基于BERT进行文本的情感词语提取模型的建立方法及应用
本发明属于互联网的,具体涉及为一种基于bert进行文本的情感词语提取模型的建立方法及其应用。
背景技术:
1、随着互联网和移动通信的迅速发展,人们的信息获取途径更加多样和便捷。社交媒体、在线评论、网络论坛等平台上大量用户生成的文本数据充斥着社会,给人们带来了海量的信息。另外,企业、政府和媒体等组织需要了解公众对特定事件、产品或服务的态度和情感倾向,以做出相应的决策和调整策略。情感分析技术能够挖掘并分析海量文本中的情感信息,满足实时舆情监测和舆论分析的需求。
2、目前,对于文本样本使用bert算法来获取情感信息,通过捕捉到文本中的情感色彩词语,并通过微调或特定任务的训练来实现情感分析,判断评论是积极、消极还是中性,这依然是情感分析领域的研究空白。因此,如何设计一款情感词语提取模型从这些文本数据中获取有价值的情感信息,然后通过分析用户对品牌、产品和服务的情感反馈改进品牌管理和用户体验,成为当下重要的问题。这使得情感分析的自动化成为可能,也为企业决策提供有力支持。
3、综上所述,基于bert算法的情感词语提取模型在舆情监测、市场调研和用户反馈分析等领域具有广泛应用前景,节省了大量的时间和人力成本,同时对提升企业竞争力和用户满意度起到积极的推动作用。
技术实现思路
1、基于以上背景中迫切的需要,本发明旨在提供一种更准确、智能的方式来处理大规模文本数据,提供了一种基于bert进行文本的情感词语提取模型的建立方法及其应用。
2、为达到上述目的,本发明采用了以下技术方案:基于bert进行文本的情感词语提取模型的建立方法,其特征在于:其包括如下步骤:
3、步骤s1,数据收集分类:将包含带有情感色彩词语的文本样本作为数据集,每个文本样本出现的情感色彩词语分别标记为积极、中性或消极;
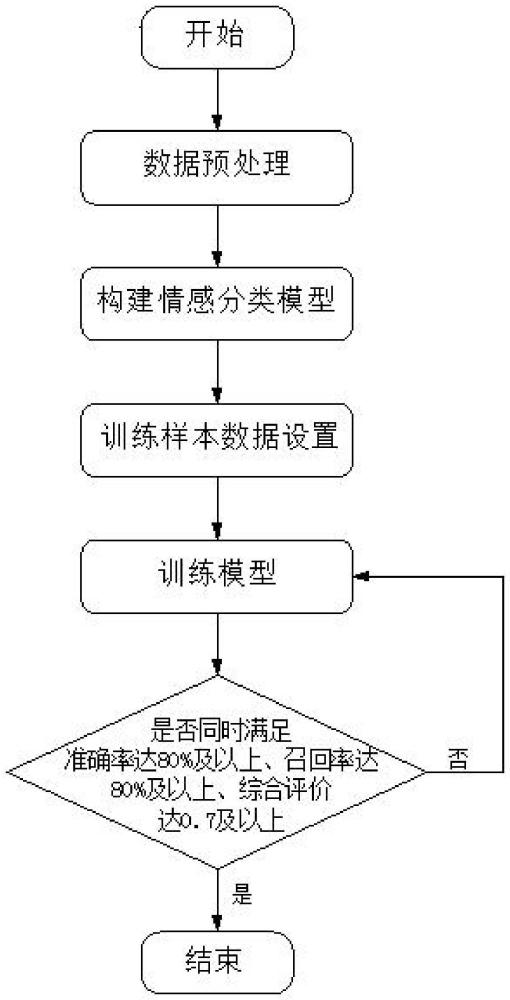
4、步骤s2,数据预处理:将分类后的数据集导入到bert-base-uncased库中进行预处理,使用hugging face transformers库的工具来执行分词和编码、初始化参数设置、创建数据字典以及数据格式转化;
5、步骤s3,构建情感分类模型:在hugging face transformers库中,使用bertforsequenceclassification工具,将bert算法的输出上连接到一个分类层,该分类层用于输出每个类别的概率分布,积极、中性或消极三类数据的分布占比;
6、步骤s4,训练样本数据设置:优化器为adam,学习率为0.00002,训练步数为10000,批量大小为32,dropout为0.2;
7、步骤s5,训练模型:将80%的数据集作为训练集,训练集通过前向传播得到模型的预测结果为p,使用交叉熵损失函数计算出预测结果的差异值为l,使用链式法则,从输出层向输入层逐层计算每个层的梯度值t,逐层反向传播梯度,将梯度从输出层传递到输入层,用来降低交叉熵损失函数的计算出的差异值;重复上述训练过程,在训练集上不断优化模型,提高模型的准确度;
8、步骤s6,评估并建立模型:将20%的数据集作为测试集,使用测试集对步骤s5中获得的模型进行评估,判断模型的准确率达到是否达80%及以上、召回率是否达80%及以上、综合评价是否达到0.7及以上,若同时满足上述三个标准,则确定为训练良好,完成模型的建立;否则,重复步骤s5,直至训练同时满足上述三个标准,完成模型的建立。
9、作为上述技术方案的进一步解释及限定,在步骤s2数据预处理中,其包括以下步骤:
10、步骤s2.1,初始化参数设置:输入序列的最大长度,即max_seq_length=128;
11、步骤s2.2,分词和编码:将文本样本拆分成单词或子词过程,将文本样本进行分词并转换为bert模型所需的编码;
12、步骤s2.3,创建数据字典:将分词后的编码以及相应的标签组合成一个数据字典,将数据字典组织成一个列表作为训练数据;
13、步骤s2.4,数据格式转化:使用bert算法中的分词器和编码方式将训练数据转换成bert模型所规定的输入数据格式。
14、作为上述技术方案的进一步解释及限定,在步骤s5中,差异值计算所使用的交叉熵损失函数为式中:n表示为数据集的数量,y表示为每个样本的标签,p表示为训练集通过前向传播得到模型的预测结果。
15、作为上述技术方案的进一步解释及限定,在步骤s5中,梯度值的计算公式为式中:n表示为数据集的数量,y表示为每个样本的标签,p表示为训练集通过前向传播得到模型的预测结果,l表示为使用交叉熵损失函数计算出预测结果的差异值。
16、作为上述技术方案的进一步解释及限定,准确率为召回率为综合评价为其中,tp为真正例,即预测为正例,并且实际为正例的样本数量;fp为假正例,即预测为正例,但实际为反例的样本数量;fn为假反例,即预测为反例,但实际为正例的样本数量。
17、一种采用上述技术方案中基于bert进行文本的情感词语提取模型的应用,其特征在于:该模型用于分析社交媒体上用户对平台最新推出的产品的评价,并准确提取文本中的情感词语,便于平台后台管理人员了解用户对产品的喜好程度、关注点以及存在的问题。
18、作为上述技术方案的进一步解释及限定,该模型适用于情感分析、个性化推荐、对话系统和情感写作辅助的互联网应用平台场景。
19、与现有技术相比,本发明具有以下优点:
20、1、本发明利用bert进行预训练和微调,即采用bert作为基础模型,在大规模文本数据上进行预训练,使其具备对文本进行全面理解和表征的能力;然后,在带有情感标签的训练数据上进行微调,针对情感词语提取任务进行优化和训练。
21、2、本发明在模型训练过程中,采用了逐层反向传播梯度的方法,不断优化模型,提高准确度。通过使用测试集对模型进行评估,判断其准确率、召回率和综合评价等指标是否达到要求,从而确定模型的训练良好与否。
22、3、本发明在bert模型的输出层之上添加了一个分类层,使模型能够输出每个情感类别的概率分布。这样可以更加精确地判断每个词语的情感倾向性,而不仅仅是简单的二分类(正面/负面)。
23、4、本发明所设计的情感词语提取模型不仅可以填补了情感分析领域的研究空白,而且还能够解决传统方法面临的困难和痛点,以更好地满足社会对情感分析的需求。
24、5、本发明所设计的情感词语提取模型通过上下文感知和细粒度情感识别,能准确提取文本中的情感词语,适用于情感分析、个性化推荐、对话系统和情感写作辅助等场景。该模型能更好地理解情感表达,帮助企业舆情监测、推荐系统精准推荐、对话系统回应情感、和作者提高写作情感效果。
技术特征:
1.基于bert进行文本的情感词语提取模型的建立方法,其特征在于:其包括如下步骤:
2.根据权利要求1所述基于bert进行文本的情感词语提取模型的建立方法,其特征在于:在步骤s2数据预处理中,其包括以下步骤:
3.根据权利要求1或2所述基于bert进行文本的情感词语提取模型的建立方法,其特征在于:在步骤s5中,差异值计算所使用的交叉熵损失函数为式中:n表示为数据集的数量,y表示为每个样本的标签,p表示为训练集通过前向传播得到模型的预测结果。
4.根据权利要求3所述基于bert进行文本的情感词语提取模型的建立方法,其特征在于:在步骤s5中,梯度值的计算公式为式中:n表示为数据集的数量,y表示为每个样本的标签,p表示为训练集通过前向传播得到模型的预测结果,l表示为使用交叉熵损失函数计算出预测结果的差异值。
5.根据权利要求4所述基于bert进行文本的情感词语提取模型的建立方法,其特征在于:准确率为召回率为综合评价为其中,tp为真正例,即预测为正例,并且实际为正例的样本数量;fp为假正例,即预测为正例,但实际为反例的样本数量;fn为假反例,即预测为反例,但实际为正例的样本数量。
6.一种采用权利要求5所述基于bert进行文本的情感词语提取模型的应用,其特征在于:该模型用于分析社交媒体上用户对平台最新推出的产品的评价,并准确提取文本中的情感词语,便于平台后台管理人员了解用户对产品的喜好程度、关注点以及存在的问题。
7.根据权利要求6所述基于bert进行文本的情感词语提取模型的应用,其特征在于:该模型适用于情感分析、个性化推荐、对话系统和情感写作辅助的互联网应用平台场景。
技术总结
本发明属于互联网的技术领域,公开了一种基于BERT进行文本的情感词语提取模型的建立方法及其应用。该模型使用BERT算法来获取情感信息,通过捕捉到文本中的情感色彩词语,并通过微调或特定任务的训练来实现情感分析,判断评论是积极、消极还是中性,该模型可以快速评估评论的情感态度,判断其为积极、消极或中性,这使得情感分析的自动化成为可能,节省了大量的时间和人力成本。此外,该模型通过分析用户对品牌、产品和服务的情感反馈,该模型还能够改进品牌管理和用户体验,尤其在舆情监测、市场调研和用户反馈分析等领域具有广泛应用前景,为企业决策提供有力支持。
技术研发人员:耿海军,董赟,姜泽同,谭竹宏
受保护的技术使用者:山西大学
技术研发日:
技术公布日:2024/1/5
- 还没有人留言评论。精彩留言会获得点赞!