一种基于神经网络的大场景自由视点插值方法及装置
本发明涉及计算机视觉及图形学领域,特别是涉及一种基于神经网络的大场景自由视点插值方法及装置。
背景技术:
1、近年来基于神经网络的视点插值算法发展迅速,其基本理论是编码一个基于坐标点的三维空间光照场,并利用体渲染技术(参见mildenhall b,srinivasan p p,tancik m,et al.nerf:representing scenes as neural radiance fields for view synthesis[c]//european conference on computer vision.springer,cham,2020:405-421.)完成对光照场的渲染。神经光照场的优势在于可以较好地重建出反射,压缩场景存储消耗。
2、当前基于神经网络来编码光场仍然存在许多问题,尤其是应用到大规模场景上。首先,相机位姿在大规模场景重建中的精准度不高,导致最终渲染质量低,存在模糊区域;其次,大场景的训练速度慢,细节重建难度大,单卡训练大场景容易存在显存溢出等问题;最后,如何实现高质量大场景渲染仍具有挑战。
技术实现思路
1、本发明目的在于针对现有技术的不足,提供了一种基于神经网络的大场景自由视点插值方法及装置。可以分布式优化大场景的同时优化相机位姿,实现高质量渲染。
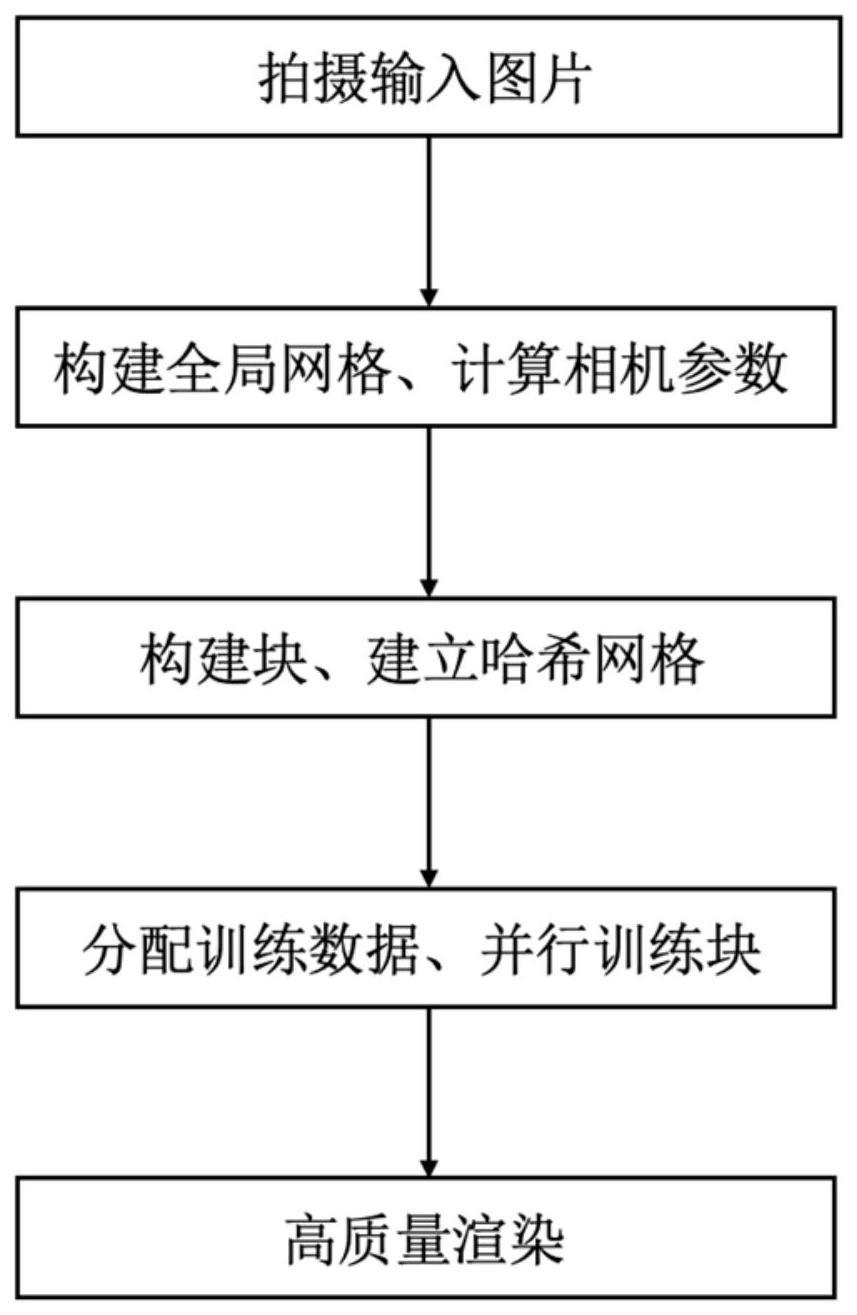
2、为了达到上述目的,本发明采用以下技术方案:第一方面,本发明提供了一种基于神经网络的大场景自由视点插值方法,包括以下步骤:
3、(1)对某个视角下的场景进行拍摄,基于图片计算全局网格模型和相机参数;
4、(2)把步骤(1)计算得到的全局网格模型剖分成块,并为每个块创建哈希网格、漫反射解码器和反射解码器,基于哈希网格得到哈希特征,并通过漫反射解码器和反射解码器得到三维点颜色,并通过体渲染积分得到一条光线的颜色;
5、(3)为步骤(2)建立的块分配训练的光线,然后进行并行训练,训练过程中同时优化哈希网格特征、解码器参数以及相机位姿,训练使用交替方向乘子法来保证块间相机位姿的一致性;
6、(4)利用步骤(3)训练完成的模型,在光线上进行采样点,基于点混合的多块渲染分别渲染光线的前景颜色和背景颜色。
7、进一步地,步骤(1)中,将拍摄的图片输入三维重建软件capturingreality,得到拍摄场景的全局网格模型以及图片对应的相机内参和外参。
8、进一步地,步骤(2)中,设定块的尺寸,从全局网格模型的最小角点开始剖分块,块与块之间存在20%的重叠区域,并丢弃内部不包含相机的块。
9、进一步地,步骤(2)中,哈希网格的输入是世界坐标系下的三维点x,输出是多层级哈希特征fx:
10、fx=φθ(x)
11、其中,φθ表示哈希网格,θ表示优化参数;
12、漫反射解码器输入多层级哈希特征fx,输出为64维度的特征,基于前32维度的特征得到体密度、漫反射颜色以及反射系数:
13、dθ(fx)=(σx,cd,s,hx)
14、其中,dθ表示漫反射解码器,σx表示体密度,cd表示漫反射颜色,s表示反射系数,hx表示后32维度的特征;
15、反射解码器输入为球谐基函数sh对光线方向ω的编码以及漫反射解码器输出的后32维特征hx,输出是反射颜色cs:
16、sθ(sh(ω),hx)=cs
17、其中,sθ表示反射解码器,因此,三维点颜色被表示为:
18、c=cd+s·cs
19、其中,c为三维点x的颜色,利用体渲染公式积分得到一条光线的颜色。
20、进一步地,步骤(3)中,利用相机位姿和全局网格模型为每个块分配光线,如果光线发射位置位于块内,则直接被选为该块的训练光线;如果光线发射位置位于块外,满足光线与块相交且没有被遮挡,则被选为该块的训练光线;每个块独立编码块内前景以及块外背景颜色,块内空间三维点用于表达前景,块外三维点用于表达背景;前景与背景共享哈希网格特征以及两个解码器参数。
21、进一步地,步骤(3)中,训练过程中为每个块存储一份几何网格,通过哈希网格和解码器获得几何网格内三维点的体密度,若1-exp(-σx)<λ,则对几何网格进行剪枝,λ为剪枝的阈值;
22、通过两条导数链优化相机位姿:1.损失对哈希网格特征的梯度通过空间三维点传递到相机位姿;2.扭曲损失对相机变换矩阵的梯度传递到相机位姿;
23、扭曲损失帮助优化几何以及相机位姿,优化后参数回传,优化哈希网格特征,解码器参数。
24、进一步地,渲染光线的前景颜色具体过程为:若一个采样点只被某个块单独占有,则使用该块对应的哈希网格和解码器推理该点的颜色与体密度;若该采样点在块间重叠区域,则使用点混合方式推理该点的前景颜色cf与体密度:
25、
26、
27、其中,s(xn)表示包含点xn的块集合,表示块k对于点xn的混合权重;该权重与点和块边界的距离有关,在两个块的重叠区域;n表示为光线上采样点的数量,n为采样点编号,表示第n个采样点在块k内的体密度;表示前景采样点的可见性;δn表示第n个采样点到第n+1个采样点的距离;第n个采样点在块k内的颜色。
28、进一步地,渲染光线的背景颜色具体过程为:利用光线穿出最后一个块的哈希网格和解码器推理该光线的背景颜色,若同时穿出多个块,即穿出点xn被多个块包含,则加权混合背景颜色cb:
29、
30、其中,s′(xn)表示包含出射点xn的块集合,是积分完成的背景颜色,tn表示背景采样点的可见性;最后光线的颜色表示为
31、第二方面,本发明还提供了一种基于神经网络的大场景自由视点插值装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现所述的一种基于神经网络的大场景自由视点插值方法。
32、第三方面,本发明还提供了一种计算机可读存储介质,其上存储有程序,所述程序被处理器执行时,实现所述的一种基于神经网络的大场景自由视点插值方法。
33、本发明的有益效果在于:
34、1、统一室内室外场景的表达。把远景和反射物体同时编码在背景,同时利用反射解码器拟合高光和其他视角相关效果。
35、2、分块表达大场景,利用交替方向乘子法分布式训练块相关哈希网格特征和网络,同时优化相机位姿。加快了训练速度,提升了可扩展性,避免了单卡编码大场景存在的显存问题。
36、3、实现高质量渲染,渲染指标psnr在测试的2个室内场景和4个室外场景中平均提升5%-10%。渲染清晰的近景、远景、反射以及实现块间颜色的平滑过度。
技术特征:
1.一种基于神经网络的大场景自由视点插值方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于神经网络的大场景自由视点插值方法,其特征在于,步骤(1)中,将拍摄的图片输入三维重建软件capturingreality,得到拍摄场景的全局网格模型以及图片对应的相机内参和外参。
3.根据权利要求1所述的一种基于神经网络的大场景自由视点插值方法,其特征在于,步骤(2)中,设定块的尺寸,从全局网格模型的最小角点开始剖分块,块与块之间存在20%的重叠区域,并丢弃内部不包含相机的块。
4.根据权利要求1所述的一种基于神经网络的大场景自由视点插值方法,其特征在于,步骤(2)中,哈希网格的输入是世界坐标系下的三维点x,输出是多层级哈希特征fx:
5.根据权利要求1所述的一种基于神经网络的大场景自由视点插值方法,其特征在于,步骤(3)中,利用相机位姿和全局网格模型为每个块分配光线,如果光线发射位置位于块内,则直接被选为该块的训练光线;如果光线发射位置位于块外,满足光线与块相交且没有被遮挡,则被选为该块的训练光线;每个块独立编码块内前景以及块外背景颜色,块内空间三维点用于表达前景,块外三维点用于表达背景;前景与背景共享哈希网格特征以及两个解码器参数。
6.根据权利要求1所述的一种基于神经网络的大场景自由视点插值方法,其特征在于,步骤(3)中,训练过程中为每个块存储一份几何网格,通过哈希网格和解码器获得几何网格内三维点的体密度,若1-exp(-σx)<λ,则对几何网格进行剪枝,λ为剪枝的阈值;
7.根据权利要求1所述的一种基于神经网络的大场景自由视点插值方法,其特征在于,渲染光线的前景颜色具体过程为:若一个采样点只被某个块单独占有,则使用该块对应的哈希网格和解码器推理该点的颜色与体密度;若该采样点在块间重叠区域,则使用点混合方式推理该点的前景颜色cf与体密度:
8.根据权利要求7所述的一种基于神经网络的大场景自由视点插值方法,其特征在于,渲染光线的背景颜色具体过程为:利用光线穿出最后一个块的哈希网格和解码器推理该光线的背景颜色,若同时穿出多个块,即穿出点xn被多个块包含,则加权混合背景颜色cb:
9.一种基于神经网络的大场景自由视点插值装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,其特征在于,所述处理器执行所述可执行代码时,实现如权利要求1-8中任一项所述的一种基于神经网络的大场景自由视点插值方法。
10.一种计算机可读存储介质,其上存储有程序,其特征在于,所述程序被处理器执行时,实现如权利要求1-8中任一项所述的一种基于神经网络的大场景自由视点插值方法。
技术总结
本发明公开了一种基于神经网络的大场景自由视点插值方法及装置,包括以下四个步骤,1、对场景进行拍摄,并把图片作为输入计算全局网格模型和相机参数;2、把步骤1计算得到的全局网格模型剖分成块,并为每个块创建哈希网格以及两个解码器,解码器分别用于解码漫反射和反射;3、为步骤2建立的块分配训练的光线,然后进行并行训练,训练过程中同时优化哈希网格特征,解码器参数以及相机位姿,训练使用交替方向乘子法来保证块间相机位姿的一致性;4、利用步骤3训练完成的模型,进行基于点混合的多块渲染。通过本发明提出的方法,可同时适用于室内和室外大场景,实现照片级别真实的高质量渲染。可用于虚拟现实场景构建等相关领域。
技术研发人员:许威威,吴秀超,张鑫,鲍虎军
受保护的技术使用者:浙江大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!