一种智能座舱语音可见即可说自动化测试方法及系统与流程
本发明属于汽车,具体涉及一种智能座舱语音可见即可说自动化测试方法及系统。
背景技术:
1、当前智能座舱语音可见即可说应用广泛,完善的可见即可说能够覆盖车机全部使用场景,大幅提升用户体验,但车机可见即可说测试很少有自动化执行的,测试大都依赖人工,通过人工执行测试语料,没有完整的自动化测试方案,测试效率低,当语料泛化较多时,且有复杂语音场景如音色、底噪等要求时,需要耗费大量时间及人力。另外,车机上的从接口获取到的动态名称,例如歌手名称、专辑名称、音乐名称等可见即可说场景,由于其是动态获取的,当前没有对此场景进行自动化测试的,又由于人工测试效率的问题,只能有选择的执行该场景的可见即可说测试,所以人工执行可见即可说测试时测试覆盖率并不高。
技术实现思路
1、针对现有技术中存在的测试效率低、耗费时间人力、场景覆盖率不足及复杂场景难以模拟等问题,本发明提供了一种智能座舱语音可见即可说自动化测试方法及系统,按照可见即可说使用场景及流程设计测试集,能够提升测试用例的覆盖率,最大程度上模拟智能座舱用户真实使用场景。
2、本发明通过如下技术方案实现:
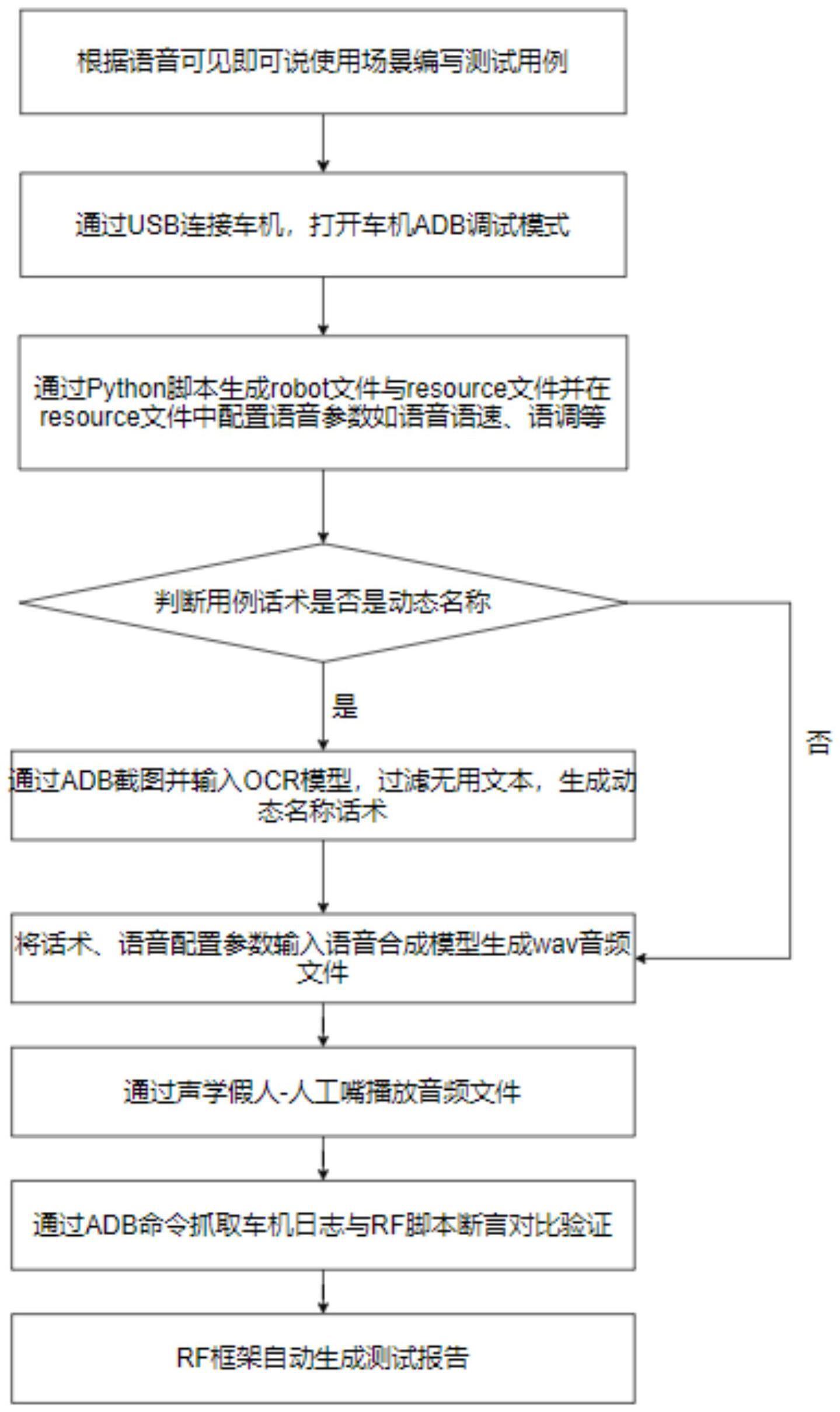
3、一种智能座舱语音可见即可说自动化测试方法,具体包括如下步骤:
4、步骤一:根据语音可见即可说使用场景编写测试用例;
5、步骤二:测试前,通过usb连接车机,打开车机adb调试模式;
6、步骤三:将所述测试用例通过python脚本生成robot文件与resource文件,并在resource文件中配置测试场景所需要的语音参数;
7、步骤四:判断执行可见即可说测试用例是否是动态名称;
8、若是,则导入到ocr模型生成文本文件过滤后生成话术;
9、若否,则直接进入步骤五;
10、步骤五:将步骤四的话术、步骤三的语音配置参数输入语音合成模型生成wav音频文件;
11、步骤六:通过声学假人-人工嘴播放所述生产的wav音频文件;
12、步骤七:执行所述音频文播放过程中,通过adb命令抓取车机日志与rf脚本断言,并对所述车机日志与rf脚本断言进行对比验证;
13、若所述车机日志与rf脚本断言相同,则测试用例通过;
14、若所述车机日志与rf脚本断言不同,则测试用例不通过;
15、步骤八:由rf框架自动生成测试报告。
16、进一步地,所述测试用例采用excel格式,通过python的xlwings模块将测试用例集合写入robot文件与resource文件中。
17、进一步地,所述python的xlwings模块将测试用例集合写入robot文件与resource文件过程中,python脚本对resource文件可见即可说话术中由接口获取的动态名称话术进行标识,且对robot文件中的测试脚本打上测试场景,方便多轮测试有选择的执行。
18、进一步地,步骤四中,所述导入到ocr模型生成文本文件过滤后生成话术,具体包括如下内容:
19、若为动态名称,则通过安卓adb命令screecap对车机截图,pull命令下载到本地,并将该截图导入到ocr模型中,所述ocr模型为pp-ocrv3,模型输出文字后对其过滤后即可作为动态名称话术进行测试,该过滤过程由python脚本完成,主要过滤掉识别到的其他文字。
20、另一方面,本发明提供了一种智能座舱语音可见即可说自动化测试系统,包括:
21、测试用例编写模块,用于根据语音可见即可说使用场景编写测试用例;
22、配置模块,用于通过python脚本生成robot文件与resource文件,并在resource文件中配置测试场景所需要的语音参数;
23、判断模块,用于判断执行可见即可说测试用例是否是动态名称;
24、语音合成模块,用于将话术、语音配置参数生成wav音频文件;
25、播放模块,用于通过声学假人-人工嘴播放所述生产的wav音频文件;
26、执行模块,用于在执行所述音频文播放过程中,通过adb命令抓取车机日志与rf脚本断言,并对所述车机日志与rf脚本断言进行对比验证;
27、rf框架,用于自动生成测试报告。
28、进一步地,所述rf框架由robot文件与resource文件构成,其中,robot文件用于存储测试脚本,resource文件用于存储语音配置、可见即可说话术、测试断言以及封装的关键字。
29、与现有技术相比,本发明的优点如下:
30、(1)、本发明采用robotframework自动化测试框架,简称rf框架,进行自动化测试,该框架由python编写,能够快速便捷的更改可见即可说语料配置文件。通过python脚本可快速将测试集生成rf脚本;
31、(2)、本发明通过rf自带的标签机制有选择的执行不同场景的测试集;
32、(3)、本发明采用语音合成技术,通过配置文件生成多种不同场景包括不同语速、音色、音调、音量、底噪等的语料音频,并通过声学假人如人工嘴播放,提高测试效率,实现复杂场景的语音可见及可说语音测试。
33、(4)、本发明通过ocr技术可以快速识别车机上的动态名称,进而生成测试语料;
34、(5)、本发明通过车机log中可见即可说执行数据与rf脚本中断言进行对比验证,一致为通过,不一致则失败,rf框架能在测试完成后自动生成测试报告;
35、(6)、本发明只需人工设计、编写测试用例后将用例进行输入即可完成可见即可说测试执行,节省大量时间人工成本。
技术特征:
1.一种智能座舱语音可见即可说自动化测试方法,其特征在于,具体包括如下步骤:
2.如权利要求1所述的一种智能座舱语音可见即可说自动化测试方法,其特征在于,所述测试用例采用excel格式,通过python的xlwings模块将测试用例集合写入robot文件与resource文件中。
3.如权利要求1所述的一种智能座舱语音可见即可说自动化测试方法,其特征在于,所述python的xlwings模块将测试用例集合写入robot文件与resource文件过程中,python脚本对resource文件可见即可说话术中由接口获取的动态名称话术进行标识,且对robot文件中的测试脚本打上测试场景,方便多轮测试有选择的执行。
4.如权利要求1所述的一种智能座舱语音可见即可说自动化测试方法,其特征在于,步骤四中,所述导入到ocr模型生成文本文件过滤后生成话术,具体包括如下内容:
5.一种智能座舱语音可见即可说自动化测试系统,用于实现如权利要求1-4任一项所述的方法,其特征在于,包括:
6.如权利要求1所述的一种智能座舱语音可见即可说自动化测试方法,其特征在于,所述rf框架由robot文件与resource文件构成,其中,robot文件用于存储测试脚本,resource文件用于存储语音配置、可见即可说话术、测试断言以及封装的关键字。
技术总结
本发明公开了一种智能座舱语音可见即可说自动化测试方法及系统,属于汽车技术领域,包括:根据语音可见即可说使用场景编写测试用例;将测试用例通过Python脚本生成robot文件与resource文件,并在resource文件中配置测试场景所需要的语音参数;判断执行可见即可说测试用例是否是动态名称;将话术、语音配置参数输入语音合成模型生成wav音频文件;通过声学假人‑人工嘴播放音频文件;通过ADB命令抓取车机日志与RF脚本断言,并对所述车机日志与RF脚本断言进行对比验证;由RF框架自动生成测试报告。该方法按照可见即可说使用场景及流程设计测试集,能够提升测试用例的覆盖率,最大程度上模拟智能座舱用户真实使用场景。
技术研发人员:郭沣,李振龙,魏强
受保护的技术使用者:一汽奔腾轿车有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!