基于多模态大语言模型的有声书自动生成方法
本发明涉及人工智能和数字媒体领域,具体涉及使用多模态大语言模型自动生成有声书。
背景技术:
1、有声书的优势:有声书因为诸多优势而受到欢迎,如可以在任何地方、任何时间听,无需因阅读而引发眼睛疲劳,以及有可能提高外语听力技能等。
2、现有有声书的局限性:当前的有声书有几个局限性。
3、1、大部分由语音合成引擎生成,它们使用单一的声音读取所有文本,无法反映出不同的角色、场景和情绪,导致体验不佳;
4、2、一些流行的有声小说由单一主持人全程朗读,能够更有效地表达角色、场景和情绪的差异。然而,这些有声小说生产效率低,制作成本高,因为主持人需要做大量的准备、策划、表演和录音工作;
5、3、质量不一,这在很大程度上取决于主持人的才华、对原作的理解,从而导致质量的巨大随机性;
6、4、表达力有限,因为它们通常使用单一的主持人为所有角色配音,导致单调,甚至男女声音都由同一位主持人完成。
技术实现思路
1、本发明提出了一种基于多模态大语言模型的有声书自动生成方法。该方法利用多模态大语言模型,根据角色的性别、年龄、性格等特点生成独特的声音和风格,维护整本书的语音一致性,根据场景和角色的情绪调整语调、语速和音量,并真实地生成背景声音。
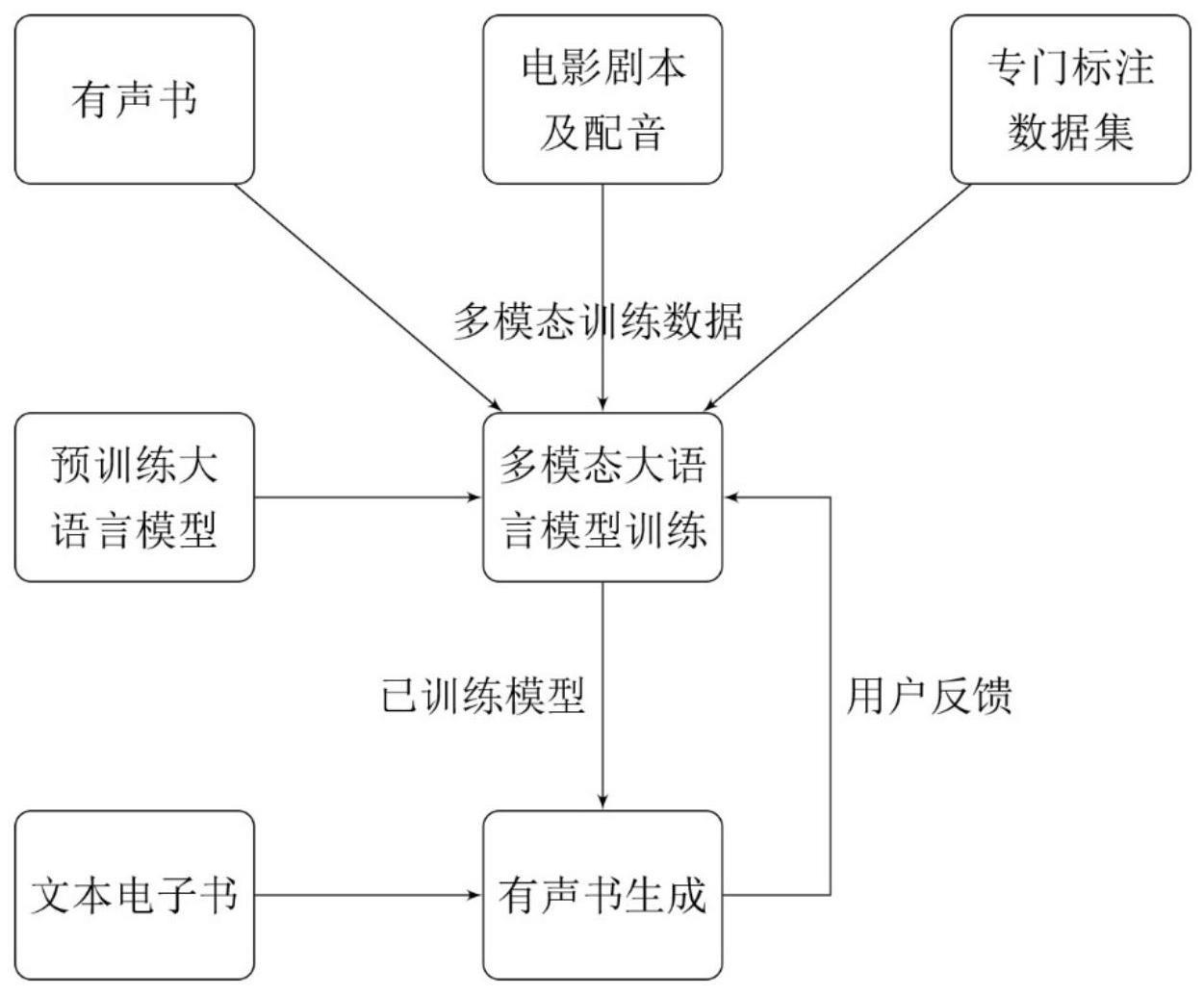
2、7、本发明提供如下技术方案:一种基于大型语言模型的有声书自动生成方法,包括以下步骤:步骤1:训练数据的准备:首先获取多种来源的多模态训练数据,这些来源可以包括现有的电影剧本及配音、有声书以及人工专门注释的数据集,对于人工注释的数据集,人类注释员评估模型生成的声音与其对应角色的匹配程度,对声音在预定的尺度上进行评级,生成监督学习的标签,该数据集被用于提升模型对于声音风格的生成多样性,并将这些声音恰当地匹配至角色;
3、步骤2:模型训练:在获取训练数据后,在预训练好的大语言模型基础上,运用这些数据来训练多模态大语言模型,语言模型根据角色的属性如性别、年龄和性格生成独特的声音和说话风格,模型将输入的文本与相应的声音标签关联起来,进一步学习将角色属性与特定的声音风格联系在一起,模型通过理解文本上下文、识别角色及其属性和情绪,生成相应的独特声音,人类注释员的反馈被用于模型的迭代改进,以增强模型在生成符合角色性质并根据场景和情绪调整声音的能力;
4、步骤3:有声书生成:模型训练完成后,开始从给定的文本中生成有声书,模型处理文本以识别角色、属性和上下文,然后根据之前学习到的知识生成各角色的独特声音,模型会维持上下文的跟踪,并根据不同场景和角色的情绪调整语调、语速和音量,此外,模型根据场景描述生成真实的背景声音;
5、步骤4:用户反馈与持续优化:用户反馈是持续优化生成过程的重要部分,用户对生成的声音、声音一致性和与角色匹配度的反馈可以被纳入训练数据,进一步改进模型,因此,该过程形成了一个生成、反馈和改进的迭代循环,从而提高了自动生成有声书的整体质量和真实感。
6、优选的,每个角色的音调在整本有声书中保持一致。
7、优选的,语言模型根据不同的场景和角色的情绪调整角色的语调、语速和音量。
8、优选的,语言模型根据文本中的场景描述真实地生成背景声音。
9、优选的,语言模型包含现有电影剧本、配音和有声书的数据集上进行训练。
10、优选的,语言模型进一步在特别注释的数据集上训练,该数据集包括生成的声音与其相应角色之间的匹配程度的手动评估,帮助模型学习多样化的声音风格并改进声音与角色的匹配。
11、本发明提出了一种基于多模态大语言模型的有声书自动生成方法,克服了现有解决方案的限制,存在以下的技术效果:
12、1、这种方法利用大语言模型处理和理解文本数据的能力,创建了更细致和真实的有声书体验。语言模型可以根据上下文区分文本中的不同角色,以及他们的性别、年龄、性格等属性,然后,为每个角色生成独特的声音和说话风格;
13、2、此外,语言模型设计成在整个有声书中保持每个角色的音调一致,它通过使用在生成过程中持续存在的内部状态和参数来实现这一点,确保同一个角色总是以相同的声音呈现;
14、3、语言模型还能够根据不同的场景和角色的情绪调整角色的语调、语速和音量。
15、这种动态调整是通过模型对上下文的理解和生成适当的情绪反应来实现的;
16、4、此外,语言模型可以根据文本中的场景描述真实地生成背景声音,它通过学习和生成各种可能的背景声音来实现这一点,根据上下文为每个场景创造最合适的声音。
技术特征:
1.一种基于大型语言模型的有声书自动生成方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于大型语言模型的有声书自动生成方法,其特征在于,每个角色的音调在整本有声书中保持一致。
3.根据权利要求1或2所述的基于大型语言模型的有声书自动生成方法,其特征在于,语言模型根据不同的场景和角色的情绪调整角色的语调、语速和音量。
4.根据权利要求3所述的基于大型语言模型的有声书自动生成方法,其特征在于,语言模型根据文本中的场景描述真实地生成背景声音。
5.根据权利要求4所述的基于大型语言模型的有声书自动生成方法,其特征在于,语言模型包含现有电影剧本、配音和有声书的数据集上进行训练。
6.根据权利要求5所述的基于大型语言模型的有声书自动生成方法,其特征在于,语言模型进一步在特别注释的数据集上训练,该数据集包括生成的声音与其相应角色之间的匹配程度的手动评估,帮助模型学习多样化的声音风格并改进声音与角色的匹配。
技术总结
本发明提出了一种使用多模态大语言模型的有声书自动生成方法,模型生成不同角色的独特声音和说话风格,保持语音音调的一致性,根据场景和情绪调整角色的声音,以及创建真实的背景声音,模型使用现有的电影剧本和配音、有声书以及特别注释的数据集进行训练。
技术研发人员:刘聪,张坤,许莉娟
受保护的技术使用者:盐城工学院
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!