基于AD-TSK的数据处理方法及系统
本发明涉及tsk模糊分类器,尤其涉及基于ad-tsk的数据处理方法及系统。
背景技术:
1、在过去的十多年里,神经网络因其强大的数据学习及特征表征能力,神经网络框架下的深度学习一直是机器学习领域的研究热点,国内外众多学者对此作了广泛研究及推广应用。然而,常规的深度神经网络属于确定性模型,不能够处理原始数据中的不确定性。因而,常规深度神经网络的决策结果具有有限的可解释性。特别地,其内部结构犹如“黑盒”,导致用户无法很好地理解其隐藏层中所有节点参数的状态变化。
2、为了解决上述问题,有研究人员基于可解释性和分类性能较好的takagi-sugeno-kang(tsk)模糊系统设计具有栈式结构的模糊深度学习模型,例如基于栈式结构原理,将tsk模糊分类器作为子分类器,通过并行学习将子分类器输出扩充到样本特征、共享模糊规则语义标签、将子分类器输出误差梯度嵌入样本特征及样本特征随机加噪等等方式级联子分类器并构建栈式结构形成不同模糊深度学习模型。
3、现有的dsa-fc方法利用tsk模糊分类器基于栈式结构原理形成可解释性较好且性能优异的模糊深度系统,然而在所有样本特征中嵌入梯度信息可能会致使模型泛化性能下降,且所涉及的求逆运算使得系统在训练时会产生显著的算开销。
技术实现思路
1、针对现有方法的不足,本发明通过主动对抗样本学习方式有效处理数据集中的噪声样本;基于dropout方式将子分类器输出误差梯度随机加入到输入样本特征中,以此逐层更新输入样本并构建一种新型栈式结构形成ad-tsk;并借助于sherman-morrison公式及schur complement实现模糊深度系统中每一层子分类器中无需求逆操作的模糊规则后件求解,形成f-ad-tsk模型,实现ad-tsk模型的快速训练及最优模糊规则数搜索,同时可保证ad-tsk的高可解释性。
2、本发明所采用的技术方案是:基于ad-tsk的数据处理方法包括以下步骤:
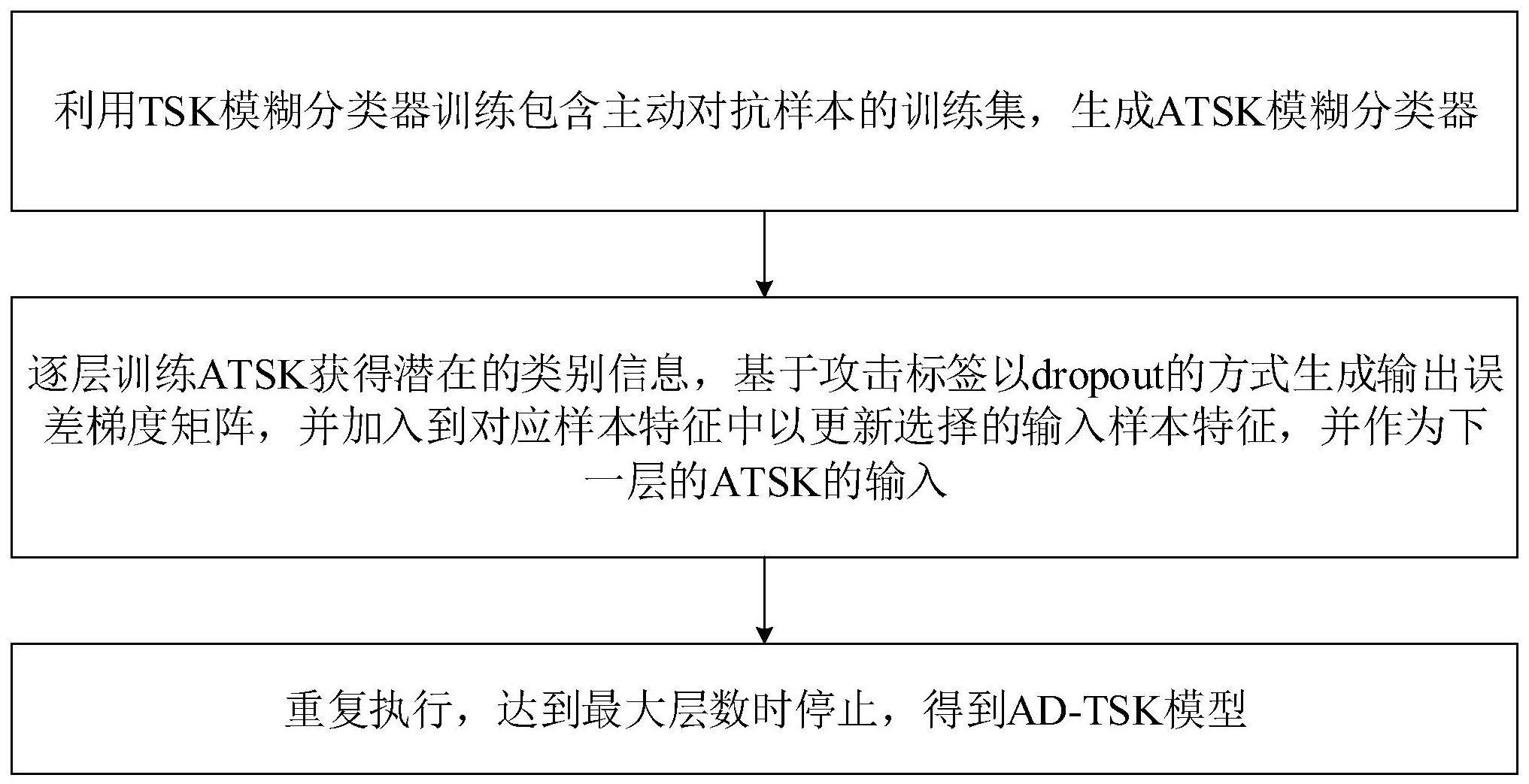
3、步骤一、利用tsk模糊分类器训练包含主动对抗样本的训练集进行主动对抗样本学习,生成atsk模糊分类器;
4、步骤二、逐层训练atsk获得潜在的类别信息,基于攻击标签以dropout的方式生成输出误差梯度矩阵,并加入到对应样本特征中以更新选择的输入样本特征,并作为下一层的atsk的输入;
5、步骤三、重复执行,达到最大层数时停止,得到ad-tsk模型。
6、进一步的,还包括:利用sherman-morrison公式、schur complement和最小学习机,实现在ad-tsk每一层子分类器中无需求逆操作,求解模糊规则后件参数,从而保证ad-tsk的快速训练和可解释性,得到f-ad-tsk模型。
7、进一步的,构建ad-tsk模块包括:
8、生成atsk_m中所有模糊规则的前件矩阵um;其中,atsk_m为第m层atsk;
9、进一步的,前件矩阵um的公式为:
10、
11、其中,n为输入的样本数,xm,1、xm,n分别为atsk_m中输入数据集的第1和第n个样本,分别为atsk_m中第1条和第rm条模糊规则对应的xm,1的归一化后的隶属度函数值,分别为atsk_m中第1条及第rm条模糊规则对应的xm,n的归一化后的隶属度函数值,分别为xm,1、xm,n构造向量。
12、利用最小学习机计算所有模糊规则的后件参数pm;
13、进一步的,后件参数pm的公式为:
14、
15、其中,τ代表正则化参数,um、pm及分别代表atsk_m中所有模糊规则的前件矩、后件参数及主动对抗样本xm对应的标签集,i代表单位矩阵。
16、以dropout方式随机在两层atsk子分类器之间确定每一层的输出误差梯度;
17、进一步的,输出误差梯度gm(i,j)的公式为:
18、
19、
20、其中,xm,ij为ad-tsk的第m层中第i输入样本的第j个特征,fr(xm,i)为r条模糊规则xm,ij对应的输出值,及分别为第r′条模糊规则隶属度函数的中心及宽度核,及分别代表第r条模糊规则归一化后的隶属度值及后件参数。
21、将atsk_m输出误差梯度乘以样本特征学习率,并加入到所选择样本特征中以更新所选择样本,并将更新后的样本作为下一层输入。
22、进一步的,f-ad-tsk模型的求解模糊规则后件参数的部分伪逆表达公式为:
23、
24、
25、
26、其中,和分别代表组成的两个分块矩阵,代表基于的部分伪逆表达,代表hr连续增加i行的矩阵,代表第(r+1)条模糊规则前件矩阵对应的第(i+1)行,i代表单位矩阵,η代表1/τ的平方根。
27、进一步的,基于ad-tsk的数据处理系统,包括:存储器,用于存储可由处理器执行的指令;处理器,用于执行指令以实现基于ad-tsk的数据处理方法。
28、进一步的,存储有计算机程序代码的计算机可读介质,计算机程序代码在由处理器执行时实现基于ad-tsk的数据处理方法。
29、本发明的有益效果:
30、1、以主动更改部分样本真实标签类型的方式生成主动对抗样本,并利用每一层子分类器进行主动对抗样本学习,提升了ad-tsk对噪声样本的学习能力;
31、2、基于每一层子分类器的主动对抗样本学习构建一种新型栈式结构,针对该新型栈式结构前后两层中的子分类器,利用dropout方式随机选择前层子分类器的输出误差梯度信息加入到对应样本特征中并将更新后的样本作为后一层子分类器的输入,提升了ad-tsk的泛化性能;
32、3、基于sherman-morrison公式及schur complement对ad-tsk的快速训练方法进行改进,得到f-ad-tsk,在无需求逆操作的情况下可求解ad-tsk每一层子分类器中所有模糊规则的后件,从而实现ad-tsk模型的快速训练,利用真实数据集验证f-ad-tsk的有效性。
技术特征:
1.基于ad-tsk的数据处理方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于ad-tsk的数据处理方法,其特征在于,还包括:利用sherman-morrison公式、schur complement和最小学习机,实现在ad-tsk每一层子分类器中无需求逆操作,求解模糊规则后件参数,从而保证ad-tsk的快速训练和可解释性。
3.根据权利要求1所述的基于ad-tsk的数据处理方法,其特征在于,ad-tsk模型的构建包括:
4.根据权利要求3所述的基于ad-tsk的数据处理方法,其特征在于,前件矩阵um的公式为:
5.根据权利要求3所述的基于ad-tsk的数据处理方法,其特征在于,后件参数pm的公式为:
6.根据权利要求3所述的基于ad-tsk的数据处理方法,其特征在于,输出误差梯度gm(i,j)的公式为:
7.根据权利要求2所述的基于ad-tsk的数据处理方法,其特征在于,求解模糊规则后件参数的部分伪逆表达结果为:
8.基于ad-tsk的数据处理系统,其特征在于,包括:存储器,用于存储可由处理器执行的指令;处理器,用于执行指令以实现如权利要求1-7任一项所述的基于ad-tsk的数据处理方法。
9.存储有计算机程序代码的计算机可读介质,其特征在于,计算机程序代码在由处理器执行时实现如权利要求1-7任一项所述的基于ad-tsk的数据处理方法。
技术总结
本发明涉及TSK模糊分类器技术领域,尤其涉及基于AD‑TSK的数据处理方法及系统,包括利用TSK模糊分类器训练包含主动对抗样本的训练集,生成ATSK模糊分类器;逐层训练ATSK获得潜在的类别信息,基于攻击标签以dropout的方式生成输出误差梯度矩阵,并加入到对应样本特征中以更新选择的输入样本特征,并作为下一层的ATSK的输入;重复执行,达到最大层数时停止,得到AD‑TSK模型。本发明解决现有DSA‑FC方法在所有样本特征中嵌入梯度信息可能会致使模型泛化性能下降,且所涉及的求逆运算使得系统在训练时会产生显著的计算开销。
技术研发人员:石航鸣,史兵,顾苏杭
受保护的技术使用者:常州大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!