基于Lambda架构的实时数据融合处理系统及方法与流程
本公开涉及数据融合处理,尤其涉及一种基于lambda架构的实时数据融合处理系统、方法和电子设备。
背景技术:
1、现有技术中实时数据的融合需要依赖外部的实时计算框架。
2、以附图1所示的flink计算框架为例,在flink运行时涉及到的进程主要有以下两个:
3、jobmanager:主要负责调度task,协调checkpoint已经错误恢复等。当客户端将打包好的任务提交到jobmanager之后,jobmanager就会根据注册的taskmanager资源信息将任务分配给有资源的taskmanager,然后启动运行任务。
4、taskmanger从jobmanager获取task信息,然后使用slot资源运行task;taskmanager:执行数据流的task,一个task通过设置并行度,可能会有多个subtask。每个taskmanager都是作为一个独立的jvm进程运行的。
5、因此,从flink计算框架来看,flink计算框架存在门槛高、运维复杂、稳定性挑战大,需要额外的服务器资源等问题。flink计算框架的数据更新,其需要进行多交叉的数据传输,增加了不必要的数据传输和存储,效率较低。
6、此外,flink计算框架虽然支持多源数据集的融合,鉴于其复杂且交叉的计算架构,只能针对少量级别的数据集进行融合计算,无法适应高维度的数据集融合计算,在融合数据时无法提供更好地聚合策略,灵活性比较低。
技术实现思路
1、为了解决上述问题,本申请提出一种基于lambda架构的实时数据融合处理系统、方法和电子设备。
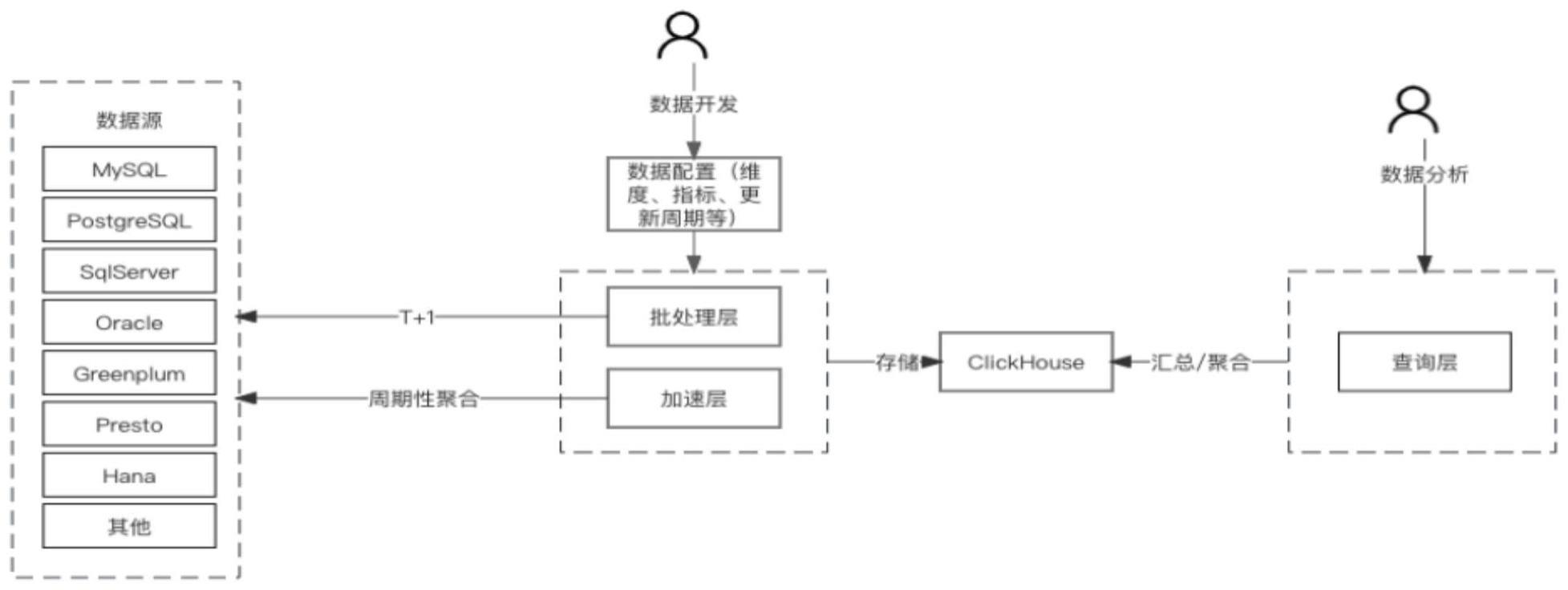
2、本申请一方面,提出一种基于lambda架构的实时数据融合处理系统,包括:
3、基于lambda架构的批处理层,用于通过时间维度的一次聚合,对在数据集上预先聚合好实时查询所需要的若干数据源的历史数据进行预计算,并将批处理结果发送并存储在olap分布式列式数据库中;
4、基于lambda架构的加速层,用于通过时间维度的一次聚合,对最新的实时增量数据进行处理计算,将最新的实时增量数据聚合到分钟级粒度,并将加速计算结果发送并存储在olap分布式列式数据库中;
5、olap分布式列式数据库,用于大数据存储和查询;
6、查询层,用于生成sql并发送至所述olap分布式列式数据库,对存储在olap分布式列式数据库中的批处理结果和加速计算结果进行合并处理,并通过sql查询所需要的展示数据。
7、作为本申请的一可选实施方案,可选地,在所述加速层中,对最新的实时增量数据进行聚合的方式为:
8、从不同数据源处获取当前周期最新的实时增量数据;
9、根据各个实时增量数据的sql时间函数,将同一时间段内的所述实时增量数据统一转换为所述sql时间函数中最近的时间区间;
10、对相同时间区间中的所述实时增量数据进行聚合;
11、聚合完毕,得到不同时间区间的若干增量聚合数据。
12、作为本申请的一可选实施方案,可选地,所述sql时间函数的时间区间,按照分钟级的时间区间对时间段进行分区划分;
13、对相同时间区间中的所述实时增量数据进行聚合之后,聚合得到分钟级粒度的增量聚合数据。
14、作为本申请的一可选实施方案,可选地,所述olap分布式列式数据库,为clickhouse数据库。
15、作为本申请的一可选实施方案,可选地,所述批处理层采用t+1的方式,从数据源处以批处理方式获得实时查询所需要的若干数据源的历史数据,返回并存储在所述clickhouse数据库中;
16、t为上一期。
17、作为本申请的一可选实施方案,可选地,所述加速层采用周期性聚合的获取方式,从数据源处以周期性增量获取方式获得实时查询所需要的实时增量数据,返回并存储在所述clickhouse数据库中。
18、作为本申请的一可选实施方案,可选地,所述查询层的查询方式:
19、用户通过所述查询层生成查询需要的sql指令;
20、将所述sql指令发送至所述clickhouse数据库;
21、在所述clickhouse数据库中,根据所述sql指令,找到查询所需要的所述批处理结果和所述加速计算结果,并进行合并,得到分钟级粒度的展示数据;
22、将所述展示数据返回至用户。
23、本申请另一方面,提出一种基于lambda架构的实时数据融合处理方法,包括如下步骤:
24、在数据集上预先聚合好实时查询所需要的若干数据源的历史数据;
25、基于lambda架构的批处理层,通过时间维度的一次聚合,对在数据集上预先聚合好实时查询所需要的若干数据源的历史数据进行预计算,并将批处理结果发送并存储在olap分布式列式数据库中;
26、基于lambda架构的加速层,通过时间维度的一次聚合,对最新的实时增量数据进行处理计算,将最新的实时增量数据聚合到分钟级粒度,并将加速计算结果发送并存储在olap分布式列式数据库中;
27、通过查询层生成sql并发送至所述olap分布式列式数据库,对存储在olap分布式列式数据库中的批处理结果和加速计算结果进行合并处理,并通过sql查询所需要的展示数据。
28、本申请另一方面,还提出一种电子设备,包括:
29、处理器;
30、用于存储处理器可执行指令的存储器;
31、其中,所述处理器被配置为执行所述可执行指令时实现所述的一种基于lambda架构的实时数据融合处理方法。
32、本发明的技术效果:
33、本申请通过在批处理层和加速层,设置有聚合策略,通过时间维度的一次聚合,将数据量聚合到分钟级粒度。这部分数据往往是周期性、增量地获取。查询层合并批处理层和加速层中的结果数据集,使之成为最终展示数据。利用查询层生成sql,合并批处理层和加速层的数据,查询clickhouse得到展示数据,可以实现分钟级的实时数据更新。
34、本方案采用lambda架构,批处理数据与实时数据分开处理,可以实现分钟级别的实时更新。支持多数据源的实时融合,数据存储在系统内置的clickhouse数据库内,可以实现分钟级的实时数据更新。对实时数据在时间维度进行聚合后,再周期性获取。减少了不必要的数据传输和存储,提高了效率。
35、根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
技术特征:
1.一种基于lambda架构的实时数据融合处理系统,其特征在于,包括:
2.根据权利要求1所述的一种基于lambda架构的实时数据融合处理方法,其特征在于,在所述加速层中,对最新的实时增量数据进行聚合的方式为:
3.根据权利要求2所述的一种基于lambda架构的实时数据融合处理方法,其特征在于,所述sql时间函数的时间区间,按照分钟级的时间区间对时间段进行分区划分;
4.根据权利要求1所述的一种基于lambda架构的实时数据融合处理系统,其特征在于,所述olap分布式列式数据库,为clickhouse数据库。
5.根据权利要求4所述的一种基于lambda架构的实时数据融合处理系统,其特征在于,所述批处理层采用t+1的方式,从数据源处以批处理方式获得实时查询所需要的若干数据源的历史数据,返回并存储在所述clickhouse数据库中;
6.根据权利要求4所述的一种基于lambda架构的实时数据融合处理系统,其特征在于,所述加速层采用周期性聚合的获取方式,从数据源处以周期性增量获取方式获得实时查询所需要的实时增量数据,返回并存储在所述clickhouse数据库中。
7.根据权利要求1所述的一种基于lambda架构的实时数据融合处理系统,其特征在于,所述查询层的查询方式:
8.一种基于lambda架构的实时数据融合处理方法,其特征在于,包括如下步骤:
9.一种电子设备,其特征在于,包括:
技术总结
本申请涉及一种基于Lambda架构的实时数据融合处理系统及方法,在批处理层和加速层设置聚合策略,通过时间维度的一次聚合,将数据量聚合到分钟级粒度。查询层合并批处理层和加速层中的结果数据集,使之成为最终展示数据。利用查询层生成sql,合并批处理层和加速层的数据,查询ClickHouse得到展示数据,可以实现分钟级的实时数据更新。采用Lambda架构,批处理数据与实时数据分开处理,可以实现分钟级别的实时更新。支持多数据源的实时融合,数据存储在系统内置的ClickHouse数据库内,可以实现分钟级的实时数据更新。对实时数据在时间维度进行聚合后,再周期性获取。减少了不必要的数据传输和存储,提高效率。
技术研发人员:史栋,李迪砺,严林刚,吴宝琪
受保护的技术使用者:杭州观远数据有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!