基于NVDIMM的分布式并行存储系统及数据写入方法与流程
本发明涉及前端开发,特别是涉及一种基于nvdimm的分布式并行存储系统及数据写入方法。
背景技术:
1、随着云计算、大数据、人工智能和物联网等基础信息技术的快速发展和广泛应用,生物工程、基因测序、天气预报、气象预测和卫星遥感等场景对于高性能计算技术提出了越来越高的要求。存储系统是高性能计算的主要支撑系统之一,它对于提高超级计算机在科技领域的应用效果具有决定性的作用。
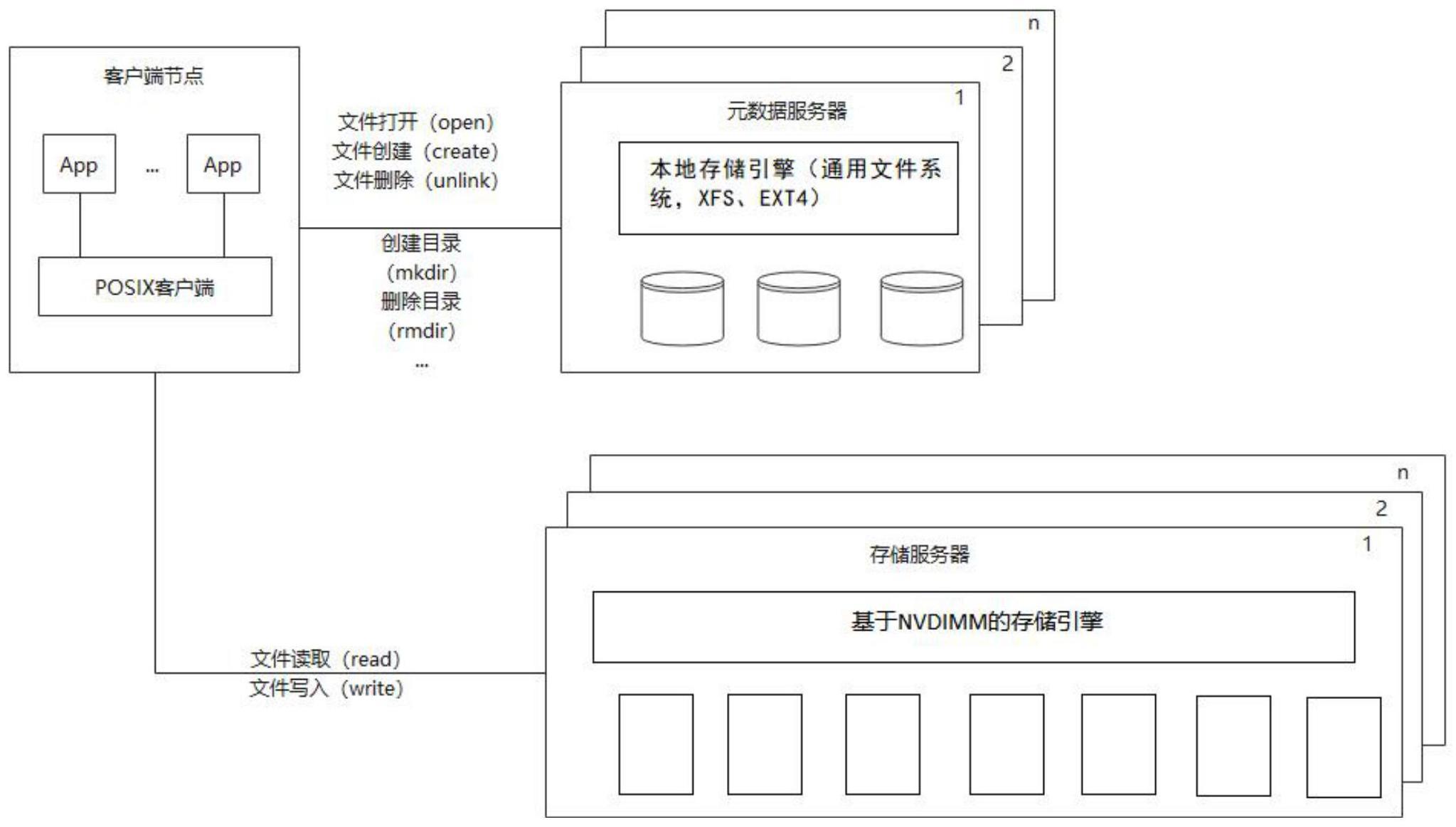
2、分布式并行文件系统是存储系统的重要组成部分。传统的分布式并行文件系统主要面向hdd、ssd等中低速介质设计,其主要设计目标为通过数据条带化以及多节点并行访问的方式,提高分布式系统的带宽能力,对于大量小文件的读写性能未进行专门调校。如图1所示,传统的分布式并行文件系统的存储服务器在存储引擎上采用针对块设备设计的本地存储服务器,如ext4、xfs等,这类本地存储服务器的io软件栈较复杂,语义严苛,导致其软件栈的访问路径较长,且对于大量文件小io的处理能力不高,系统整体延迟增大。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种基于nvdimm的分布式并行存储系统及其数据写入方法,消除了文件系统树状结构的复杂设计,缩短了软件栈的访问路径,提高了数据读写速率尤其是随机io的性能。
2、第一方面,本发明提供了一种基于nvdimm的分布式并行存储系统,系统包括:客户端模块,多个元数据服务器和多个存储服务器,元数据服务器和存储服务器均与客户端模块通过接口连接;
3、每个存储服务器由用于将客户端的文件存储为nvdimm型数据的基于nvdimm的存储引擎和多个用于存储nvdimm型数据的nvdimm存储介质构成;
4、基于nvdimm的存储引擎通过接口与客户端模块连接。
5、在其中一个实施例中,nvdimm型数据的数据结构从左至右依次包括:
6、超级块,超级块用于记录基于nvdimm的存储引擎的入口信息以及指向索引节点已使用链表指针、索引节点空闲链表指针、指向数据块空闲链表的指针以及指向块管理哈希表的指针;
7、索引节点,索引节点用于记录文件的基本信息;
8、块管理区,块管理区用于对数据进行管理;
9、数据块区,数据块区用于存放数据。
10、在其中一个实施例中,基于nvdimm的存储引擎的入口信息包括nvdimm型数据的数据结构中的块大小、总块数和空闲块数。
11、在其中一个实施例中,索引节点包括文件id、文件大小和索引节点编号。
12、在其中一个实施例中,块管理区包括文件id、文件块逻辑编号和文件块物理编号。
13、在其中一个实施例中,索引节点在nvdimm型数据的数据结构中占总数据块的比例小于5%;
14、空闲的索引节点以链表的形式串联。
15、在其中一个实施例中,存储服务器与客户端模块之间的接口包括读取接口和写入接口。
16、第二方面,本发明还提供了一种数据写入方法,采用上述的基于nvdimm的分布式并行存储系统进行,用于将客户端的文件数据写入nvdimm存储介质,包括以下步骤:
17、根据客户端传入的文件id在索引节点已使用链表中遍历查找文件,若未查找到,在索引节点空闲链表指针中取一个节点,分配给传入的文件,并将取得的节点插入索引节点已使用链表,若查找到,进入下一步骤;
18、根据传入的文件id、文件写入偏移和文件写入长度计算传入的文件在块管理哈希表中的位置;
19、根据传入的文件在块管理哈希表中的位置查找是否存在对应的文件id和文件偏移在文件中的逻辑块编号,若存在,传入的文件数据块空间已分配,否则,在数据块空闲链表中取一个节点,分配节点对应的物理编号给块管理哈希表;
20、根据物理编号和整个nvdimm存储介质中数据块区所在位置,获得传入的文件的实际物理地址;
21、向实际物理地址中写入长为length长度的字节;
22、将文件写入偏移递增length,将待写入值递减length,判断递减后的值是否大于0,若是,返回根据传入的文件id、写入偏移和写入长度计算传入的文件在块管理哈希表中的位置的步骤,否则,数据写入完成。
23、在其中一个实施例中,根据传入的文件id、文件写入偏移和文件写入长度计算传入的文件在块管理哈希表中的位置的计算式为:
24、
25、key=file_id+logic_idx
26、hash_idx=hash_fn(key)%hash_count
27、式中,logic_idx为计算出来文件偏移在文件中的逻辑块编号,key为哈希表主键,hash_count是预设的哈希表能容纳的元素个数,hash_fn为选定的哈希算法,hash_idx为通过哈希计算得到的元素存储位置索引,表示传入的文件在块管理哈希表中的位置。
28、在其中一个实施例中,偏移递增length的计算式为:
29、length=min(count,block_size)
30、式中,count为待写入长度,block_size为数据块大小。
31、本发明的有益效果:
32、(1)本发明的nvdimm实质上为dram,采用应用直接访问存储介质的模式,以字节寻址方式访问,绕过操作系统缓存,数据直达nvdimm存储介质,消除了文件系统树状结构的复杂设计,缩短了软件栈的访问路径,能够显著提高数据尤其是随机io的性能访问效率,进而提升数据的读写效率。
33、(2)本发明的nvdimm型数据的数据结构,组织关系非常简练,没有任何目录层级,文件仅体现在内存层面,减轻了系统的负担,提高了系统的运行效率。
技术特征:
1.一种基于nvdimm的分布式并行存储系统,其特征在于,所述系统包括:客户端模块,多个元数据服务器和多个存储服务器,所述元数据服务器和存储服务器均与所述客户端模块通过接口连接;
2.根据权利要求1所述的基于nvdimm的分布式并行存储系统,其特征在于,所述nvdimm型数据的数据结构从左至右依次包括:
3.根据权利要求2所述的基于nvdimm的分布式并行存储系统,其特征在于,所述基于nvdimm的存储引擎的入口信息包括nvdimm型数据的数据结构中的块大小、总块数和空闲块数。
4.根据权利要求2所述的基于nvdimm的分布式并行存储系统,其特征在于,所述索引节点包括文件id、文件大小和索引节点编号。
5.根据权利要求2所述的基于nvdimm的分布式并行存储系统,其特征在于,所述块管理区包括文件id、文件块逻辑编号和文件块物理编号。
6.根据权利要求2所述的基于nvdimm的分布式并行存储系统,其特征在于,所述索引节点在nvdimm型数据的数据结构中占总数据块的比例小于5%;
7.根据权利要求2至6任意一项所述的基于nvdimm的分布式并行存储系统,其特征在于,所述存储服务器与客户端模块之间的接口包括读取接口和写入接口。
8.一种数据写入方法,采用如权利要求1至7任意一项所述的基于nvdimm的分布式并行存储系统进行,其特征在于,用于将客户端的文件数据写入nvdimm存储介质,包括以下步骤:
9.根据权利要求8所述的数据写入方法,其特征在于,根据传入的文件id、文件写入偏移和文件写入长度计算传入的文件在块管理哈希表中的位置的计算式为:
10.根据权利要求8所述的数据写入方法,其特征在于,偏移递增length的计算式为:
技术总结
本发明公开了一种基于NVDIMM的分布式并行存储系统及数据读写方法,系统包括:客户端模块,多个元数据服务器和多个存储服务器,元数据服务器和存储服务器均与客户端模块通过接口连接,每个存储服务器由用于将客户端的文件存储为NVDIMM型数据的基于NVDIMM的存储引擎和多个用于存储NVDIMM型数据的NVDIMM存储介质构成,基于NVDIMM的存储引擎通过接口与客户端模块连接。本发明消除了文件系统树状结构的复杂设计,缩短了软件栈的访问路径,提高了数据读写速率尤其是随机IO的性能。
技术研发人员:曹庭华,刘卫乾,范园利
受保护的技术使用者:西安奥卡云数据科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!