一种基于决策树的OCR文本还原方法、设备及存储介质与流程
本发明涉及文字识别,特别涉及一种基于决策树的ocr文本还原方法、设备及存储介质。
背景技术:
1、为进一步提高文档信息的可访问性并方便管理,需要对文档进行文本内容识别,将图像和扫描图中的文本转换为可编辑、可搜索的文本。最早的文档识别技术就是基于ocr方法,它使用光学字符识别技术将文档中的文字提取出来。近年来,随着科学技术的快速发展,渐渐出现了基于深度学习的和基于计算机视觉的文档识别技术。基于深度学习的文档识别技术虽然在图像处理上有了显著进展,但需要大规模的数据集训练,并耗费大量的计算资源和时间。基于计算机视觉的文档识别技术在表格解析上已经被广泛应用,但它也需要消耗大量资源训练,并且对于特殊结构的表格仍可能发生解析错误或丢失部分信息。反观ocr技术具备较高的成熟度和稳定性,可用于多种类型文档,随着算法改进其识别结果准确度高,支持多种语言,还有许多商业和开源引擎可供选择。因此,当前ocr识别技术仍然是最常用的文档识别技术。
2、尽管ocr技术的识别准确性已经取得了显著的进步,但在文本较为复杂、模糊或扭曲的文本、低分辨率图像等具有挑战性的情况下,识别后的文本可能仍然无法完全保留原始文档的格式和布局,导致识别结果与原文不一致。这时后处理方法就会发挥作用:对于已知样式和模板的文档,可以根据样式规则和模板信息进行还原,但这种方法无法处理格式未知的文档。还可以通过自然语言处理技术,对ocr识别结果进行语义分析和实体识别,提取文本中的关键信息、命名实体、关系等,从而还原原始文档中的语义结构和信息,但这种方法需要耗费大量资源进行模型训练,还需要纳入特定领域的实体知识。所以,当前最常用的ocr文本后处理方法是文本布局分析法,通过分析ocr识别结果中文本块的相对位置关系,对多个文本框进行距离计算或聚类,来还原原始文档的布局结构。然而,目前许多文本布局分析法只关注了文本框的相对位置信息,却很少关注诸如字体、数字比例、特定关键字等其他特征。
3、针对现有研究情况,当前面向文档的ocr识别技术后处理方法有如下问题:
4、1.现有的后处理技术对所识别文本结构的还原能力较差,可能让文本被错误地分类或合并,影响识别结果地准确性和连续性;
5、2.缺乏对字体、数字比例、特定关键字等其他多种特征的关注。
技术实现思路
1、针对现有技术中存在的问题,提供了一种基于决策树的ocr文本还原方法、设备及存储介质,决策树分析文本框的多项特征,对文本框进行分类和合并,实现了文本还原,可以解决文本框被错误分类、排列或重叠的问题。
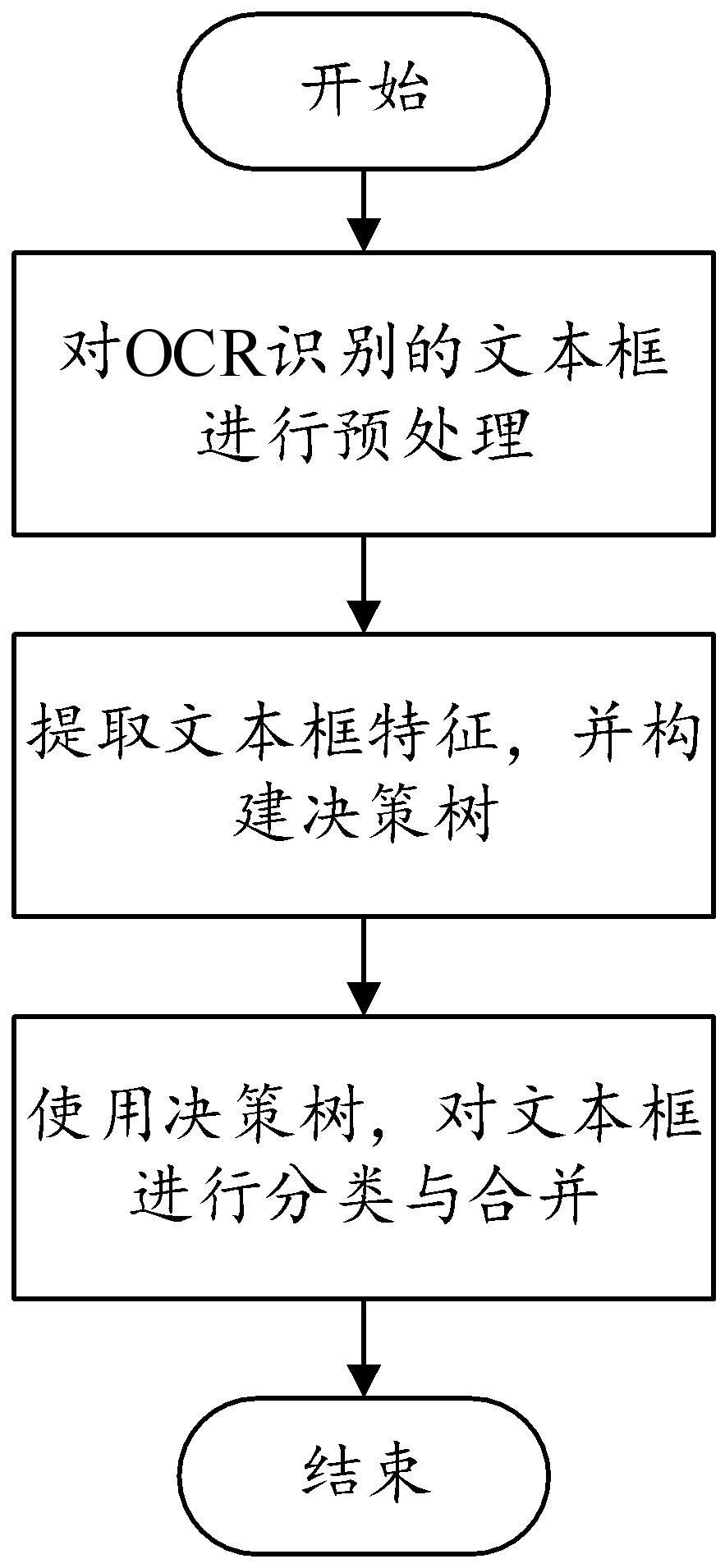
2、本发明采用的技术方案如下: 一种基于决策树的ocr文本还原方法,包括:
3、对ocr识别的文本框进行预处理;
4、提取文本框特征,并基于文本框特征构建决策树;
5、根据决策树,对文本框进行分类与合并,还原文本原始布局。
6、进一步的,所述预处理包括:
7、对每个文本框进行编号,记录其初始内容;
8、将文本框的所有英文字符转换为小写;
9、去除文本框中的特殊字符。
10、进一步的,所述特殊字符包括非数字、非字母、非中文、非标点、非空格的字符。
11、进一步的,所述提取文本框特征过程包括:
12、提取每个文本框的字数、行数以及在整个文档中的位置;
13、提取每个文本框的长度、宽度以及字体;
14、提取每个文本框中数字比例、字母比例以及包含的关键字。
15、进一步的,所述关键字为能表示文本框内容的含义的关键字,例如“图1”,“表2”,“1.1”“2.1”等。这些关键字的格式由专家根据经验制定,可通过正则表达式来识别。
16、进一步的,所述构建决策树包括:
17、根节点:判断是否包含关键字;是则根据关键字类型对文本框分类,包括:
18、章节节点判断:根据文本框的宽度、字体、关键字数量,细分章节等级;
19、图表节点判断;根据文本框的字体、位置、关键字特征,确定所属图表;
20、否则直接根据文本框长度、宽度、字体、位置等对文本框进行分类;
21、标题节点判断:文本框宽度最宽,处于页面中最高位置;
22、页码节点判断:若包含关键字“页”“page”,则其余内容均为数字,若不包含关键字,则全为数字;长度小于一行,处于页面中最高或最低位置;
23、段落节点判断:根据数字比例以及字母比例特征,确定段落类型。
24、进一步的,所述分类与合并过程包括:
25、将所有文本框按照决策树进行分类;
26、根据文本框编号,复原每个文本框的初始内容以及位置排布;
27、对同一类别内位置相邻、字体一致、宽度相同的文本框进行合并。
28、本发明第二方面提出了一种电子设备,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的计算机程序,所述处理器可执行所述计算机程序以实现上述的基于决策树的ocr文本还原方法。
29、本发明第三方面提出了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述的基于决策树的ocr文本还原方法。
30、与现有技术相比,采用上述技术方案的有益效果为:本发明关注了文本框除位置外的多项特征,使用决策树对文本框进行分类再合并,避免了位置相近的文本框被错误分类的情况,能够基于文本的不同类别进行针对性还原。
技术特征:
1.一种基于决策树的ocr文本还原方法,其特征在于,包括:
2.根据权利要求1所述的基于决策树的ocr文本还原方法,其特征在于,所述预处理包括:
3.根据权利要求2所述的基于决策树的ocr文本还原方法,其特征在于,所述特殊字符包括非数字、非字母、非中文、非标点、非空格的字符。
4.根据权利要求2或3所述的基于决策树的ocr文本还原方法,其特征在于,所述提取文本框特征过程包括:
5.根据权利要求4所述的基于决策树的ocr文本还原方法,其特征在于,所述关键字为能表示文本框内容的含义的关键字,通过正则表达式来识别。
6.根据权利要求4所述的基于决策树的ocr文本还原方法,其特征在于,所述构建决策树包括:
7.根据权利要求6所述的基于决策树的ocr文本还原方法,其特征在于,所述分类与合并过程包括:
8.一种电子设备,其特征在于,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的计算机程序,所述处理器执行所述计算机程序以实现权利要求1-7任一所述的基于决策树的ocr文本还原方法。
9.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1-7任一项所述的基于决策树的ocr文本还原方法。
技术总结
本发明提供了一种基于决策树的OCR文本还原方法、设备及存储介质,包括:对OCR识别的文本框进行预处理;提取文本框特征,并基于文本框特征构建决策树;根据决策树,对文本框进行分类与合并,还原文本原始布局。本发明针对OCR的识别结果进行后处理,通过应用决策树分析文本框的多项特征,识别文本框内容类别:如标题、章节、页码、段落等,然后进行分类与合并,以还原文本的原始布局,避免了OCR识别结果中的文本框被错误分类、排列或重叠的情况,解决了文本内容不连贯、文本的格式和布局容易错乱的问题。
技术研发人员:刘法,白建亮,阎德劲,郑大安,雷文强,向元新,熊可欣,袁焦,丁栋威,邓欣,顾海燕,奂锐,谢明华,孙国东
受保护的技术使用者:中国电子科技集团公司第十研究所
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!