基于多头注意力机制的DeecpCFR算法优化方法
:本发明涉及机器博弈领域,尤其涉及一种使用多头注意力机制提高算法的收敛速度。
背景技术
0、
背景技术:
1、目前,人工智能领域的机器博弈涵盖了完备信息博弈和非完备信息博弈。虽然在解决完备信息博弈方面取得了显著进展,但如今的主要关注点转向了非完备信息博弈,其中纸牌游戏是其中的典型代表。这些纸牌游戏具有广泛的决策空间、长期规划和多人参与等特点。
2、deepcfr是一种反事实遗憾最小化(cfr)算法的变体,它利用神经网络来近似cfr在游戏中的行为,通过避免对整个博弈树进行详尽遍历来节省大量的时间和空间。然而,deepcfr的神经网络设计在特征提取方面存在挑战。为了克服这些限制,研究者提出了多种替代方法,例如采用更复杂的神经网络架构或不同的策略评估方法,以增强算法的决策能力。
3、然而,现有技术在处理复杂的非完备信息博弈时仍存在问题。这些问题包括特征提取的困难,改善行动的权重分配以及收敛速度的较慢。因此,需要一种更加高效和准确的方法来解决这些问题,以提高在非完备信息博弈中收敛速度。
技术实现思路
0、
技术实现要素:
1、本发明的目的增强算法的表征能力,改进特征提取过程,并使其更接近纳什均衡。为此,本发明的一个目的在于提出一种基于多头注意力机制的deepcfr算法优化方法,该方法包括以下步骤:
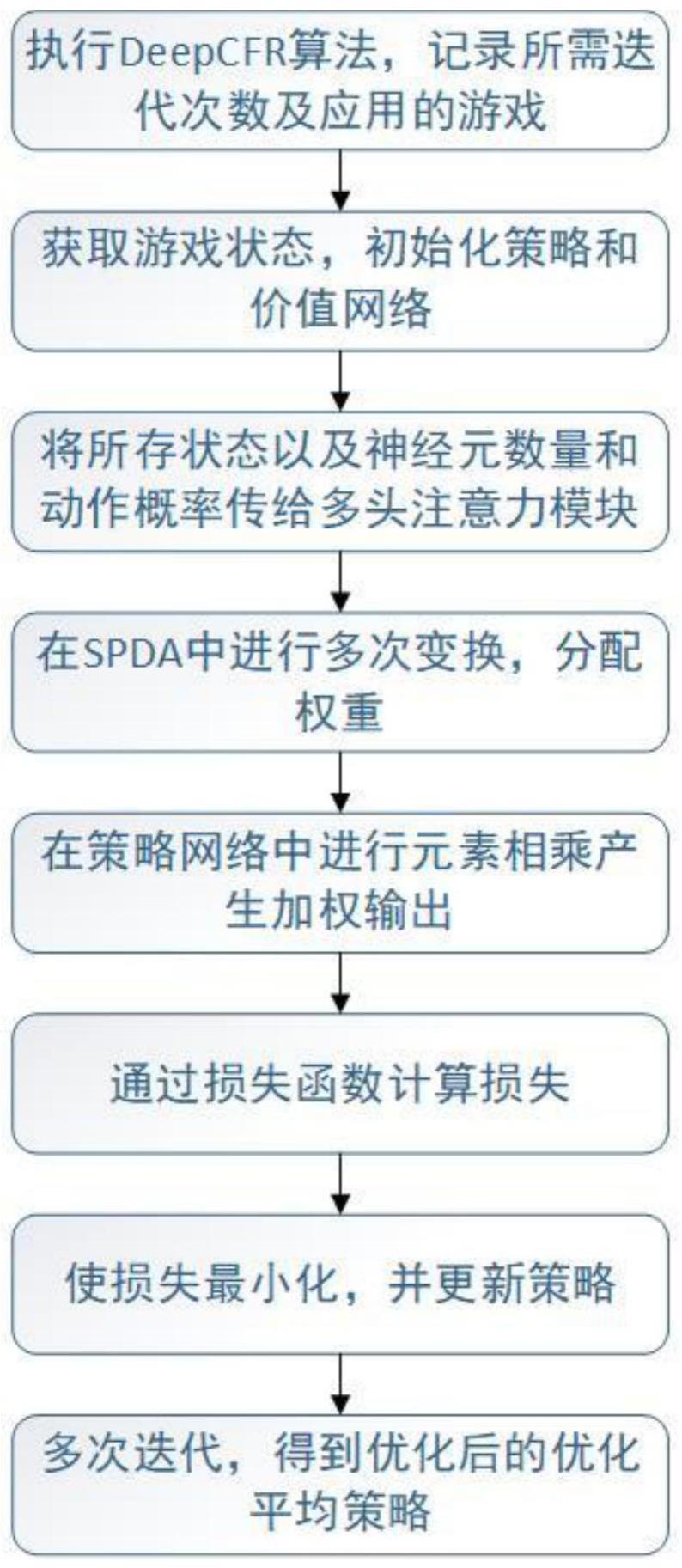
2、步骤1执行deepcfr算法,记录需要运行的迭代次数t以及训练所使用的游戏;
3、步骤2获取游戏状态,并初始化策略网络和价值网络,用于生成玩家在每个信息集中采取动作的概率分布及收益;
4、步骤3将步骤2中的内容以及神经元个数和每个动作概率传递给多头注意力模块;
5、步骤4在多头注意力模块中,将步骤3的内容在scaled dot-product attention(spda)中进行多次变换和加权计算,同时进行线性变换以计算不同行动的权重,最终输出每个动作的预测优势。即完成了算法在信息集中自动学习不同位置的相关性和重要性,加强了状态特征的表征能力,以代替完整的cfr遍历;
6、步骤5将步骤4中的输入策略网络,并与行动概率进行元素相乘产生最终的加权输出;
7、步骤6将步骤5中的加权动作概率与实际动作概率之间的损失通过损失函数计算其之间的损失;
8、步骤7将算法进行迭代,根据策略网络和价值网络的输出,使用cfr算法使步骤6中的损失最小化,并更新策略网络与价值网络的参数;
9、步骤8当t<t时,重复重复步骤3-步骤7,使其达到一种近似纳什均衡,实现更低的可利用度其中,t为目前迭代次数。当t=t时,获得平均策略。
10、本发明旨在提供一种优化的deepcfr算法,通过将多头注意力机制融入网络架构,从而增强算法的表征能力,改进特征提取过程,并使其更接近纳什均衡,并更快地收敛到最优解。该发明旨在解决现有技术中存在的特征提取困难、决策能力限制和收敛速度慢的问题。通过将多头注意力机制与deepcfr算法结合,本发明将为非完备信息博弈提供一种更高效、准确和优化的决策方法。
技术特征:
1.基于多头注意力机制的deepcfr算法优化方法,其特征在于该方法包括以下步骤:
2.根据权利要求1所述的基于多头注意力机制的deepcfr算法优化其特征在于,步骤4中的多头注意力公式如下:
3.根据权利要求1所述的基于多头注意力机制的deepcfr算法优化其特征在于,步骤6中步骤5中的加权动作概率与实际动作概率之间的损失通过损失函数计算其之间的损失。其损失函数为:其中n为信息集中的动作数量;prw从多头注意力中获得的加权动作概率;pra是实际动作的概率。
4.根据权利要求1所述的基于多头注意力机制的deepcfr算法优化其特征在于,步骤7中的策略更新公式:
5.根据权利要求1所述的基于多头注意力机制的deepcfr算法优化其特征在于,步骤8中获得的平均策略的更新方式:
技术总结
本发明提出一种基于多头注意力的DeepCFR算法优化方法,属于机器博弈分类领域。在本发明中,使用的是DeepCFR算法,这是一种在线学习算法,不需要数据集。本方法利用神经网络模拟游戏中的CFR行为,通过避免博弈树遍历实现时间和空间的节省。然而,DeepCFR在特征提取方面存在挑战。为克服这一问题,我们引入了多头注意力机制,通过将其融入DeepCFR网络结构,以增强算法的表征能力。通过在Kuhn Poker中的实验结果验证了所提方法的有效性。证明了在逼近纳什均衡和收敛速度方面相的优越性。本发明解决了传统DeepCFR算法的特征提取限制,为机器博弈领域提供了更精确且高效的解决方案。
技术研发人员:孙岳中一,薛刻辰
受保护的技术使用者:哈尔滨理工大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!