水文数据的处理方法、系统及可读存储介质与流程
本发明属于水文水利数据治理,具体涉及一种水文数据的处理方法、系统及可读存储介质。
背景技术:
1、水文水利数据统一平台系统实现了江河湖库的雨量、水位、水温、流速、流量、蒸发等水文要素数据的自动化监测,为安全管理与运行调度提供及时有效的信息,及时预警,提高管理的效率和质量。
2、在实时监测过程中,由于信号、环境、天气等情况,监测的水文数据难免会出现数值错误、数据缺失等异常情况。随着水利信息化水平的不断提高,现有的异常检测算法对于水文数据表现出的季节性、随机性以及时空相关性等复杂特性处理不够充分,所以在异常检测的精度上还存在较大的提升空间。另外,对于异常情况下数据的修复也是当前亟需解决的难题。
技术实现思路
1、基于现有技术中存在的上述缺点和不足,本发明的目的之一是至少解决现有技术中存在的上述问题之一或多个,换言之,本发明的目的之一是提供满足前述需求之一或多个的一种水文数据的处理方法、系统及可读存储介质。
2、为了达到上述发明目的,本发明采用以下技术方案:
3、一种水文数据的处理方法,包括以下步骤:
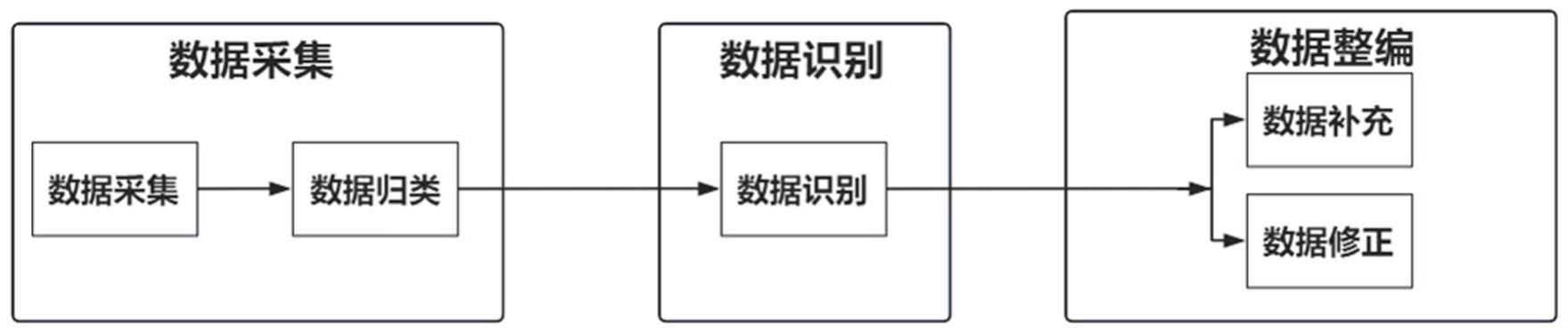
4、s1、采集水文数据并进行数据校验,判断数据校验是否通过;若否,则对校验不通过的异常数据序列进行步骤s2的处理;
5、s2、利用one-class svm模型对异常数据序列的数据点进行异常检测,得到第一指标值;
6、分别利用ewma算法、cof算法、isolation forest算法对异常数据序列的数据点进行异常检测,并结合各算法的权重对异常检测结果求和得到第二指标值;
7、将数据点对应的历年数据输入lstm模型得到拟合值,基于拟合值与异常数据序列的方差确定异常数据点,得到第三指标值;
8、s3、将第一指标值、第二指标值和第三指标值作为观测值输入隐马尔可夫模型进行识别,得到目标异常数据点。
9、作为优选方案,所述步骤s1中,采集水文数据之后进行数据分类,划分为要素数据和工况数据;
10、要素数据包括水位、雨量、流量、蒸发量中的至少一种;
11、工况数据包括电源电压、信号强度、温度中的至少一种。
12、作为优选方案,所述步骤s2中,基于拟合值与异常数据序列的方差确定异常数据点,包括:
13、基于拟合值与异常数据序列的方差构建数据值的上限 max和下限 min:
14、;
15、其中, value lstm为拟合值, variance为异常数据序列的方差, k为常量;
16、若数据点的数据值超出上限 max或下限 min,则数据点为异常数据点并输出相应的标签作为第三指标值。
17、作为优选方案,所述数据点的异常类型包括数据值突变和数据值缺失。
18、作为优选方案,水文数据的处理方法,还包括以下步骤:
19、s4、判断目标异常数据点在异常数据序列中的占比是否超出预设阈值;若否,则对目标异常数据点进行自适应时序整编;若是,则对目标异常数据点进行异常整编。
20、作为优选方案,所述对目标异常数据点进行自适应时序整编,包括以下步骤:
21、s41、对异常数据序列进行adf检验;若检验通过,则转至步骤s42;若检验不通过,则对异常数据序列进行一次差分之后再进行adf检验;
22、s42、判断异常数据序列是否有周期性;如是,则对目标异常数据点进行周期性整编;若否,则对目标异常数据点进行趋势性整编。
23、作为优选方案,所述周期性整编包括:
24、将目标异常数据点分别进行三次指数平滑预测和gm(2,1)预测,并对预测结果取加权平均,得到整编后的数据点;
25、所述趋势性整编包括:
26、将目标异常数据点分别进行arima预测和gm(1,1)预测,并对预测结果取加权平均,得到整编后的数据点。
27、作为优选方案,所述对目标异常数据点进行异常整编包括以下步骤:
28、判断目标异常数据点的类型为数据值突变或数据值缺失;
29、若为数据值缺失,则利用目标异常数据点输入lstm模型得到的拟合值作为整编后的数据点;
30、若为数据值突变,则利用knn算法对异常数据序列的所有数据点进行聚类,选取目标异常数据点前后 n个数据点作为目标数据点,确定包含目标数据点数量最多的簇作为目标簇,计算各目标数据点至目标簇中心的距离并取均值,利用均值对目标异常数据点进行整编;其中, n为大于1的整数。
31、本发明还提供一种水文数据的处理系统,应用如上方案所述的水文数据的处理方法,所述水文数据的处理系统包括:
32、数据采集及校验模块,用于采集水文数据并进行数据校验;
33、数据算法处理模块,用于利用one-class svm模型对异常数据序列的数据点进行异常检测,得到第一指标值;还用于分别利用ewma算法、cof算法、isolation forest算法对异常数据序列的数据点进行异常检测,并结合各算法的权重对异常检测结果求和得到第二指标值;还用于将数据点对应的历年数据输入lstm模型得到拟合值,基于拟合值与异常数据序列的方差确定异常数据点,得到第三指标值;
34、异常数据检测模块,用于将第一指标值、第二指标值和第三指标值作为观测值输入隐马尔可夫模型进行识别,得到目标异常数据点。
35、本发明还提供一种可读存储介质,所述可读存储介质中存储有指令,当指令在计算机上运行时,使得计算机执行如上任一项方案所述的水文数据的处理方法。
36、本发明与现有技术相比,有益效果是:
37、(1)本发明对水文数据进行多维度异常检测,有效提升异常数据识别的精度;
38、(2)本发明在识别异常数据之后进行补充处理或者数据修正,从而实现数据的整编,保证数据的准确性。
技术特征:
1.一种水文数据的处理方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的水文数据的处理方法,其特征在于,所述步骤s1中,采集水文数据之后进行数据分类,划分为要素数据和工况数据;
3.根据权利要求2所述的水文数据的处理方法,其特征在于,所述步骤s2中,基于拟合值与异常数据序列的方差确定异常数据点,包括:
4.根据权利要求3所述的水文数据的处理方法,其特征在于,所述数据点的异常类型包括数据值突变和数据值缺失。
5.根据权利要求4所述的水文数据的处理方法,其特征在于,还包括以下步骤:
6.根据权利要求5所述的水文数据的处理方法,其特征在于,所述对目标异常数据点进行自适应时序整编,包括以下步骤:
7.根据权利要求6所述的水文数据的处理方法,其特征在于,所述周期性整编包括:
8.根据权利要求5所述的水文数据的处理方法,其特征在于,所述对目标异常数据点进行异常整编包括以下步骤:
9.一种水文数据的处理系统,应用如权利要求1所述的水文数据的处理方法,其特征在于,所述水文数据的处理系统包括:
10.一种可读存储介质,所述可读存储介质中存储有指令,其特征在于,当指令在计算机上运行时,使得计算机执行如权利要求1-8任一项所述的水文数据的处理方法。
技术总结
本发明涉及一种水文数据的处理方法、系统及可读存储介质,其处理方法包括:采集水文数据并进行数据校验,判断数据校验是否通过;若否,则对校验不通过的异常数据序列进行后续处理;利用One‑Class SVM模型对数据点进行异常检测,得到第一指标值;分别利用EWMA算法、COF算法、Isolation Forest算法对数据点进行异常检测,并结合各算法的权重加权求和得到第二指标值;将数据点对应的历年数据输入LSTM模型得到拟合值,基于拟合值与异常数据序列的方差确定异常数据点,得到第三指标值;将第一指标值、第二指标值和第三指标值作为观测值输入隐马尔可夫模型得到目标异常数据点。本发明提升异常数据的识别精度。
技术研发人员:陈晓莉,陈潇,李抗旱,蓝康波,徐路平,邹嫣,李修乾,赵碧君
受保护的技术使用者:浙江鹏信信息科技股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!