一种基于深度学习的图像鲁棒构建视觉里程计的方法
本发明涉及鲁棒构建领域,尤其涉及一种基于深度学习的图像鲁棒构建视觉里程计的方法。
背景技术:
1、近年来,移动机器人和自动驾驶领域得到了快速发展,自主定位作为其中的关键环节,也迎来了越来越多的研究和关注。自主定位主要由激光雷达和视觉传感器来实现,其中视觉传感器的成本较低且适用场景广泛,因此基于该传感的视觉里程计vslam被广泛使用。
2、视觉里程计目前有基于传统方法和基于深度学习方法的两种类型,前者在清晰场景下有着较为良好的位姿估计结果,但在挑战场景下位姿计算结果会发生严重退化。与之相比,基于深度学习的方法在面对挑战场景时,有着更为强大的潜能。目前,基于深度学习方法的主要依赖于光流估计,而现有的光流和位姿估计网络在模糊场景下会发生严重退化,所以如何在模糊场景下实现准确位姿估计的问题仍没有解决。
技术实现思路
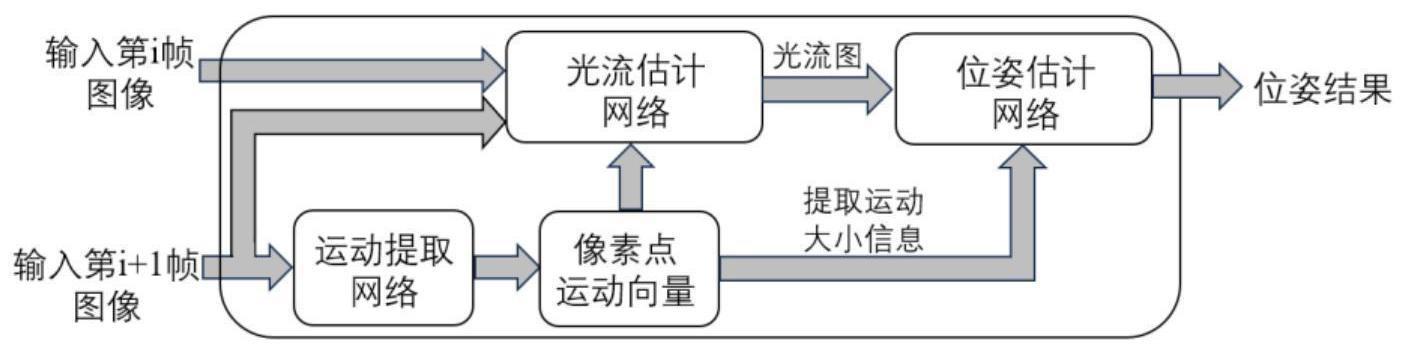
1、本发明为了解决上述问题,提出了一种基于深度学习的图像鲁棒构建视觉里程计的方法,本发明从模糊图像提取像素点的运动信息,引导光流估计,并增加光流图的置信度信息,实现了鲁棒和准确的位姿估计。
2、本发明解决上述技术问题的技术方案是:
3、一种基于深度学习的图像鲁棒构建视觉里程计的方法,包括以下步骤:
4、(1)利用监督训练方式训练运动提取网络,使用训练后得到运动提取网络根据图像的模糊拖影输出像素点运动向量,得到i+1帧图像像素点的运动信息,其中i≥0;
5、(2)以无监督训练方式训练光流估计网络,该网络以第i帧和第i+1帧的相邻两帧图像和第i+1帧图像像素点的运动信息为输入量,输出估计的光流图;
6、(3)以监督训练方式训练位姿估计网络,该网络以估计的光流图和其置信度信息为输入量,输出估计的相机位姿。
7、进一步地,所述步骤(1)中运动提取网络的训练结构包含两个模块:模糊生成模块和运动提取模块,其训练的监督标签为真实的模糊图像和清晰图像中像素点的零偏移量;训练过程分为两个流线:流线一为输入同一场景的模糊图像和清晰图像,运动提取网络提取模糊图像的运动信息,模糊生成模块基于提取的运动信息对清晰图像进行模糊化,然后生成的模糊图像与真实模糊图像构成监督关系;流线二为输入清晰图像,运动提取网络对清晰图像提取运动信息,生成的运动偏移量与零偏移量构成监督关系。
8、具体地,所述步骤(1)中,所述运动提取网络的训练框架产生的总损失为流线一损失和流线二损失的总和;其中,流线一的损失表示为流线二损失表示为具体形式如下:
9、(1)模糊生成模块生成的模糊图像与真实模糊图像的差异损失
10、
11、其中,和分别为生成的模糊图像b与真实模糊图像b的l2损失和ssim(structural similarity index)损失;
12、(2)运动信息的矢量光滑损失
13、
14、其中,h和w分别为图像的高度和宽度,v(x,y)为像素点的单位运动矢量,xmid和ymid为卷积核的中心点;
15、(3)运动信息的偏移大小损失
16、
17、其中,d(x,y)为像素点对应的运动向量,α为设定的像素点的偏移上限。
18、具体地,所述运动提取网络的训练框架的总损失为
19、进一步地,所述步骤(2)具体为:首先使用卷积网络,按照金字塔原则由上至下或由下至上来提取两帧图像的特征,然后通过每层提取的特征来构建匹配代价层,且将运动提取网络输出的各像素运动向量作为先验信息,引导匹配代价区域的构建,最后将提取的特征层和构建的匹配代价层输入光流估计网络,计算得到所需的光流图。
20、进一步地,所述步骤(2)中光流估计网络的训练方式为无监督训练,训练时使用相邻两帧图像i1和i2作为输入量,生成估计的光流图f12,然后将光流图作用于图像i2,使用后向扭曲生成估计的图像i1;该训练结构的总损失为图像i1和i1的光度一致性损失和光流图的边缘光滑损失的总和,具体形式如下:
21、
22、其中,λphot、分别为光度一致性损失和边缘光滑损失对应的权重,为charbonnier损失函数,为沿x和y方向的偏导,β为权重变量。
23、进一步地,所述步骤(3)中位姿估计网络使用的置信度信息层,其分辨率与光流图相同,由运动提取网络输出的运动向量的标量信息生成,各像素点的置信度大小与该像素对应的运动大小成反比关系;位姿估计网络采用监督训练的方式进行训练,训练时,以光流图和置信度信息层为输入量,以相机的六自由度位姿为监督标签;该训练结构的总损失具体形式如下:
24、
25、其中,r分别为估计的平移位姿和旋转位姿,t、r为对应的真实位姿。
26、具体地,该方法的整体网络的联合训练,以相邻两帧图像为输入量,以相机的六自由度位姿为监督标签,训练的网络包括光流估计网络和位姿估计网络,运动信息提取网络在训练过程中不进行参数更新。
27、本发明的有益效果如下:
28、本发明利用模糊图像包含的运动信息作为先验信息,通过约束光流匹配代价区域的分布来增加光流估计的准确性,并且在光流图的基础上增加了其置信度信息,最终实现了模糊场景下相机位姿的鲁棒估计。
技术特征:
1.一种基于深度学习的图像鲁棒构建视觉里程计的方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于深度学习的图像鲁棒构建视觉里程计的方法,其特征在于,所述步骤(1)中运动提取网络的训练结构包含两个模块:模糊生成模块和运动提取模块,其训练的监督标签为真实的模糊图像和清晰图像中像素点的零偏移量;训练过程分为两个流线:流线一为输入同一场景的模糊图像和清晰图像,运动提取网络提取模糊图像的运动信息,模糊生成模块基于提取的运动信息对清晰图像进行模糊化,然后生成的模糊图像与真实模糊图像构成监督关系;流线二为输入清晰图像,运动提取网络对清晰图像提取运动信息,生成的运动偏移量与零偏移量构成监督关系。
3.根据权利要求1所述的一种基于深度学习的图像鲁棒构建视觉里程计的方法,其特征在于,所述步骤(1)中,所述运动提取网络的训练框架产生的总损失为流线一损失和流线二损失的总和;其中,流线一的损失表示为流线二损失表示为具体形式如下:
4.根据权利要求3所述的一种基于深度学习的图像鲁棒构建视觉里程计的方法,其特征在于,所述运动提取网络的训练框架的总损失为
5.根据权利要求1所述的一种基于深度学习的图像鲁棒构建视觉里程计的方法,其特征在于,所述步骤(2)具体为:首先使用卷积网络,按照金字塔原则由上至下或由下至上来提取两帧图像的特征,然后通过每层提取的特征来构建匹配代价层,且将运动提取网络输出的各像素运动向量作为先验信息,引导匹配代价区域的构建,最后将提取的特征层和构建的匹配代价层输入光流估计网络,计算得到所需的光流图。
6.根据权利要求1所述的一种基于深度学习的图像鲁棒构建视觉里程计的方法,其特征在于,所述步骤(2)中光流估计网络的训练方式为无监督训练,训练时使用相邻两帧图像i1和i2作为输入量,生成估计的光流图f12,然后将光流图作用于图像i2,使用后向扭曲生成估计的图像i1;该训练结构的总损失为图像i1和i1的光度一致性损失和光流图的边缘光滑损失的总和,具体形式如下:
7.根据权利要求1所述的一种基于深度学习的图像鲁棒构建视觉里程计的方法,其特征在于,所述步骤(3)中位姿估计网络使用的置信度信息层,其分辨率与光流图相同,由运动提取网络输出的运动向量的标量信息生成,各像素点的置信度大小与该像素对应的运动大小成反比关系;位姿估计网络采用监督训练的方式进行训练,训练时,以光流图和置信度信息层为输入量,以相机的六自由度位姿为监督标签;该训练结构的总损失具体形式如下:
8.根据权利要求1所述的一种基于深度学习的图像鲁棒构建视觉里程计的方法,其特征在于,该方法的整体网络的联合训练,以相邻两帧图像为输入量,以相机的六自由度位姿为监督标签,训练的网络包括光流估计网络和位姿估计网络,运动信息提取网络在训练过程中不进行参数更新。
技术总结
本发明公开了一种基于深度学习的图像鲁棒构建视觉里程计的方法,该视觉里程计包括运动提取网络、光流估计网络和位姿估计网络;所述运动提取网络根据图像的模糊拖影输出像素点的运动向量;所述光流估计网络将像素点的运动向量作为先验信息来构建匹配代价(Cost Volume)层,得到更为准确的光流图;所述位姿估计网络将估计的光流图和置信度信息层作为输入量,计算得到相机的六自由度位姿信息。本发明利用模糊图像包含的运动信息作为先验信息,约束了匹配代价区域的分布,增加了光流图的置信度信息,实现了模糊场景下相机位姿的鲁棒估计。
技术研发人员:李基拓,张佳路,李嘉奇,陆国栋
受保护的技术使用者:浙江大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!