一种基于头部输出特征自适应匹配的知识蒸馏方法
本发明属于计算机视觉技术,具体涉及一种基于头部输出特征自适应匹配的知识蒸馏方法。
背景技术:
1、知识蒸馏即通过训练将教师模型的知识迁移到学生模型中,随着深度学习的发展,知识蒸馏效果逐渐提升,但是由于学生模型相对教师模型较小,所以学生模型的表达能力有限,很难充分学习到教师模型更多真正重要的知识。目前,已知的知识蒸馏算法主要基于以下两种思想:一是将教师模型的输出特征作为知识传递给学生模型;二是从教师网络中间层提取深层特征作为知识蒸馏给学生模型。
2、赵博睿在《decoupled knowledge distillation》一文中延续将教师模型的输出特征作为知识传递给学生模型的思想,认为应当在损失函数中合理平衡目标类损失和非目标类损失才能更灵活有效地发挥输出层特征蒸馏的作用,因此作者采用解耦的方法将经典的蒸馏损失重述为目标类损失和非目标类损失之和,解决了在经典蒸馏损失中非目标类信息被抑制而难以完全体现其价值的问题。但在蒸馏过程中仍存在由于教师模型和学生模型的表达能力存在差异,学生模型无法将信息充分利用,且在有限的能力下不能提取和匹配到更细节更重要的信息的问题。
技术实现思路
1、本发明的目的在于提供一种基于头部输出特征自适应匹配的知识蒸馏方法,有效的挖掘了输出层特征蒸馏的部分潜力,解决了输出特征知识利用不充分、学生模型和教师模型的表达能力差异较大的问题并且未引入额外参数产生计算和内存上的损耗,具有更高的训练效率和更好的特征可移植性。
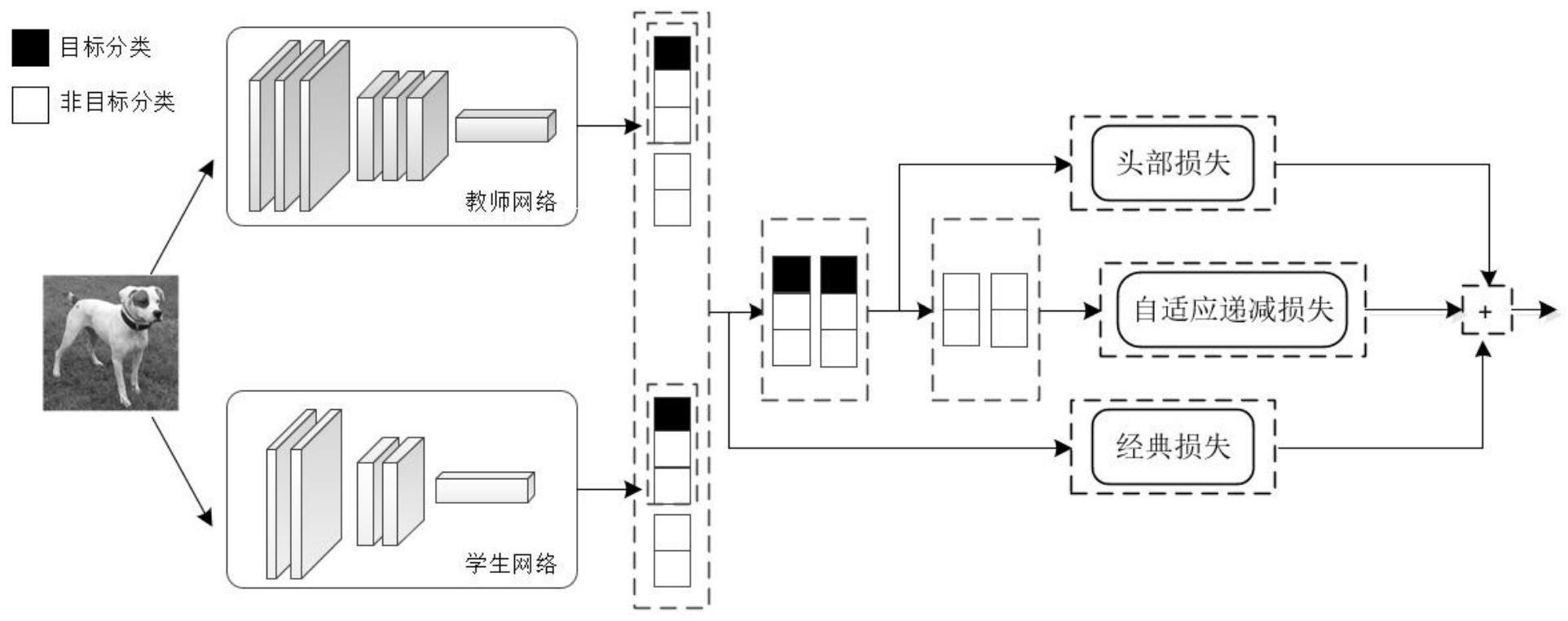
2、实现本发明目的的技术解决方案为:一种基于头部输出特征自适应匹配的知识蒸馏方法,包括以下步骤:
3、步骤s1、在cifar-100数据集中采用随机采集k幅带标签的图像,10000<k≤60000,对上述k幅图像进行归一化处理,将像素大小统一为h×w,其中,h为图像高度,w为图像宽度。将统一尺寸后的图像按照5:1的比例随机划分为训练数据集和测试数据集,对训练数据集进行数据增强构成教师-学生网络训练数据集,利用教师-学生网络训练数据集对教师网络进行预训练,得到预训练教师网络,转入步骤s2。
4、步骤s2、利用预训练教师网络、学生网络分别提取到对应的预训练教师网络和学生网络的原始输出层特征,并分别将其按照得分大小依次排序,构成相应的预训练教师网络原始输出层特征的排序集合和学生网络原始输出层特征的排序集合,转入步骤s3。
5、步骤s3、对步骤s2中预训练教师网络原始输出层特征的排序集合以及学生网络原始输出层特征的排序集合进行第一次修剪处理,即分别截取各自排序集合中的前m层输出层特征,作为预训练教师网络的头部输出特征和学生网络的头部输出特征,转入步骤s4。
6、步骤s4、利用步骤s2中的排序之前的预训练教师网络的原始输出层特征和排序之前的学生网络的原始输出层特征计算原始蒸馏损失。再利用步骤s3得到的预训练教师网络的头部输出特征和学生网络的头部输出特征计算头部蒸馏损失,转入步骤s5。
7、步骤s5、对步骤s3得到的预训练教师网络的头部输出特征和学生网络的头部输出特征进行第二次修剪处理,即解耦出目标类头部输出特征和非目标类头部输出特征并去除目标类头部输出特征。对保留下来的非目标类头部输出特征进行局部输出特征匹配,即输出特征自适应匹配,并计算出非目标类的自适应输出特征损失,转入步骤s6。
8、步骤s6、利用头部蒸馏损失、原始蒸馏损失以及非目标类的自适应输出特征损失,得到总的蒸馏损失,并以此对学生网络的网络参数进行更新,最终获得训练好的学生网络,转入步骤s7。
9、步骤s7、将测试数据集输入到训练好的学生网络,输出测试集中每个样本对应的预测结果,测试训练好的学生网络的准确率。
10、与现有技术相比,本发明优点在于:
11、(1)与现有的知识蒸馏方法相比,只考虑输出特征概率分布占比较高的部分,剪去几乎不做贡献的特征,再在占比重要的特征里细化非目标类的知识,本发明所述的一种基于头部输出特征自适应匹配方法同时解决了输出特征知识利用不充分、学生模型和教师模型的表达能力差异较大的问题并且未引入额外参数产生计算和内存上的损耗,具有更高的训练效率和更好的特征可移植性。
12、(2)本发明提出了将注意力的方法应用于基于输出层头部特征的知识蒸馏方法,强迫学生网络模仿教师网络的较为重要的种类间相似度,显著提高了学生网络的性能。
13、(3)本发明通过另一种角度分析并且继承了解耦知识蒸馏,并且融合了自适应注意力匹配的方法,最终定位于含更多泛化信息的中间主体特征,自适应地提取到更有利于学生网络对教师网络学习的分类信息,同时也提升了学生网络对陌生数据集的适应性。
技术特征:
1.一种基于头部输出特征自适应匹配的知识蒸馏方法,其特征在于,步骤如下:
2.根据权利要求1所述的基于头部输出特征自适应匹配的知识蒸馏方法,其特征在于,步骤s3中,对步骤s2中预训练教师网络原始输出层特征的排序集合以及学生网络原始输出层特征的排序集合进行第一次修剪处理,即分别截取各自排序集合中的前m层输出层特征,作为预训练教师网络的头部输出特征和学生网络的头部输出特征,具体如下:
3.根据权利要求1所述的基于头部输出特征自适应匹配的知识蒸馏方法,其特征在于,步骤s4中,利用步骤s2中的排序之前的预训练教师网络的原始输出层特征和学生网络的原始输出层特征计算原始蒸馏损失;再利用步骤s3得到的预训练教师网络的头部输出特征和学生网络的头部输出特征计算头部蒸馏损失,具体如下:
4.根据权利要求1所述的基于头部输出特征自适应匹配的知识蒸馏方法,其特征在于,步骤s5中,对步骤s3得到的预训练教师网络的头部输出特征和学生网络的头部输出特征进行第二次修剪处理,即解耦出目标类头部输出特征和非目标类头部输出特征并去除目标类头部输出特征;对保留下来的非目标类头部输出特征进行局部输出特征匹配,即输出特征自适应匹配,并计算出非目标类知识蒸馏损失,具体如下:
5.根据权利要求1所述的基于头部输出特征自适应匹配的知识蒸馏方法,其特征在于,步骤s6中利用头部蒸馏损失、原始蒸馏损失以及非目标类的自适应输出特征损失,得到总的蒸馏损失,即基于头部输出特征自适应匹配的知识蒸馏损失kdtotal的公式为:
技术总结
本发明公开了一种基于头部特征自适应匹配的知识蒸馏方法,对教师网络和学生网络的输出层特征进行排序和修剪处理,将注意力集中到修剪处理后得到的头部特征中,根据相应的排序方式计算头部蒸馏损失;再将头部特征中包含目标类信息的特征层修剪得到主体特征,在主体特征中进行自适应匹配,根据相应的排序方式计算自适应输出特征损失;利用总蒸馏损失促使学生网络学习主要输出特征层的类间相似度信息。本发明利用了非目标类知识的信息并且融合了自适应注意力匹配的方法,定位到含更多泛化信息的主体特征,自适应地提取到更有利于学生网络学习的分类信息,提升了学生网络对陌生数据集的适应性,同时也增强了模型的泛化性和鲁棒性。
技术研发人员:申政文,秦新芳,李玉莲,袁静波,王军
受保护的技术使用者:中国矿业大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!