术方案得以实现的:基于混合注意力机制的sar图像车辆目标识别方法,包括以下步骤:
3、s1、数据集:采用mstar数据集;
4、s2、混合注意力模块设计:根据实际需求和场景特点,设计合适的混合注意力模块;
5、s3、模型架构设计:设计基于混合注意力机制的改进网络ma-mobilenetv2;
6、s4、模型训练:使用mstar数据集进行模型训练;
7、s5、模型评估和优化:通过对比实验和性能评估指标,对模型进行评估和优化;
8、s6、实施和部署:将训练好的模型应用于实际场景中的复杂sar图像车辆目标识别任务,可以使用图像处理库或自定义软件实现模型的部署。
9、本发明进一步设置为:步骤s3中,所述ma-mobilenetv2是将混合注意力引入到mobilenetv2网络中,充分考虑空间注意力、通道注意力以及空间与通道协调注意力对输入特征图的综合加权,增强感兴趣区域特征的表示。
10、本发明进一步设置为:步骤s2中,所述混合注意力模块包括空间注意力、通道注意力和空间与通道协调注意力机制。
11、本发明进一步设置为:步骤s5中,所述评估指标包括准确率、召回率,所述准确率和召回率计算公式为:
12、
13、
14、式中:tp是识别结果中的预测正确的目标个数,fp是预测错误的目标个数,np是真实目标个数,p是识别精度,r是召回率。
15、综上所述,本发明具有以下有益效果:
16、提高识别准确率:通过引入混合注意力机制,模型能够自动抑制图像中不重要的区域,并将注意力集中在有用的区域上,从而提高对车辆目标的准确识别能力。相较于传统方法,该技术方案在sar图像车辆目标识别任务中能够显著提高识别准确率。
17、增强识别稳定性:混合注意力机制模块能够综合考虑空间和通道的注意力,以及空间与通道的协调注意力,对输入特征图进行加权,从而提升模型的稳定性。通过减小测试损失的波动性,该技术方案能够提高模型在复杂场景下的稳定性。
18、适应复杂场景:复杂场景中的sar图像往往具有强烈的噪声、干扰和遮挡等问题,这给车辆目标识别带来了挑战。基于混合注意力机制的技术方案能够自动聚焦于感兴趣的区域,并对重要特征进行加权,以适应复杂场景下的sar图像特点,提高对车辆目标的识别能力。
19、减少计算复杂度:混合注意力机制能够自动降低模型的复杂度,并提高模型的性能。通过只关注图像中重要的区域,该技术方案能够减少计算量,提高运行效率。
- 还没有人留言评论。精彩留言会获得点赞!