一种基于大数据架构的冠字号码快速入库系统及方法与流程
本发明涉及信息处理,具体而言,尤其涉及一种基于大数据架构的冠字号码快速入库系统及方法。
背景技术:
1、人民币纸币冠字号码是央行人民币印制生产管理控制的措施之一,“冠字”就是印在纸币上用来标记印刷批次的两个或三个字母,由印钞厂按一定规律编排和印刷,“号码”则是指印在冠字后面的阿拉伯数字流水号,用来标明每张钞票在同冠字批次中的排列顺序。
2、目前各商业银行网点、现金中心纸币流通环节以及人行机具监管中,包括纠纷举证查询、纸币清分记录、出入库、冠字号码溯源等业务流程中都会产生大量的业务和冠字号码信息,需要入库且有一定的时效要求。这些数据往往能达到每天上亿条的数据记录,这对传统关系型数据库带来了包括容量和入库速度的极大压力。现有关系型数据库在保证性能的情况下,单表千万条数据记录、gb级容量存储基本上已经达到上限。
技术实现思路
1、有鉴于此,本发明提供了一种基于大数据架构的冠字号码快速入库系统及方法,引入大数据架构包括hadoop、hive等大数据组件,解决了关系型数据库存储上限,实现pb级数据存储;还解决了关系型数据库处理速度上限,采用结构化数据文本csv文件,实现每天不少于1亿条记录的快速入库。
2、为此,本发明采用如下技术方案:
3、本发明提供了一种基于大数据架构的冠字号码快速入库系统,所述系统包括:
4、客户端,用于将业务流程中产生的冠字号码文件以zip文件格式上送至服务器;
5、服务器,基于大数据架构,将整个导入数据的过程进行拆分,每个部分都有独立的线程池管理,通过多线程并发处理的方式,利用hadoop将大量的冠字号码文件存入hive大数据仓库。
6、进一步地,所述服务器在导入数据的过程中,利用关系型数据库存储各种文件信息表。
7、进一步地,整个导入数据的过程拆分为:解压zip文件、解析fsn生成csv文件、导入csv文件。
8、进一步地,服务器中开辟的线程池中开启的线程包括:
9、用于检索发现zip文件并将相关信息写入缓存的监控线程;
10、用于解压从客户端接收到的冠字号码zip文件,得到fsn文件的解压线程;
11、用于解析fsn生成csv文件的解析线程;
12、用于将解析出的csv文件导入hive大数据仓库的批量导入线程。
13、进一步地,所述解压线程的数据处理流程,包括:
14、s11、判断待解析队列当前长度是否大于解压等待阈值;如果是,则继续判断待解析队列当前长度是否大于解压等待阈值;如果否,从缓存中获取zip文件完整路径;
15、s12、验证zip文件是否规范;如果否,则验证失败,zip文件转存到无效文件目录;返回步骤s11;如果是,则验证成功,添加zip文件信息到关系型数据库zip文件信息表;
16、s13、解压zip文件到待解析路径下得到fsn文件;
17、s14、添加fsn文件信息到关系型数据库fsn文件信息表;
18、s15、添加fsn文件信息到待解析队列;
19、s16、删除zip文件,删除关系型数据库zip文件信息表中该条记录。
20、进一步地,所述解析线程的数据处理流程,包括:
21、s21:解析线程从待解析队列中获取fsn文件信息,验证fsn文件规范性;
22、s22:解析fsn文件,把业务信息写入关系型数据库业务表;
23、s23:将单位时段解析的所有冠字号码明细写入多个设定大小的csv文件;
24、s24:更新关系型数据库fsn文件解析入库信息表,添加csv信息到批量导入信息表。
25、进一步地,所述批量导入线程的数据处理流程,包括:
26、s31:从关系型数据库批量导入信息表获取状态为待导入状态的记录;
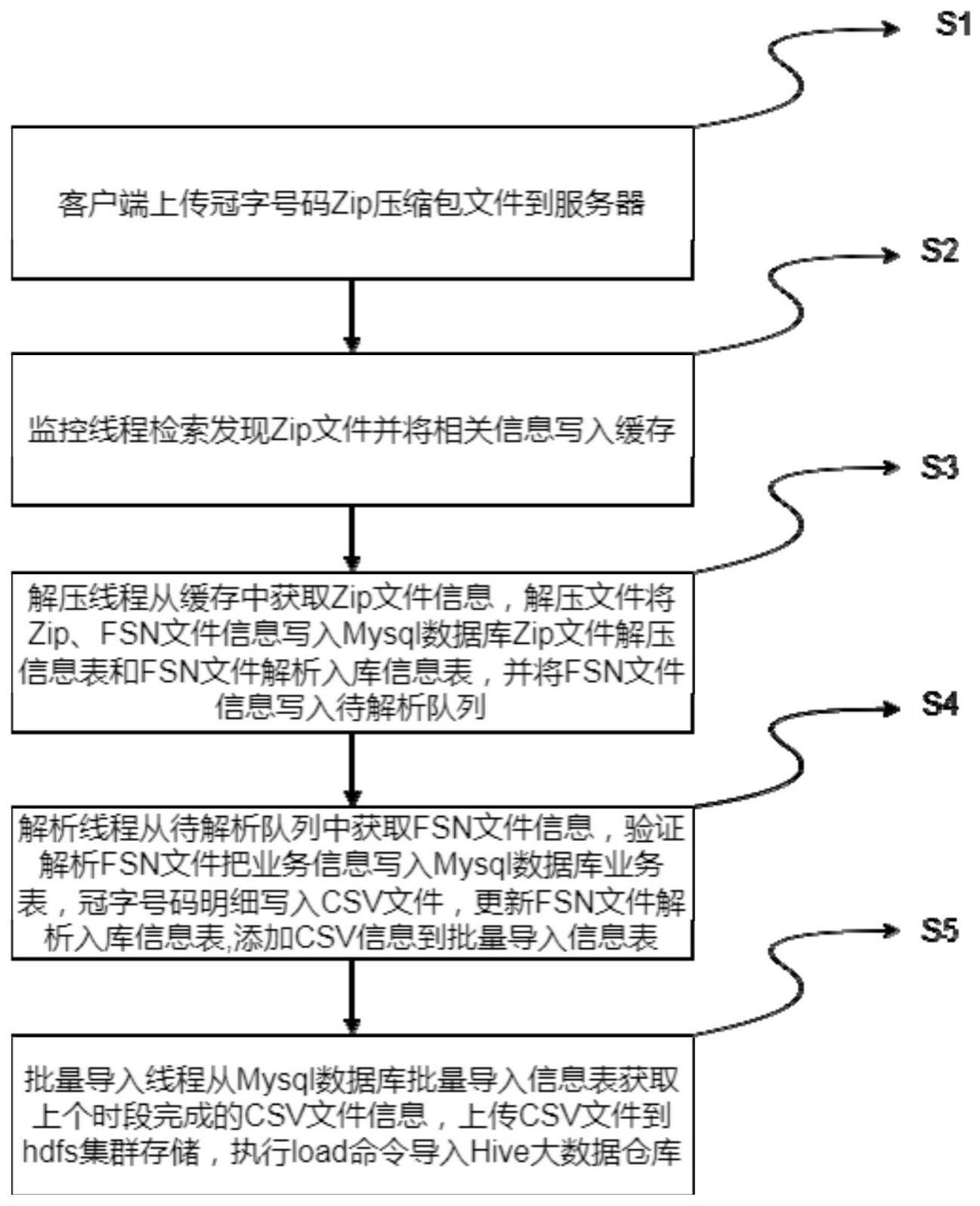
27、s32:更新关系型数据库csv文件信息表,该条记录导入状态为导入中;
28、s33:查询csv关联的zip、fsn文件是否有失败的记录;如果有,更新关系型数据库csv文件信息表,该条记录导入状态为失败;如果没有,则上传csv文件到hadoop集群成功;
29、s34:判断是否上传成功,若上传不成功,则更新关系型数据库csv文件信息表,该条记录导入状态为失败;若上传成功,则运行hive导入指令;并判断导入hive是否成功,如果成功,则更新关系型数据库csv文件信息表,该条记录导入状态为导入成功;删除当前导入的csv文件。
30、进一步地,所述客户端和所述服务器之间通过ftp、sftp、tcp中的一种或多种方式进行文件传输。
31、本发明还提供了一种基于大数据架构的冠字号码快速入库方法,包括如下步骤:
32、s1:服务器接收客户端上送的冠字号码zip文件;
33、s2:监控线程检索发现zip文件并将相关信息写入缓存;
34、s3:解压线程从缓存中获取zip文件信息,验证zip文件规范性;解压zip文件将zip、fsn文件信息写入关系型数据库zip文件解压信息表和fsn文件解析入库信息表,并将fsn文件信息写入待解析队列;
35、s4:解析线程从待解析队列中获取fsn文件信息,验证fsn文件规范性;解析fsn文件,把业务信息写入关系型数据库业务表;将单位时段解析的所有冠字号码明细写入多个设定大小的csv文件;更新关系型数据库fsn文件解析入库信息表,添加csv信息到批量导入信息表;
36、s5、批量导入线程从关系型数据库批量导入信息表获取上个时段完成的csv文件信息;查询zip文件信息表和fsn文件信息表,验证csv文件关联的fsn、zip文件解压和解析入库状态,状态正常,则执行导入,有异常状态,则更新批量导入信息表,该条记录为异常状态;上传csv文件到hadoop集群存储,执行导入命令导入hive大数据仓库。
37、进一步地,所述监控线程完成一次zip文件存储路径检索、开启监听器监视文件上传情况,后续文件发现交由监听器完成。
38、较现有技术相比,本发明具有以下优点:
39、本发明中,将整个导入数据的过程进行拆分,分为解压zip文件、解析fsn生成csv文件、导入csv文件多个部分,每个部分都有独立的线程池管理。可开启多线程并发处理。线程数可根据服务器的配置自行设置,充分利用服务器的性能。
40、本发明中,在单位时间内生成结构化csv文件,单位时间可根据实际情况进行配置,比如每分、每小时。根据单位时间内的数据量决定是否生成多个csv文件,控制csv文件的大小,提高上传hdfs及导入的效率。
41、本发明中,结构化的csv文件使数据导入的速度得到提升。数据入库速度的提升能保证数据能够快速的处理完成,及时反馈给客户进行查询,也方便统计类功能的执行。
技术特征:
1.一种基于大数据架构的冠字号码快速入库系统,其特征在于,所述系统包括:
2.根据权利要求1所述的基于大数据架构的冠字号码快速入库系统,其特征在于,所述服务器在导入数据的过程中,利用关系型数据库存储各种文件信息表。
3.根据权利要求1所述的基于大数据架构的冠字号码快速入库系统,其特征在于,整个导入数据的过程拆分为:解压zip文件、解析fsn生成csv文件、导入csv文件。
4.根据权利要求3所述的基于大数据架构的冠字号码快速入库系统,其特征在于,服务器中开辟的线程池中开启的线程包括:
5.根据权利要求4所述的基于大数据架构的冠字号码快速入库系统,其特征在于,所述解压线程的数据处理流程,包括:
6.根据权利要求5所述的基于大数据架构的冠字号码快速入库系统,其特征在于,所述解析线程的数据处理流程,包括:
7.根据权利要求6所述的基于大数据架构的冠字号码快速入库系统,其特征在于,所述批量导入线程的数据处理流程,包括:
8.根据权利要求1所述的基于大数据架构的冠字号码快速入库系统,其特征在于,所述客户端和所述服务器之间通过ftp、sftp、tcp中的一种或多种方式进行文件传输。
9.一种基于大数据架构的冠字号码快速入库方法,其特征在于,包括如下步骤:
10.根据权利要求9所述的基于大数据架构的冠字号码快速入库方法,其特征在于,所述监控线程完成一次zip文件存储路径检索、开启监听器监视文件上传情况,后续文件发现交由监听器完成。
技术总结
本发明公开了一种基于大数据架构的冠字号码快速入库系统及方法,系统包括:客户端,用于将业务流程中产生的冠字号码文件以ZIP文件格式上送至服务器;服务器,基于大数据架构,将整个导入数据的过程进行拆分,每个部分都有独立的线程池管理,通过多线程并发处理的方式,利用Hadoop将大量的冠字号码文件存入Hive大数据仓库。本发明中引入大数据架构包括Hadoop、Hive等大数据组件,解决了关系型数据库存储上限,实现PB级数据存储;还解决了关系型数据库处理速度上限,采用结构化数据文本CSV文件,实现每天不少于1亿条记录的快速入库。
技术研发人员:黄政,蔡振,孙晓旭,马诚,徐瀚博,谢忠泉,马鑫,赵崇翰,崔凯,胡健胜,于淼,黄殿明,王介生
受保护的技术使用者:聚龙股份有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!