对话篇章解析方法
本发明涉及自然语言处理,特别涉及一种对话篇章解析方法、一种计算机可读存储介质和一种计算机设备。
背景技术:
1、相关技术中,多人对话篇章解析是为了生成对话篇章结构解析树,从而辅助多种对话下游任务,如对话摘要、对话回复生成等;现有的篇章解析模型由预训练模型与参数随机初始化的解码器构成,由于额外引入的解码器需要足够多的数据进行训练,在训练数据有限的现实条件下,篇章解析模型规模的扩大无法带来性能的提升。
技术实现思路
1、本发明旨在至少在一定程度上解决上述技术中的技术问题之一。为此,本发明的一个目的在于提出一种对话篇章解析方法,能够将该任务建模为文本生成任务,避免引入额外解码器,仅通过预训练模型完成预测,从而能通过扩大模型规模有效提升模型性能。
2、本发明的第二个目的在于提出一种计算机可读存储介质。
3、本发明的第三个目的在于提出一种计算机设备。
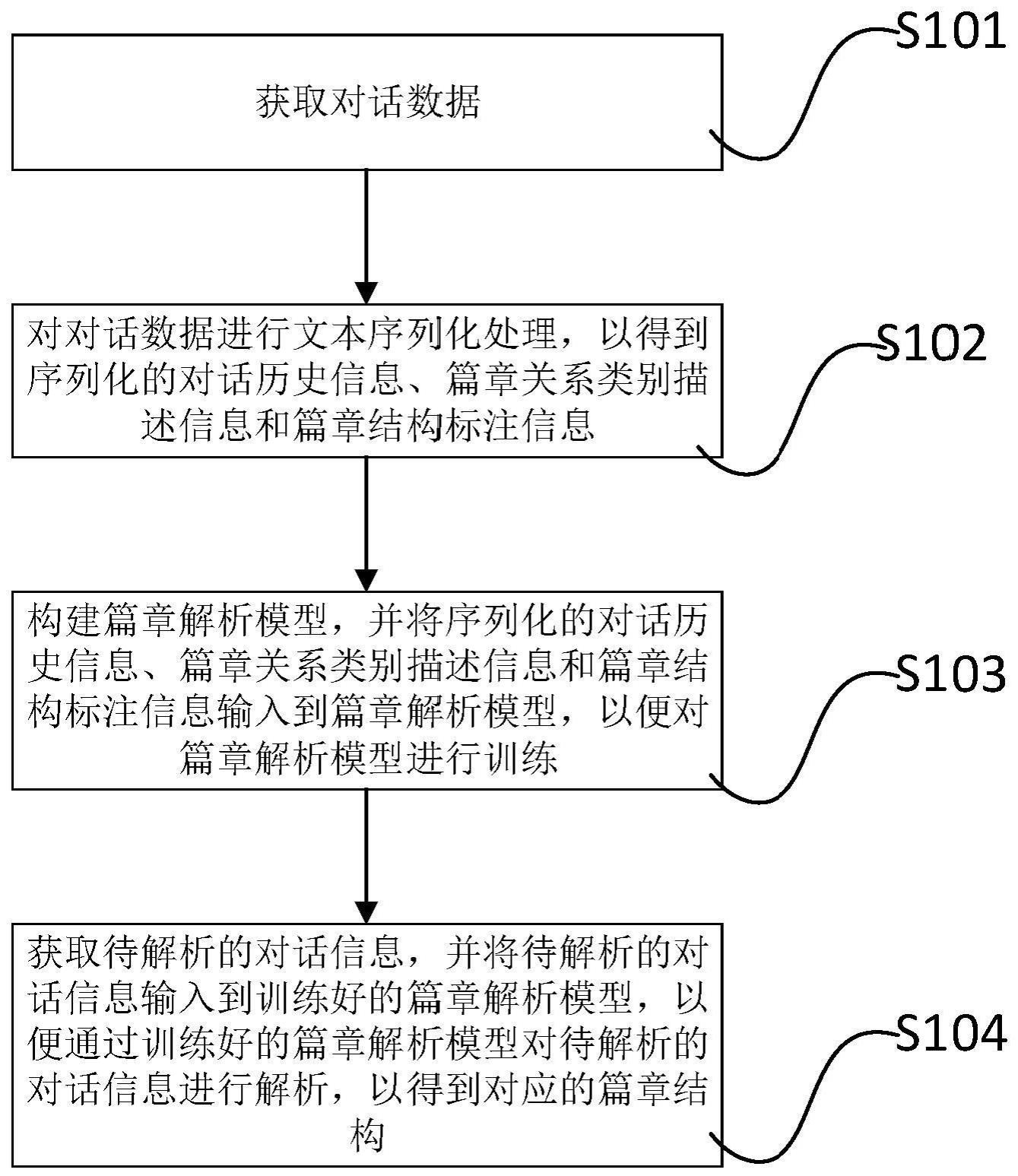
4、为达到上述目的,本发明第一方面实施例提出了一种对话篇章解析方法,包括以下步骤:获取对话数据;对所述对话数据进行文本序列化处理,以得到序列化的对话历史信息、篇章关系类别描述信息和篇章结构标注信息;构建篇章解析模型,并将所述序列化的对话历史信息、篇章关系类别描述信息和篇章结构标注信息输入到所述篇章解析模型,以便对所述篇章解析模型进行训练;获取待解析的对话信息,并将所述待解析的对话信息输入到训练好的篇章解析模型,以便通过所述训练好的篇章解析模型对所述待解析的对话信息进行解析,以得到对应的篇章结构。
5、根据本发明实施例的对话篇章解析方法,首先,获取对话数据;然后,对对话数据进行文本序列化处理,以得到序列化的对话历史信息、篇章关系类别描述信息和篇章结构标注信息;接着,构建篇章解析模型,并将序列化的对话历史信息、篇章关系类别描述信息和篇章结构标注信息输入到篇章解析模型,以便对篇章解析模型进行训练;最后,获取待解析的对话信息,并将待解析的对话信息输入到训练好的篇章解析模型,以便通过训练好的篇章解析模型对待解析的对话信息进行解析,以得到对应的篇章结构;由此,能够将该任务建模为文本生成任务,避免引入额外解码器,仅通过预训练模型完成预测,从而能通过扩大模型规模有效提升模型性能。
6、另外,根据本发明上述实施例提出的对话篇章解析方法还可以具有如下附加的技术特征:
7、可选地,在得到序列化的对话历史信息、篇章关系类别描述信息和篇章结构标注信息后,还对所述序列化的对话历史信息、篇章关系类别描述信息和篇章结构标注信息进行分词、大小写统一处理。
8、可选地,序列化的对话历史信息表示为:
9、t1,s1:u1t2,s2:u2…tn,sn:un
10、其中,tn表示当前轮次为第n轮;sn表示第n轮的对话人姓名或者编号;un表示第n轮的对话历史内容。
11、可选地,序列化的篇章关系类别描述信息包括依次拼接的关系类别和对应描述。
12、可选地,序列化的篇章结构标注信息表示为:
13、ti,tj:rij
14、其中,ti表示第i轮的对话ui对应的标识符;tj表示第j轮的对话uj对应的标识符;rij表示ui与uj之间的篇章关系类别;j<i,即i为当前轮。
15、可选地,序列化的篇章结构标注信息包括第一结构信息,所述第一结构信息仅预测当前轮次涉及的篇章关系。
16、可选地,序列化的篇章结构标注信息包括第二结构信息,所述第二结构信息不仅需要预测当前轮次涉及的篇章关系,还需要预测历史轮次中涉及的篇章关系。
17、可选地,在通过所述训练好的篇章解析模型对所述待解析的对话信息进行解析时,以约束解码的方式,预测满足任务约束的篇章结构。
18、为达到上述目的,本发明第二方面实施例提出了一种计算机可读存储介质,其上存储有对话篇章解析程序,该对话篇章解析程序被处理器执行时实现如上述的对话篇章解析方法。
19、根据本发明实施例的计算机可读存储介质,通过存储对话篇章解析程序,以使得处理器在执行该对话篇章解析程序时,实现如上述的对话篇章解析方法,由此,能够将该任务建模为文本生成任务,避免引入额外解码器,仅通过预训练模型完成预测,从而能通过扩大模型规模有效提升模型性能。
20、为达到上述目的,本发明第三方面实施例提出了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时,实现如上述的对话篇章解析方法。
21、根据本发明实施例的计算机设备,通过存储器对对话篇章解析程序进行存储,以使得处理器在执行该对话篇章解析程序时,实现如上述的对话篇章解析方法,由此,能够将该任务建模为文本生成任务,避免引入额外解码器,仅通过预训练模型完成预测,从而能通过扩大模型规模有效提升模型性能。
技术特征:
1.一种对话篇章解析方法,其特征在于,包括以下步骤:
2.如权利要求1所述的对话篇章解析方法,其特征在于,在得到序列化的对话历史信息、篇章关系类别描述信息和篇章结构标注信息后,还对所述序列化的对话历史信息、篇章关系类别描述信息和篇章结构标注信息进行分词、大小写统一处理。
3.如权利要求1所述的对话篇章解析方法,其特征在于,序列化的对话历史信息表示为:
4.如权利要求1所述的对话篇章解析方法,其特征在于,序列化的篇章关系类别描述信息包括依次拼接的关系类别和对应描述。
5.如权利要求1所述的对话篇章解析方法,其特征在于,序列化的篇章结构标注信息表示为:
6.如权利要求5所述的对话篇章解析方法,其特征在于,序列化的篇章结构标注信息包括第一结构信息,所述第一结构信息仅预测当前轮次涉及的篇章关系。
7.如权利要求5所述的对话篇章解析方法,其特征在于,序列化的篇章结构标注信息包括第二结构信息,所述第二结构信息不仅需要预测当前轮次涉及的篇章关系,还需要预测历史轮次中涉及的篇章关系。
8.如权利要求1所述的对话篇章解析方法,其特征在于,在通过所述训练好的篇章解析模型对所述待解析的对话信息进行解析时,以约束解码的方式,预测满足任务约束的篇章结构。
9.一种计算机可读存储介质,其特征在于,其上存储有对话篇章解析程序,该对话篇章解析程序被处理器执行时实现如权利要求1-8中任一项所述的对话篇章解析方法。
10.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时,实现如权利要求1-8中任一项所述的对话篇章解析方法。
技术总结
本发明公开了一种对话篇章解析方法,包括:获取对话数据;对对话数据进行文本序列化处理,以得到序列化的对话历史信息、篇章关系类别描述信息和篇章结构标注信息;构建篇章解析模型,并将序列化的对话历史信息、篇章关系类别描述信息和篇章结构标注信息输入到篇章解析模型,以便对篇章解析模型进行训练;获取待解析的对话信息,并将待解析的对话信息输入到训练好的篇章解析模型,以便通过训练好的篇章解析模型对待解析的对话信息进行解析,以得到对应的篇章结构;由此,能够将该任务建模为文本生成任务,避免引入额外解码器,仅通过预训练模型完成预测,从而能通过扩大模型规模有效提升模型性能。
技术研发人员:苏劲松,王安特,曾华琳
受保护的技术使用者:厦门大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!