大规模跨语言知识图谱间的无监督实体对齐方法和系统
本发明属于实体对齐,更具体地,涉及大规模跨语言知识图谱间的无监督实体对齐方法和系统。
背景技术:
1、知识图谱以三元组的形式(例如,<实体1,关系,实体2>)存储真实世界的知识,实体至少存在两种及以上的语言表示形式。目前,知识图谱已经广泛应用于信息检索和人工智能等领域,由于不同的知识图谱往往包含着互补的信息,这些互补信息对于提高知识图谱的质量来说有着重要作用,因此,许多研究者致力于知识图谱间对齐任务的研究。实体对齐,是一类找出不同知识图谱中表征同一语义实体的技术,能帮助各知识图谱更好的进行融合,是多知识图谱融合的关键技术之一。
2、无监督的实体对齐任务一般根据知识图谱的侧信息(例如实体邻域、属性和描述等)得到一些近似的候选种子集。专利cn112948597a公开一种无监督的知识图谱实体对齐方法,利用实体的辅助信息生成文本距离矩阵,利用图卷积网络生成结构距离矩阵。基于文本距离矩阵和结构距离矩阵,进一步融合生成距离矩阵,最后迭代式的完成实体对齐任务。但是,该方法缺乏对知识图谱多视图信息的利用,且语义层面的平均词嵌入方法不能充分表征语义信息。专利cn115658927a公开一种面向时序知识图谱的无监督实体对齐方法,首先通过图卷积式前向传递的方式构建特征矩阵,接着采用双向策略来生成实体对齐矩阵,并以匹配的方式来进一步获得预对齐伪标签。然后,将伪标签和时序知识图谱的四元组相结合,来对利用时间信息扩展后的图神经网络进行训练,以得到关系特征矩阵。最后,采用加权融合的方式来融合时间特征矩阵和关系特征矩阵,并通过最小化距离完成实体对齐任务。但是,该方法一定程度忽略了语义信息。此外,侧重时序知识图谱的对齐,即依赖知识图谱的时序信息,存在应用上的局限性。
技术实现思路
1、针对现有技术的缺陷,本发明的目的在于提供大规模跨语言知识图谱间的无监督实体对齐方法和系统,旨在解决现有实体对齐方法需标签数据、模型复杂和对大规模实体对齐任务的适用性问题。
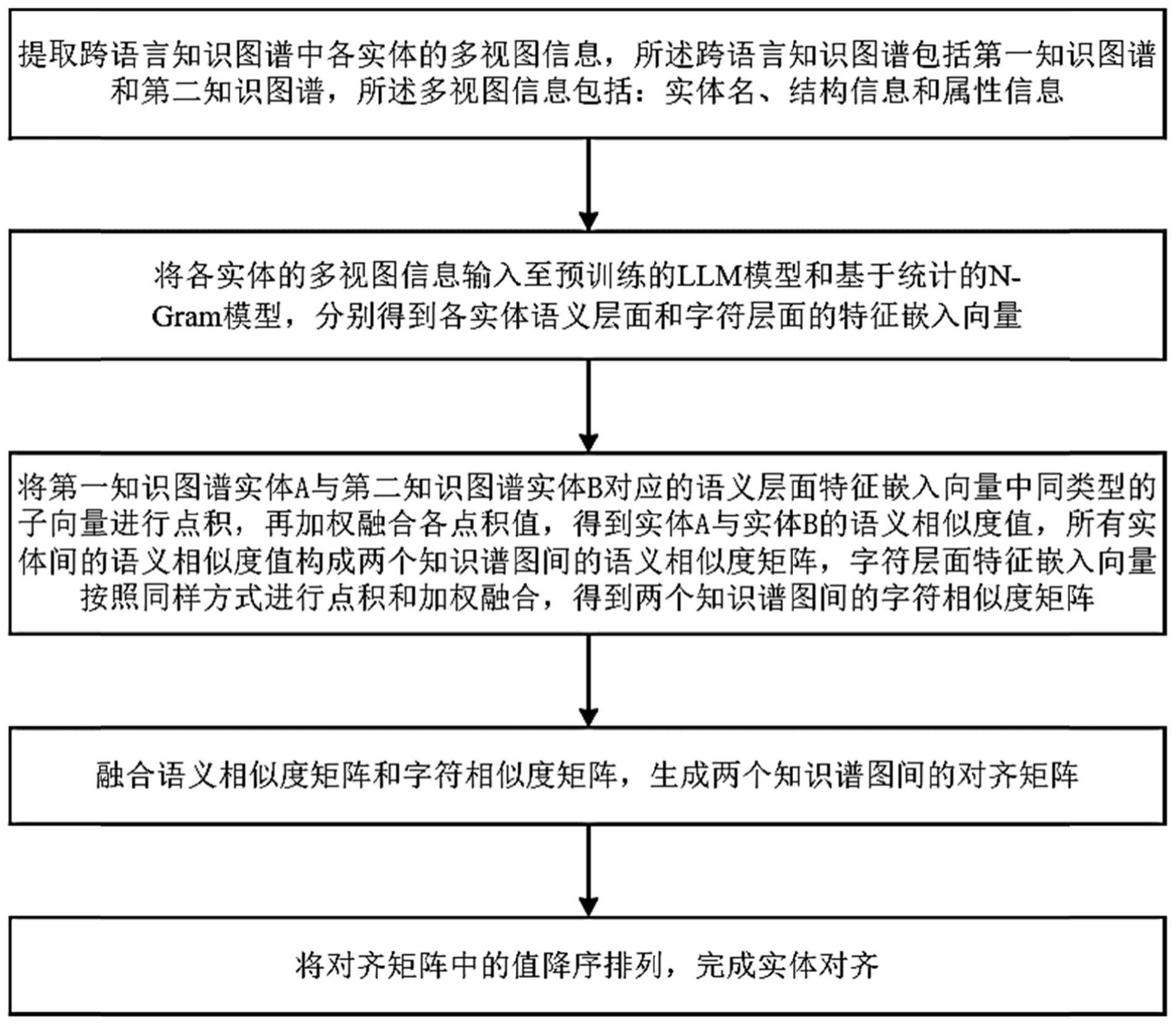
2、为实现上述目的,第一方面,本发明提供了一种大规模跨语言知识图谱间的无监督实体对齐方法,包括:
3、提取跨语言知识图谱中各实体的多视图信息,所述跨语言知识图谱包括第一知识图谱和第二知识图谱,所述多视图信息包括:实体名、结构信息和属性信息;
4、将各实体的多视图信息输入至预训练的llm模型和基于统计的n-gram模型,分别得到各实体语义层面和字符层面的特征嵌入向量;
5、将第一知识图谱实体a与第二知识图谱实体b对应的语义层面特征嵌入向量中同类型的子向量进行点积,再加权融合各点积值,得到实体a与实体b的语义相似度值,所有实体间的语义相似度值构成两个知识谱图间的语义相似度矩阵,字符层面特征嵌入向量按照同样方式进行点积和加权融合,得到两个知识谱图间的字符相似度矩阵;
6、融合语义相似度矩阵和字符相似度矩阵,生成两个知识谱图间的对齐矩阵;
7、将对齐矩阵中的值降序排列,完成实体对齐。
8、优选地,还包括:在输入至预训练的llm模型和基于统计的n-gram模型前,通过翻译器处理多视图信息,实现预对齐。
9、需要说明的是,使用翻译器进行预对齐,能提高对齐准确度,且对齐语言区别越大,效果越好。
10、优选地,语义层面加权融合和字符层面加权融合的各权重相同。
11、需要说明的是,这里语义层面加权融合和字符层面加权融合的各权重相同,减少了对齐过程中超参数的数量。
12、优选地,加权融合时,实体名类型子向量的权重>属性信息类型子向量的权重>结构信息类型子向量的权重。
13、需要说明的是,本发明优选上述赋值各类型子向量的权重,将实体名信息对实体最具标识性,其次为属性信息。而结构信息,则较为缺乏标识性。
14、优选地,对齐矩阵采用以下方式生成:
15、
16、其中,s为对齐矩阵,slf为语义相似度矩阵,ssf为字符相似度矩阵,°为哈达玛积。
17、需要说明的是,本发明优选上述方式生成对齐矩阵。交叉融合的方式,能让语义和字符相似度更好地互补,从而实现语义相似度值较低时更多地考虑字符相似度,反之亦然。
18、优选地,对齐矩阵采用以下方式生成:
19、s=slf+f(ssf)
20、其中,s为对齐矩阵,slf为语义相似度矩阵,ssf为字符相似度矩阵,f为正则化函数。
21、需要说明的是,本发明优选上述方法生成对齐矩阵。以语义相似度为主,将字符相似度作为辅助信息。采用此方法能充分利用实体语义信息,字符信息则可进一步提高对齐准确度。
22、为实现上述目的,第二方面,本发明提供了一种大规模跨语言知识图谱间的无监督实体对齐系统,包括:处理器和存储器;所述存储器,用于存储计算机执行指令;所述处理器,用于执行所述计算机执行指令,使得第一方面所述的方法被执行。
23、为实现上述目的,第三方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,当所述计算机程序在处理器上运行时,使得所述处理器执行第一方面所述的方法。
24、总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下有益效果:
25、本发明公开大规模跨语言知识图谱间的无监督实体对齐方法和系统,在特征嵌入阶段,本发明基于知识图谱的多视图信息,从语义和字符两个层面进行特征嵌入。语义层面,使用预训练的大语言模型llm进行嵌入。字符层面,使用n-gram模型进行嵌入。在对齐阶段,本发明首先进行多视图信息融合,分别生成语义和字符两个层面的相似度矩阵。其次,采用加权的方式融合语义和字符的相似度矩阵,从而生成最终的对齐矩阵。最后,依据对齐矩阵完成实体对齐任务。本发明不需要事先进行任何数据标注,属于无监督的实体对齐;语义和字符两个层面的特征嵌入,能更好地捕获待对齐实体特征;组合语义特征和字符特征的实体对齐,提高了对齐准确度并保证对齐效率,适用于大规模跨语言知识图谱间(例如,实体对齐数据集dbp100k)的对齐任务。
技术特征:
1.一种大规模跨语言知识图谱间的无监督实体对齐方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,还包括:
3.如权利要求1所述的方法,其特征在于,语义层面加权融合和字符层面加权融合的各权重相同。
4.如权利要求1所述的方法,其特征在于,加权融合时,实体名类型子向量的权重>属性信息类型子向量的权重>结构信息类型子向量的权重。
5.如权利要求1所述的方法,其特征在于,对齐矩阵采用以下方式生成:
6.如权利要求1所述的方法,其特征在于,对齐矩阵采用以下方式生成:
7.一种大规模跨语言知识图谱间的无监督实体对齐系统,其特征在于,包括:处理器和存储器;
8.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,当所述计算机程序在处理器上运行时,使得所述处理器执行权利要求1至6任一项所述的方法。
技术总结
本发明公开大规模跨语言知识图谱间的无监督实体对齐方法和系统,属于实体对齐领域。在特征嵌入阶段,基于知识图谱的多视图信息,从语义和字符两个层面进行嵌入。语义层面,使用预训练的大语言模型(LLM,Large Language Model)进行嵌入。字符层面,使用N‑Gram模型进行嵌入。在对齐阶段,先融合多视图信息,分别生成语义和字符层面的相似度矩阵。再采用加权的方式融合语义和字符的相似度矩阵,生成对齐矩阵。最后,依据对齐矩阵完成对齐任务。本发明不需要事先进行任何数据标注,属于无监督的实体对齐;语义和字符两个层面的特征嵌入,更好地捕获了待对齐实体特征;组合语义特征和字符特征,提高了对齐准确度并保证对齐效率,适用于各种跨语言知识图谱间的实体对齐任务。
技术研发人员:蒋川宇,谢夏,陈丽君,黄小欧
受保护的技术使用者:海南大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!