一种基于知识图谱和大语言模型的问答方法和系统与流程
本发明涉及自然语言处理,尤其涉及一种基于知识图谱和大语言模型的问答方法和系统。
背景技术:
1、现有技术中,单纯使用大语言模型,模型中的信息通常是以非结构化的方式存在,难以进行有效的组织和查询。无法将信息进行结构化表示,也无法将信息进行连接和整合,甚至无法解决信息碎片化的问题。
2、此外,传统基于知识图谱中的问答系统往往缺乏对上下文的理解能力,无法根据上下文信息进行准确的回答。而基于大语言模型的系统可通过对上下文的建模和语义理解,实现对上下文的感知和理解,从而提供更准确和连贯的回答。此外,仅使用大语言模型还面临着知识更新和扩展的困难,难以跟上知识的更新和变化,无法基于快速迭代的领域知识进行关联性回答,无法提供知识上下文以形成更加专业有效的答案。
3、因此,有必要提供一种基于知识图谱和大语言模型的问答方法,以解决上述问题。
技术实现思路
1、本发明意在提供一种基于知识图谱和大语言模型的问答方法和系统,以解决现有技术中现有模型无法基于快速迭代的领域知识进行关联性回答,无法实时更新知识、支持知识间关联的特性,无法提供知识上下文信息以形成更加专业有效的答案等的技术问题,本发明要解决的技术问题通过以下技术方案来实现。
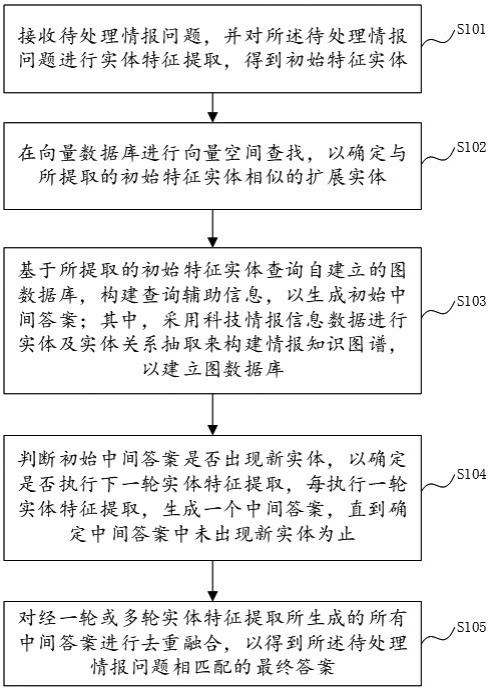
2、本发明第一方面提出一种基于知识图谱和大语言模型的问答方法,包括:采用历史科技情报信息数据进行实体及实体关系抽取来构建情报知识图谱,以建立图数据库;接收待处理情报问题,并对所述待处理情报问题进行实体特征抽取,得到初始特征实体;在向量数据库进行向量空间查找,以确定与所抽取的初始特征实体相似的扩展实体;基于所抽取的初始特征实体查询自建立的图数据库,构建查询辅助信息,以生成初始中间答案;判断初始中间答案是否出现新实体,以确定是否执行下一轮实体特征抽取,每执行一轮实体特征抽取,生成一个中间答案,直到确定中间答案中未出现新实体为止;对经一轮或多轮实体特征抽取所生成的所有中间答案进行去重融合,以得到所述待处理情报问题相匹配的最终答案。
3、根据可选的实施方式,所述判断初始中间答案是否出现新实体,以确定是否执行下一轮实体特征抽取,包括:在判断初始中间答案出现新实体时,利用pagerank算法,计算所出现的新实体在初始中间答案中的关键度;在所计算的新实体在初始中间答案中的关键度大于预定阈值时,根据新实体与初始特征实体之间的关系,进行关系检索;在所计算的新实体在初始中间答案中的关键度小于等于预定阈值时,将待处理情报问题继续生成带有上下文信息的问题,以生成中间答案,具体包括:将新实体及其上下文信息传递给辅助信息生成模版,采用辅助信息生成模版生成辅助信息,以生成中间答案。
4、根据可选的实施方式,基于lora算法微调和基于transformer架构形成的大语言模型,构建问答预测模型;采用辅助信息生成模版,使用初始特征实体及相关实体生成辅助信息,将所生成的辅助信息和待处理情报问题作为输入数据,输入所构建的问答预测模型,得到中间答案。
5、根据可选的实施方式,所述每执行一轮实体特征抽取,生成一个中间答案,直到确定中间答案中未出现新实体为止,包括:在确定中间答案中未出现新实体时,停止实体特征抽取,使用摘要生成算法对所生成的所有中间答案进行去除重复处理,并进行文本总结得到最终答案。
6、根据可选的实施方式,进一步包括:根据历史情报信息文本,构建知识库;基于知识库进行实体间关系抽取,形成情报实体关系三元组,以建立情报知识图谱。
7、根据可选的实施方式,进一步包括:将知识库中的各实体转换为实体特征向量,采用实体标识建立各实体与及各自对应的实体向量之间的映射关系,以建立向量数据库。
8、根据可选的实施方式,采用局部敏感哈希算法,建立向量数据库,具体包括执行以下步骤:对历史情报信息相关实体以及所建立的情报信息知识图谱中实体所转换得到的向量数据进行预处理操作,该预处理操作包括标准化、归一化;根据预处理后的实体向量数据,构建多个哈希函数,所述多个哈希函数将实体向量数据映射到一个或多个哈希桶中,以得到一个或多个哈希桶集合。
9、根据可选的实施方式,所述在向量数据库中进行向量空间查找,以确定与所抽取的初始特征实体相似的扩展实体,包括:将所抽取的初始特征实体转换成初始特征向量;在向量数据库中进行向量空间查找与初始特征向量的相似度大于指定值的向量数据,以确定初始特征实体的扩展实体。
10、根据可选的实施方式,进一步包括:根据所确定的扩展实体,在图数据库中进行检索查找,确定与扩展实体最相关的目标实体;采用辅助信息生成模版,使用扩展实体、目标实体生成辅助信息,以生成中间答案。
11、本发明第二方面提供一种基于知识图谱和大语言模型的问答系统,包括:接收处理模块,接收待处理情报问题,并对所述待处理情报问题进行实体特征抽取,得到初始特征实体;查找确定模块,在向量数据库进行向量空间查找,以确定与所抽取的初始特征实体相似的扩展实体;构建生成模块,基于所抽取的初始特征实体查询自建立的图数据库,构建查询辅助信息,以生成初始中间答案;判断确定模块,判断初始中间答案是否出现新实体,以确定是否执行下一轮实体特征抽取,每执行一轮实体特征抽取,生成一个中间答案,直到确定中间答案中未出现新实体为止;去重融合模块,对经一轮或多轮实体特征抽取所生成的所有中间答案进行去重融合,以得到所述待处理情报问题相匹配的最终答案。
12、本发明实施例包括以下优点:
13、与现有技术相比,本发明通过对待处理情报问题进行实体识别、实体特征化,采用图数据库和向量数据库配合查询,具体通过向量空间查找,配合自构建的情报知识图谱的节点查询及重要度计算,利用辅助信息生成模版生成辅助信息,以生成中间答案;通过对经一轮或多轮实体特征抽取所生成的所有中间答案进行去重融合,以得到所述待处理情报问题相匹配的最终答案,通过去重和文本融合,能够从海量的答案文本中高效地抽取和利用知识,能够为用户提供准确、完整、有效的答案。
14、此外,在确定中间答案中未出现新实体时,停止实体特征抽取,使用摘要生成算法对所生成的所有中间答案进行去除重复处理,并进行文本总结得到最终答案,能够得到更准确、更有效的答案。
技术特征:
1.一种基于知识图谱和大语言模型的问答方法,其特征在于,包括:
2.根据权利要求1所述的基于知识图谱和大语言模型的问答方法,其特征在于,所述判断初始中间答案是否出现新实体,以确定是否执行下一轮实体特征抽取,包括:
3.根据权利要求1所述的基于知识图谱和大语言模型的问答方法,其特征在于,
4.根据权利要求1所述的基于知识图谱和大语言模型的问答方法,其特征在于,所述每执行一轮实体特征抽取,生成一个中间答案,直到确定中间答案中未出现新实体为止,包括:
5.根据权利要求1所述的基于知识图谱和大语言模型的问答方法,其特征在于,进一步包括:
6.根据权利要求5所述的基于知识图谱和大语言模型的问答方法,其特征在于,进一步包括:
7.根据权利要求5所述的基于知识图谱和大语言模型的问答方法,其特征在于,
8.根据权利要求1所述的基于知识图谱和大语言模型的问答方法,其特征在于,所述在向量数据库中进行向量空间查找,以确定与所抽取的初始特征实体相似的扩展实体,包括:
9.根据权利要求8所述的基于知识图谱和大语言模型的问答方法,其特征在于,进一步包括:
10.一种基于知识图谱和大语言模型的问答系统,其特征在于,包括:
技术总结
本发明属于自然语言处理技术领域,提供一种基于知识图谱和大语言模型的问答方法和系统。该方法包括:接收待处理情报问题,进行实体特征抽取,得到初始特征实体;在向量数据库进行向量空间查找,确定扩展实体;基于初始特征实体查询自建立的图数据库,构建查询辅助信息,以生成初始中间答案;判断初始中间答案是否出现新实体,以确定是否执行下一轮实体特征抽取,每执行一轮实体特征抽取,生成一个中间答案,直到确定中间答案中未出现新实体为止;对经一轮或多轮实体特征抽取所有中间答案进行去重融合,以得到所述待处理情报问题相匹配的最终答案。本发明能够从海量的答案文本中高效地抽取和利用知识,能够为用户提供准确、完整、有效的答案。
技术研发人员:张昊,岳一峰,范嘉薇,任祥辉
受保护的技术使用者:中国电子科技集团公司第十五研究所
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!