基于人工智能的数据安全获取方法
本申请涉及网络抓取,尤其涉及一种基于人工智能的数据安全获取方法。
背景技术:
1、网络数据是指通过互联网传输或存储的各种类型的数据,如文本、图片等。网络数据的发现和测绘是指利用网络爬虫、搜索引擎等工具,从互联网上获取和分析网络数据的过程。网络数据的发现和测绘是基础的网络工具,可以用于网络监控和网络分析等领域。
2、然而,在一些应用场景下,需要对全网的网络数据进行获取和监控,例如版权侵犯的全网监控。在这种场景下,若直接对全网的网络数据进行获取,获取数据并进行监控的数据获取方容易出现网络和数据安全的问题。
3、因此,如何安全有效地进行全网网络数据的发现和测绘,是当前亟待解决的技术问题。
技术实现思路
1、为了解决上述技术问题或者至少部分地解决上述技术问题,本申请提供了一种基于人工智能的数据安全获取方法,可以更安全有效率地进行全网网络数据的发现和测绘。
2、本申请提供了一种基于人工智能的数据安全获取方法,包括:
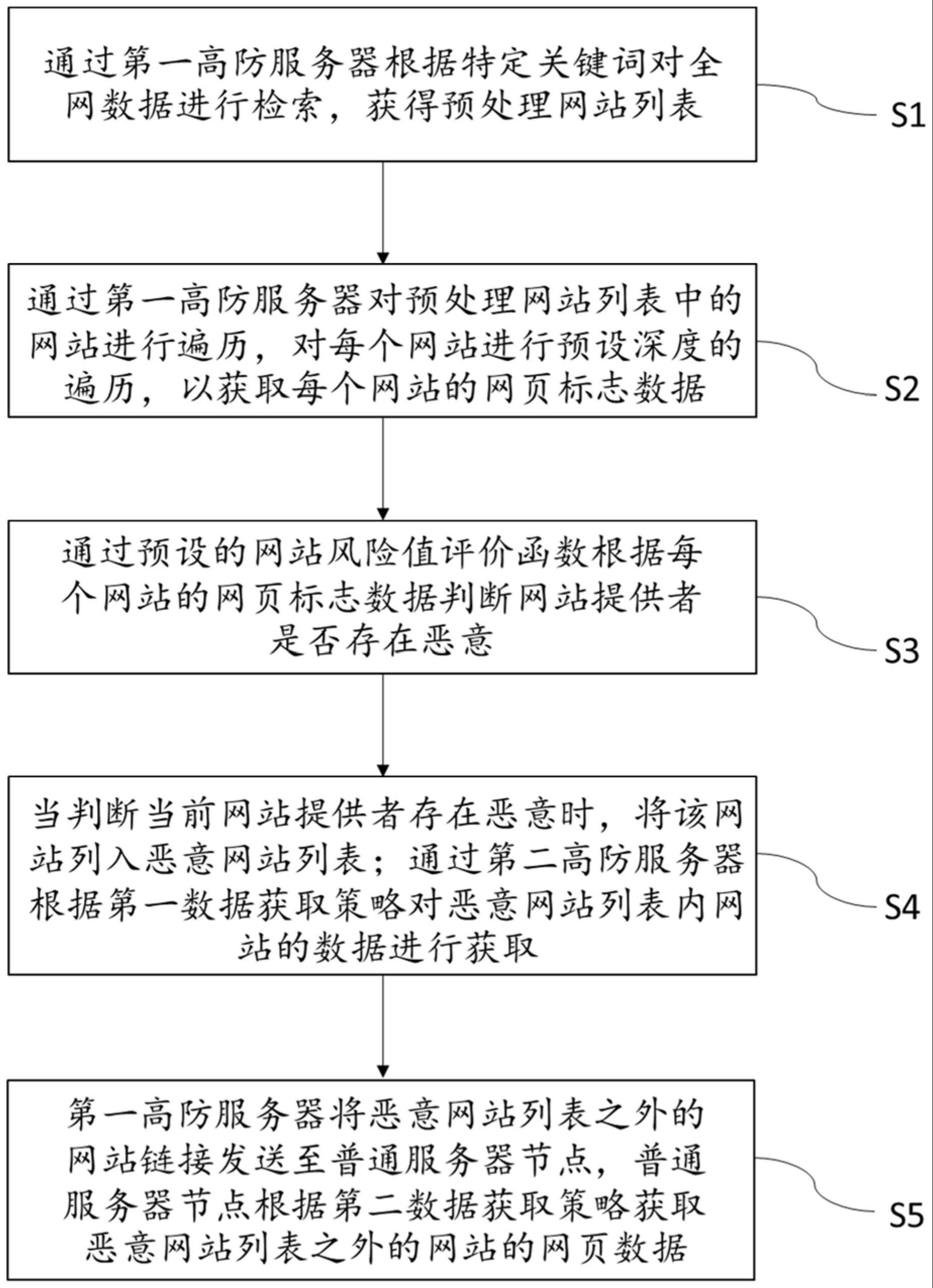
3、通过第一高防服务器根据特定关键词对全网数据进行检索,获得预处理网站列表;
4、通过第一高防服务器对预处理网站列表中的网站进行遍历,对每个网站进行预设深度的遍历,以获取每个网站的网页标志数据,通过预设的网站风险值评价函数根据每个网站的网页标志数据判断网站提供者是否存在恶意;
5、当判断当前网站提供者存在恶意时,将该网站列入恶意网站列表;
6、通过第二高防服务器根据第一数据获取策略对恶意网站列表内网站的数据进行获取。
7、可选的,第一高防服务器将恶意网站列表之外的网站链接发送至普通服务器节点,普通服务器节点根据第二数据获取策略获取恶意网站列表之外的网站的网页数据,所述第二数据获取策略的数据获取速度大于第一数据获取策略的数据获取速度。
8、可选的,根据每个网站的网页标志数据通过预设的网站风险值评价函数判断网站内容提供者是否存在恶意,包括:
9、从所述网页标志数据中获取当前网站预设深度内的图片资源,通过预设的不良图片识别模型,对所述预设深度内的图片资源中的图片进行识别以得到当前网站中不良图片的特征数量;
10、从所述网页标志数据中获取当前网站的弹窗指令,记录弹窗指令的数量;从所述网页标志数据中获取当前网站的自跳转指令,记录自跳转指令的数量;
11、从所述网页标志数据中获取当前网站的网页平均加载时间;
12、所述预设的网站风险值评价函数包括:
13、
14、其中w1为不良图片权重;k1为不良图片系数;count1为不良图片的特征数量;w2为弹窗权重;k2为弹窗系数;count2为弹窗指令的数量;w3为自跳转权重;k3为自跳转系数;count3为自跳转指令的数量;w4为网页平均加载时间权重,tload为网页平均加载时间;
15、将当前网站的不良图片的数量、弹窗指令的数量、自跳转指令的数量和网页平均加载时间输入网站风险值评价函数中,以得到当前网站的网站风险值,在当前网站的网站风险值大于预设风险值时判定网站提供者存在恶意。
16、可选的,弹窗指令或自跳转指令在越浅的网页深度中首次出现时,k2或k3的值就越大。
17、可选的,还包括:
18、获取弹窗中的图片资源,利用不良图片识别模型对弹窗中的图片资源的图片进行识别,获得不良弹窗数量;获取自跳转指令对应网页中的图片资源,利用不良图片识别模型对自跳转链接中的图片进行识别,获得不良自跳转数量;
19、所述count2为弹窗指令数量和不良弹窗数量的总和,所述count3为自跳转指令数量和不良自跳转数量的总和;
20、将判断为恶意网站的弹窗的图片资源和自跳转指令对应网页中的图片资源对不良图片识别模型进行迁移学习,以得到针对特定关键词得到的全网信息判断更为准确的不良图片识别模型。
21、可选的,所述通过第二高防服务器根据第一数据获取策略对恶意网站列表内网站的数据进行获取包括:
22、第二高防服务器获取对应网站内的网页,并通过预设的网页结构排序方法获取对应网站内网页爬取优先度,根据所述网页爬取优先度对网站内的网页数据进行异步爬取以获取得到网页文字资源和网页图片资源;
23、对获取到的图片资源进行点阵化处理得到网页图片转译资源;
24、第二高防服务器将所述网页文字资源和网页图片转译资源发送至数据库。
25、可选的,通过预设的网页结构排序方法获取对应网站内网页爬取优先度,包括:
26、获取网站内的所有网页链接和网页链接关系,所述网页链接关系包括网页间临接的关系和网页内出度,所述网页内出度指的是该网页指向该网站中其他网页的数量;
27、对每个网页权重进行初始化,所述每个网页的初始权重为1/网页总数;
28、根据网页权重计算函数对网页权重进行迭代更新,直到两次迭代之间权重的变化小于预设变化值,将更新后的每个网页权重作为每个网页的网页爬取优先度,所述网页权重计算函数为:
29、
30、其中ui是网页i,uj是网页j,w(ui)为网页i的权重值,w(uj)为网页j的权重值,θ是经验系数,l(uj)为网页j的网页内出度,是与网页i临接的网页集合,m是所有网页的总数。
31、可选的,所述根据第二数据获取策略对恶意网站列表之外的网站的数据进行获取,包括:
32、普通服务器节点遍历网站内的所有网页以获得网页文字资源和网页图片资源;
33、普通服务器节点将获取到的网页文字资源和网页图片资源直接发送至数据库进行保存。
34、本申请提供的技术方案与现有技术相比具有如下优点:
35、在全网网络数据的发现和测绘的过程中,尤其是网络提供者涉及侵权等违规违法行为的情况下,对这些网站进行的网络数据进行收集时,一方面,容易收集到伪装成图片的木马程序,另一方面,这类的网站提供者有很大可能向访问网站的主机实施网络攻击以进行网络敲诈,可能造成执行网络信息收集的主机网络瘫痪或者数据库遭到注入,危及收集网络信息的主机的网络安全和数据安全。
36、本申请提供的基于人工智能的数据安全获取方法,能够在执行整个网站的网页数据的爬取之前,首先通过评估网站的网站风险值从而确定网站提供者是否存在恶意,针对有恶意的网络提供者,通过特定的数据采集策略从而实现更安全的收集网页数据。
37、因此本申请提供了一种基于人工智能的数据安全获取方法,可以更安全有效率地进行全网网络数据的发现和测绘。
技术特征:
1.基于人工智能的数据安全获取方法,其特征在于,包括:
2.根据权利要求1所述的基于人工智能的数据安全获取方法,其特征在于,第一高防服务器将恶意网站列表之外的网站链接发送至普通服务器节点,普通服务器节点根据第二数据获取策略获取恶意网站列表之外的网站的网页数据,所述第二数据获取策略的数据获取速度大于第一数据获取策略的数据获取速度。
3.根据权利要求1所述的基于人工智能的数据安全获取方法,其特征在于,根据每个网站的网页标志数据通过预设的网站风险值评价函数判断网站内容提供者是否存在恶意,包括:
4.根据权利要求3所述的基于人工智能的数据安全获取方法,其特征在于,弹窗指令或自跳转指令在越浅的网页深度中首次出现时,k2或k3的值就越大。
5.根据权利要求3所述的基于人工智能的数据安全获取方法,其特征在于,还包括:
6.根据权利要求1所述的基于人工智能的数据安全获取方法,其特征在于,所述通过第二高防服务器根据第一数据获取策略对恶意网站列表内网站的数据进行获取包括:
7.根据权利要求6所述的基于人工智能的数据安全获取方法,其特征在于,通过预设的网页结构排序方法获取对应网站内网页爬取优先度,包括:
8.根据权利要求2所述的基于人工智能的数据安全获取方法,其特征在于,所述根据第二数据获取策略对恶意网站列表之外的网站的数据进行获取,包括:
技术总结
本申请涉及网络抓取技术领域,尤其涉及一种基于人工智能的数据安全获取方法。基于人工智能的数据安全获取方法,包括:通过第一高防服务器根据特定关键词对全网数据进行检索,获得预处理网站列表;通过第一高防服务器对预处理网站列表中的网站进行遍历,对每个网站进行预设深度的遍历,以获取每个网站的网页标志数据,通过预设的网站风险值评价函数根据每个网站的网页标志数据判断网站提供者是否存在恶意;当判断当前网站提供者存在恶意时,将该网站列入恶意网站列表;通过第二高防服务器根据第一数据获取策略对恶意网站列表内网站的数据进行获取。本申请提供的数据安全获取方法可以更安全有效率地进行全网网络数据的发现和测绘。
技术研发人员:辛继胜
受保护的技术使用者:广东轻工职业技术学院
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!