一种基于大语言模型的智能问答方法与流程
本发明属于人工智能,具体涉及一种基于大语言模型的智能问答方法。
背景技术:
1、随着大语言模型的迭代更新,大语言模型的功能越来越通用和智能,其问答能力、文本生成能力更强,且在众多领域得到广泛使用。但是如果某些领域公开的现成数据较少,就会导致大语言模型在该领域训练过程中由于缺少训练数据,使得大语言模型在该领域表现得不够优秀。
2、因此,如何将各个领域更多的数据和大语言模型进行有机融合,进而提高问答的精准度,是目前面临的重要课题。
技术实现思路
1、针对现有技术中的缺陷,本发明提供一种基于大语言模型的智能问答方法,提高了问答的精准度。
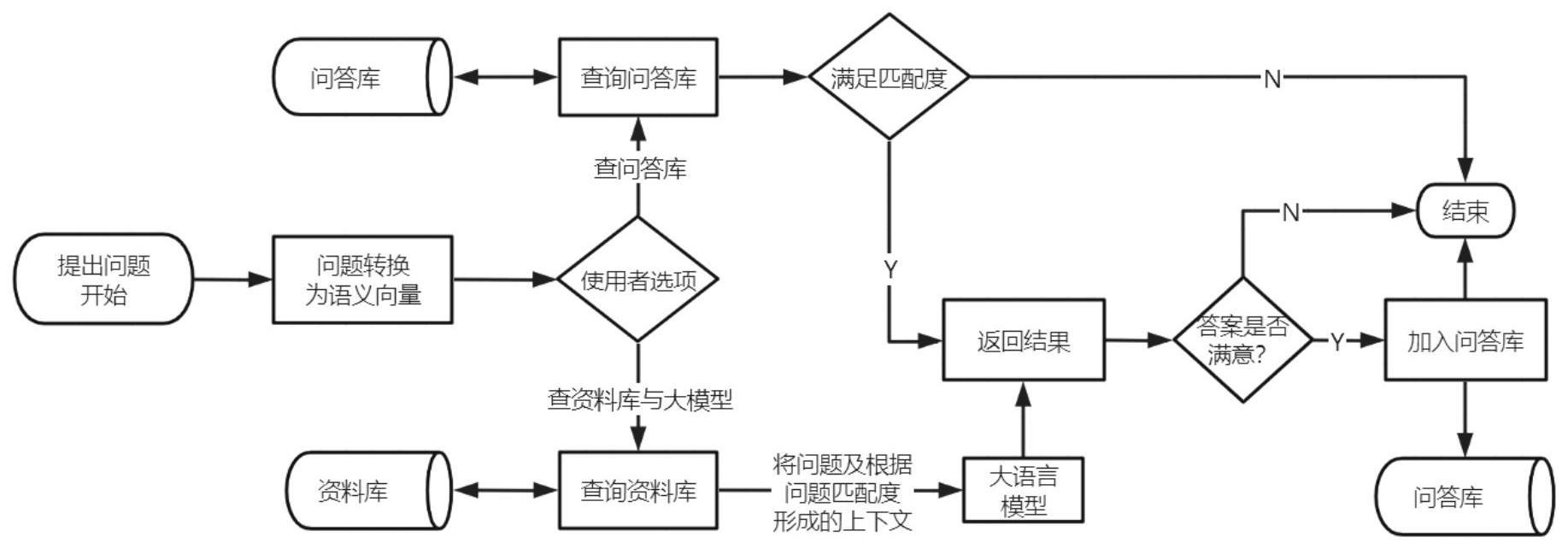
2、第一方面,一种基于大语言模型的智能问答方法,包括:
3、根据用户的私有数据在本地创建问答库和资料库;问答库包括多个标准问题以及关联的标准答案;资料库包括多个标准段落;
4、接收问题;
5、根据问题查询问答库和/或资料库;
6、当问答库中存在与问题匹配的标准问题时,输出问答库中标准问题关联的标准答案,作为问题的答案;
7、获取资料库中与问题匹配的标准段落,将标准段落和问题输入至大语言模型中;当大语言模型输出的答案与问题匹配时,定义答案为问题的标准答案,加入问答库。
8、进一步地,问答库的创建方法包括:
9、手动输入已有的标准问题及对应的标准答案;
10、将私有数据输入至大语言模型中,以得到大语言模型输出的标准问题和标准答案;
11、根据标准问题计算标准问题语义向量;
12、将标准问题语义向量、标准问题和标准答案进行关联存储。
13、进一步地,问答库的匹配方法包括:
14、创建问答匹配函数;
15、根据问题查询问答库,以得到问答库输出的标准问题以及关联的标准问题语义向量;
16、当问答库输出的标准问题与所述问题语义向量距离落入问答匹配函数的问答匹配区域时,定义问答库输出的标准问题与问题匹配。
17、进一步地,问答匹配函数的创建方法包括:
18、获取一系列样本问题;
19、分别计算每个样本问题与相似问题、其他样本问题的语义向量距离;
20、在平面坐标上标出所有所述语义向量距离;
21、根据平面坐标上各点的分布,拟合出一条曲线,定义为所述问答匹配函数;
22、其中每个样本问题与相似问题、其他样本问题的语义向量距离的计算方法包括:
23、获取样本问题a;
24、计算样本问题a的语义向量;
25、将样本问题a输入至大语言模型中,定义大语言模型输出的多个标准问题为多个相似问题a1,a2,...,an;
26、分别计算相似问题a1,a2,...,an的相似问题语义向量,并求出它们与样本问题a的语义向量距离,分别得到ta1,ta2...tan,语义向量距离在平面坐标上表示为(a,ta1),(a,ta2)...(a,tan)的点;
27、分别计算其他样本问题b,c,...,n的语义向量,并求出它们与样本问题a的语义向量距离,分别得到tab,tac...tan,语义向量距离在平面坐标上表示为(a,tab),(a,tac)...(a,tan)。
28、进一步地,资料库的创建方法包括:
29、接收资料文档;
30、利用文档处理工具对资料文档进行预处理,以得到多个标准段落;
31、计算标准段落的标准段落语义向量;
32、将标准段落和标准段落语义向量进行关联存储。
33、进一步地,资料库的匹配方法包括:
34、创建资料匹配函数;
35、根据问题查询资料库,以得到资料库输出的多个标准段落;
36、将所有标准段落合并后输入至大语言模型;
37、当大语言模型输出的答案达到用户满意度时,定义大语言模型的输出的答案为标准答案,加入问答库。
38、进一步地,资料匹配函数的创建方法包括:
39、获取样本问题;
40、计算样本问题的语义向量;
41、将样本问题输入至大语言模型中,定义大语言模型输出的多个标准问题为多个相似问题;
42、分别计算各个相似问题的相似问题语义向量;
43、根据多个相似问题语义向量查询资料库,每个相似问题都得到最近语义向量距离和第n近语义向量距离;
44、以相似问题语义向量为横坐标,以语义向量距离为纵坐标建立平面坐标;
45、在平面坐标上,根据所有最近语义向量距离绘制第一曲线;根据所有第n近语义向量距离绘制第二曲线,以得到资料匹配函数;
46、定义第一曲线和第二曲线之间的区域为资料匹配区域。
47、进一步地,还包括:
48、将接收到的评价信息作为监督学习样本;
49、根据监督学习样本对大语言模型进行微调训练。
50、进一步地,还包括:
51、配置每个用户的问答权限;
52、依据问答权限为不同的用户提供不同的问答。
53、进一步地,还包括:
54、创建多个提示词模版;
55、显示用户选中的提示词模版。
56、由上述技术方案可知,本发明提供的基于大语言模型的智能问答方法,根据用户的私有数据创建问答库和资料库,并结合大语言模型共同完成智能问答,克服了部分领域公开的现成数据较少,大模型在该领域训练不充分,导致大模型在该领域精准度低的缺陷。
技术特征:
1.一种基于大语言模型的智能问答方法,其特征在于,包括:
2.根据权利要求1所述基于大语言模型的智能问答方法,其特征在于,所述问答库的创建方法包括:
3.根据权利要求2所述基于大语言模型的智能问答方法,其特征在于,所述问答库的匹配方法包括:
4.根据权利要求3所述基于大语言模型的智能问答方法,其特征在于,所述问答匹配函数的创建方法包括:
5.根据权利要求1所述基于大语言模型的智能问答方法,其特征在于,所述资料库的创建方法包括:
6.根据权利要求5所述基于大语言模型的智能问答方法,其特征在于,所述资料库的匹配方法包括:
7.根据权利要求6所述基于大语言模型的智能问答方法,其特征在于,所述资料匹配函数的创建方法包括:
8.根据权利要求1所述基于大语言模型的智能问答方法,其特征在于,还包括:
9.根据权利要求1所述基于大语言模型的智能问答方法,其特征在于,还包括:
10.根据权利要求1所述基于大语言模型的智能问答方法,其特征在于,还包括:
技术总结
本发明提供了一种基于大语言模型的智能问答方法,根据用户的私有数据在本地创建问答库和资料库;问答库包括多个标准问题以及关联的标准答案;资料库包括多个标准段落;根据问题查询问答库和/或资料库;当问答库中存在与问题匹配的标准问题时,输出问答库中标准问题关联的标准答案,作为问题的答案;获取资料库中与问题匹配的标准段落,将标准段落和问题输入至大语言模型中;当大语言模型输出的答案与问题匹配时,可定义答案为问题的标准答案,加入问答库。该方法根据用户的私有数据创建问答库和资料库,并结合大语言模型共同完成智能问答,克服了部分领域公开的现成数据较少,大模型在该领域训练不充分,导致大模型在该领域精准度低的缺陷。
技术研发人员:朱太和,晏士康
受保护的技术使用者:北京智慧火种科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!