一种利用PDF文本获取训练数据的方法、装置及电子设备与流程
本发明涉及文本检测,尤其涉及一种利用pdf文本获取训练数据的方法、装置及电子设备。
背景技术:
1、数据是人工智能发展的基础,文本检测与文本识别任务等都需要庞大的数据支撑下去进行模型训练。近些年来,基于弱监督学习和无监督学习的模型发展迅速,但基于训练样本有明确标签或结果的监督学习仍然是一种主要的模型训练方式。尤其是在ocr领域,需要更多高质量的训练数据以提升模型效果。
2、对于大部分的企业开发者,特别是在不同语种的文本检测与识别任务中,则更需要利用专业领域的实际业务数据定制ai模型应用,以保证其能够更好地应用在业务中。
3、目前文本图像数据标注主要有两种方式,一种为纯人工的标注方式,由标注人员手动将图像中的文本区域标注出来,并转写出该文本区域的文本内容。另一种则使用文本检测和识别模型对未标注的数据进行预标注,在由人工去修改由模型自动标注的结果。
4、而采用训练好的文本检测模型或文本识别模型去对新的文本图像数据进行标注,虽然可以提高数据标注的速度,但由于模型的泛化性不足,导致自动标注出的文本区域往往会出现错误,人工再去纠正也会消耗大量的时间,人工成本并没有大幅度的降低。
技术实现思路
1、本发明提供一种利用pdf文本获取训练数据的方法、装置及电子设备,其通过对可解析的pdf文件进行拆分,并利用每个字符的坐标信息构件、词单元和行单元,以实现对pdf文件中各项数据的快速拆分,以此作为文本检测深度学习的训练数据进行使用。
2、第一方面,本发明提供一种利用pdf文本获取训练数据的方法,其包括以下步骤:
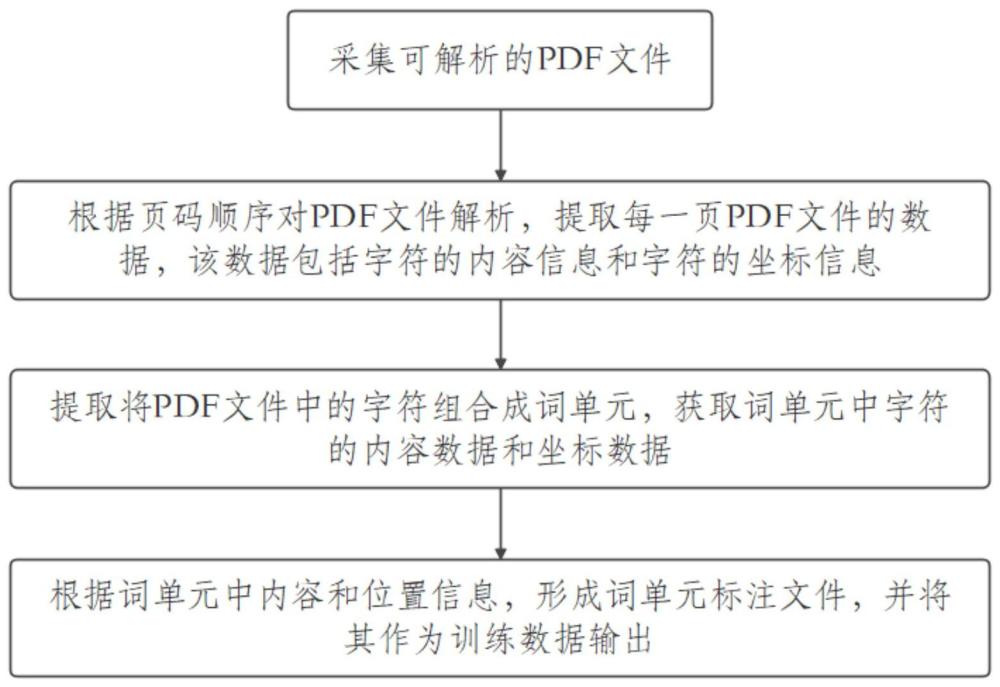
3、s100:采集可解析的pdf文件;
4、s200:根据页码顺序对pdf文件解析,提取每一页pdf文件的数据,该数据包括字符的内容信息和字符的坐标信息
5、s300:提取将pdf文件中的字符组合成词单元,获取词单元中字符的内容数据和坐标数据;
6、在步骤s300中,获取组合形成词单元和具体包括以下步骤:
7、s301:计算词单元中每个字符的纵坐标的最大值和最小值和横坐标的最大值和最小值,并利用这四个最值构建一个矩形框;
8、s302:根据所述矩形框的坐标,得到词单元的坐标;
9、s303:将词单元的坐标与每个字符的内容信息进行结合,构建出所述词单元的内容和位置信息;
10、s400:根据步骤s303中的词单元中内容和位置信息,形成词单元标注文件,并将其作为训练数据输出。
11、根据本发明提供的一种利用pdf文本获取训练数据的方法,在步骤s300中,还包括以下步骤:
12、整理多个所述词单元,并获取每个词单元的矩形框的纵坐标;
13、将多个纵坐标相同的词单元组合成一行,构成行单元;
14、再将每个词单元中的内容组合至所述行单元中,形成行单元标注文件,同时作为可输出的训练数据。
15、根据本发明提供的一种利用pdf文本获取训练数据的方法,在步骤s300中,还包括以下步骤:
16、若所述词单元中存在空白处,将该空白处作为分隔符进行提取。
17、根据本发明提供的一种利用pdf文本获取训练数据的方法,所述词单元所形成的矩形框至少一个包括字符。
18、根据本发明提供的一种利用pdf文本获取训练数据的方法,在步骤s200中,还包括以下步骤:
19、根据页码将pdf拆卸成多份,并转换呈将其图片,并输出转换后的图片,作为图片的训练数据。
20、根据本发明提供的一种利用pdf文本获取训练数据的方法,将所述图片数据和所述词单元标准文件进行混合,共同作为训练数据输出。
21、根据本发明提供的一种利用pdf文本获取训练数据的方法,将所述图片数据和所述行单元的标准文件进行混合,共同作为训练数据输出。
22、根据本发明提供的一种利用pdf文本获取训练数据的方法,在步骤s100中,可利用所述pdf识别模块判断所述pdf文件是否为可解析的pdf文件。
23、第二方面,本发明还提供一种利用pdf文本获取训练数据的方法装置,其包括pdf文件识别模块、pdf文件处理模块和输出模块;
24、所述pdf文件识别模块与所述pdf文件处理模块电连接,用于识别可解析的pdf文件,并将其传输至所述pdf处理模块中,使所述pdf处理模块对可解析的pdf文件进行处理,最后通过与其电连接的输出模块输出到外部,作为训练数据。
25、第三方面,本发明还提供了一种电子设备,其包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述利用pdf文本获取训练数据的方法的步骤。
26、第四方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述利用pdf文本获取训练数据的方法的步骤。
27、本发明提供的利用pdf文本获取训练数据的方法、装置及电子设备,其通过对可解析的pdf文件进行处理,先将pdf文件根据页码拆卸成多份,然后再通过构建词单元或行单元的方式,获取词单元或行单元的坐标信息和字符信息,同时将拆解后的pdf文件转换成图片数据,共同作为训练数据进行输出,以实现快速且准确的pdf文件中字符数据的采集作业,具有良好的实用价值与应用前景。
技术特征:
1.一种利用pdf文本获取训练数据的方法,其特征在于,其包括以下步骤:
2.根据权利要求1所述的利用pdf文本获取训练数据的方法,其特征在于,在步骤s300中,还包括以下步骤:
3.根据权利要求1所述的利用pdf文本获取训练数据的方法,其特征在于,在步骤s300中,还包括以下步骤:
4.根据权利要求1所述的利用pdf文本获取训练数据的方法,其特征在于,所述词单元所形成的矩形框至少一个包括字符。
5.根据权利要求1~4中任一项所述的利用pdf文本获取训练数据的方法,其特征在于,在步骤s200中,还包括以下步骤:
6.根据权利要求5所述的利用pdf文本获取训练数据的方法,其特征在于,将所述图片数据和所述词单元标注文件进行混合,共同作为训练数据输出。
7.根据权利要求5所述的利用pdf文本获取训练数据的方法,其特征在于,将所述图片数据和行单元标注文件进行混合,共同作为训练数据输出。
8.根据权利要求1所述的利用pdf文本获取训练数据的方法,其特征在于,在步骤s100中,可利用所述pdf识别模块判断所述pdf文件是否为可解析的pdf文件。
9.一种利用pdf文本获取训练数据的方法装置,其特征在于,包括:其包括pdf文件识别模块、pdf文件处理模块和输出模块;
10.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至8任一项所述利用pdf文本获取训练数据的方法的步骤。
技术总结
本发明提供一种利用PDF文本获取训练数据的方法、装置及电子设备,其包括以下步骤,采集可解析的PDF文件,根据页码顺序对PDF文件解析,提取每一页PDF文件的数据,再提取PDF文件中的字符组合成词单元,将词单元的坐标与每个字符的内容信息进行结合,构建出词单元的内容和位置信息,并将其作为训练数据输出。本发明提供一种利用PDF文本获取训练数据的方法、装置及电子设备,其通过对可解析的PDF文件进行处理,先将PDF文件根据页码拆卸成多份,然后再通过构建词单元方式,获取词单元或行单元的坐标和字符信息,同时将拆解后的PDF文件转换成图片数据,共同作为训练数据进行输出,实现快速且准确的PDF文件中字符数据的采集作业,具有良好的实用价值与应用前景。
技术研发人员:邓彪,翟飞飞,李庚尧
受保护的技术使用者:北京中科凡语科技有限公司
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!