本发明涉及虚拟试衣,具体是指一种基于扩散模型的虚拟试衣方法。
背景技术:
1、在互联网技术的深度发展下,网络购物已经渗入人们的生活。在改变人们生活方式的同时,也降低了消费者们的购物体验。应运而生的虚拟试衣技术的发展提高顾客的网上购衣体验,同时减少商家的退货率,节约了成本。
2、目前主流的虚拟试衣技术主要是通过深度学习的二维图像生成算法实现的。主要分为两种,一种是基于生成对抗网络的方法,但是这种方法只能粗略地转换对象类和属性等信息,无法生成图形细节和适应几何变化,实际训练过程中,生成器和判别器之间常常不能产生很好的同步,容易判别器收敛,生成器发散,其训练稳定性差容易出现模式崩溃。另一种是基于两阶段试穿网络的方法,采用由粗到细框架,使用薄板样条插值将目标服装根据人体信息进行扭曲,然后将扭曲后的服装与人体合成在一起,这种方法生成的肢体会产生严重遮挡,生成效果不佳。
技术实现思路
1、本发明的目的是提供一种基于扩散模型的虚拟试衣图像生成方法,提升训练效果的稳定性,有效解决肢体部分产生严重遮挡的问题。
2、为解决上述技术问题,本发明提供的技术方案为:一种基于扩散模型的虚拟试衣方法,包括以下步骤,
3、步骤1、获取二维人体图像和目标衣物;
4、步骤2、提取二维人体图像的人体解析信息、人体骨骼姿态图、人体语义分割图;依据人体解析信息,对目标衣物进行扭曲,生成扭曲服装;依据人体骨骼姿态图、人体语义分割图生成手臂与换衣区域的掩码图像;
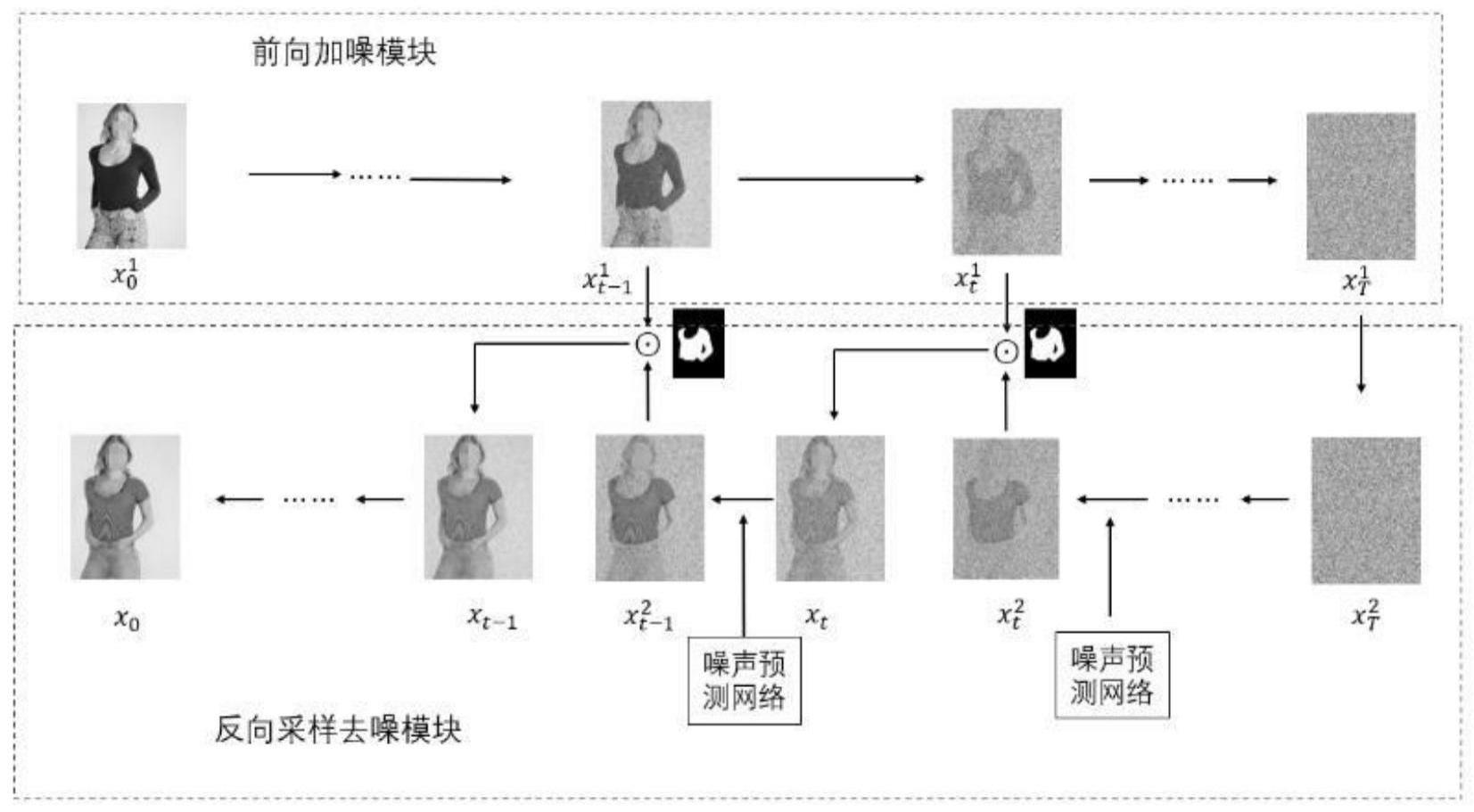
5、步骤3、将二维人体图像送入扩散模型的前向加噪模块,逐步对二维人体图像加噪声,获取第t步的噪声图;
6、步骤4、将第t步的噪声图送入反向采样去噪模块,以扭曲服装和人体骨骼姿态图为条件引导生成试衣合成预测噪声图;
7、步骤5、通过掩码图像将试衣合成预测噪声图与相对应步骤的前向加噪模块的噪声图融合,获取融合噪声图;逐步去噪声,获取成最终的试衣合成图。
8、进一步的,所述二维人体图像为需要试穿目标衣物的人的图,该图像中的人的正面特征应保留完整;所述目标衣物为二维人体图像中的人需要试穿的衣服的图像,该图像需要保留衣服的清晰的纹理以及完整的衣物形状特征。
9、进一步的,所述人体解析信息包括脸和头发、体型以及姿势热图;
10、所述脸和头发由3通道的rgb图像组成,包含脸部和头发部分,体现身份信息,在试衣过程中不会发生改变;
11、所述体型由1通道的二值化掩码组成,人体区域用1表示,其他部分用0表示;为排除不同服装对掩码形状的影响,先将掩码进行下采样到较低的分辨率,再通过上采样恢复原先的分辨率,获得模糊的掩码粗略地覆盖人体;
12、所述姿势热图由18个人体关键点表示,为了利用姿势的空间布局,关键点被转换成18通道的姿势热图。
13、进一步的,所述人体语义分割图根据人体图像的语义信息生成,所述人体图像语义信息包括人体衣服语义、身体部分语义、头发和脸部语义、裤子语义。
14、进一步的,所述人体骨骼姿态图使用开源的openpose骨架提取网络提取人的关键点坐标数据进行姿态估计得到。
15、进一步的,扭曲服装的方法如下:
16、将目标衣物和人体解析信息输入服装扭曲模块,分别将目标衣物和人体解析信息输入两个由步长为2的卷积层组成的编码器来提取特征,再通过特征匹配将两组特征融合,送入回归网络,预测50个薄板样条插值转换参数θ,并用θ计算出扭曲后拟合人体的扭曲服装。
17、进一步的,掩码图像的生成方法如下:
18、人体语义分割图用于生成换衣区域的掩码,人体骨骼姿态图用于生成手臂部分的掩码,其中手臂部分掩码生成不包括手的部分;将两部分的掩码合成得到换衣区域与手臂生成区域的掩码图像。
19、进一步的,所述前向加噪模块对输入图片引入一系列随机高斯噪声来破坏训练数据,对数据图像分t步添加高斯噪声,进行逐步噪声化,图像在这一过程中会逐渐变为纯高斯噪声。
20、进一步的,所述反向采样去噪模块将噪声从目标分布转化回样本,通过学习反转这个噪声过程来恢复数据。
21、进一步的,逐步去噪声,获取成最终的试衣合成图的方法如下:
22、以扭曲服装和人体骨骼姿态图为条件引导生成试衣合成预测噪声图,提取前向过程对应步骤的噪声图,使用掩码将两个对应阶段的噪声图混合,将混合生成的融合噪声图送入下一个噪声预测网络,重复这一过程,最终生成试衣合成图。
23、本发明与现有技术相比的优点在于:本发明采用扩散模型克服生成对抗网络固有的缺点,有效解决肢体部分产生严重遮挡的问题,提升训练效果的稳定性,产生良好的试衣效果。
技术特征:1.一种基于扩散模型的虚拟试衣方法,其特征在于:包括以下步骤,
2.根据权利要求1所述的一种基于扩散模型的虚拟试衣方法,其特征在于:所述二维人体图像为需要试穿目标衣物的人的图,该图像中的人的正面特征应保留完整;所述目标衣物为二维人体图像中的人需要试穿的衣服的图像,该图像需要保留衣服的清晰的纹理以及完整的衣物形状特征。
3.根据权利要求2所述的一种基于扩散模型的虚拟试衣方法,其特征在于:所述人体解析信息包括脸和头发、体型以及姿势热图;
4.根据权利要求3所述的一种基于扩散模型的虚拟试衣方法,其特征在于:所述人体语义分割图根据人体图像的语义信息生成,所述人体图像语义信息包括人体衣服语义、身体部分语义、头发和脸部语义、裤子语义。
5.根据权利要求4所述的一种基于扩散模型的虚拟试衣方法,其特征在于:所述人体骨骼姿态图使用开源的openpose骨架提取网络提取人的关键点坐标数据进行姿态估计得到。
6.根据权利要求5所述的一种基于扩散模型的虚拟试衣方法,其特征在于:扭曲服装的方法如下:
7.根据权利要求6所述的一种基于扩散模型的虚拟试衣方法,其特征在于:掩码图像的生成方法如下:
8.根据权利要求7所述的一种基于扩散模型的虚拟试衣方法,其特征在于:所述前向加噪模块对输入图片引入一系列随机高斯噪声来破坏训练数据,对数据图像分t步添加高斯噪声,进行逐步噪声化,图像在这一过程中会逐渐变为纯高斯噪声。
9.根据权利要求8所述的一种基于扩散模型的虚拟试衣方法,其特征在于:所述反向采样去噪模块将噪声从目标分布转化回样本,通过学习反转这个噪声过程来恢复数据。
10.根据权利要求9所述的一种基于扩散模型的虚拟试衣方法,其特征在于:逐步去噪声,获取成最终的试衣合成图的方法如下:
技术总结本发明公开了一种基于扩散模型的虚拟试衣方法,首先获取二维人体图像和目标衣物;然后提取二维人体图像信息;对目标衣物进行扭曲,生成扭曲服装;生成手臂与换衣区域的掩码图像;逐步对二维人体图像加噪声,获取第T步的噪声图;将第T步的噪声图送入反向采样去噪模块,以扭曲服装和人体骨骼姿态图为条件引导生成试衣合成预测噪声图;通过掩码图像将试衣合成预测噪声图与相对应步骤的前向加噪模块的噪声图融合,获取融合噪声图;逐步去噪声,获取成最终的试衣合成图。本发明采用扩散模型克服生成对抗网络固有的缺点,有效解决肢体部分产生严重遮挡的问题,提升训练效果的稳定性,产生良好的试衣效果。
技术研发人员:黄明,钱丽丹,李吉,朱东辉,张舒,朱旭,吴禹志,藏福星,黄小杰,蒋鑫
受保护的技术使用者:江苏理工学院
技术研发日:技术公布日:2024/1/16