一种基于预训练语言模型和白化风格化的简历重构方法
本发明涉及计算机,具体涉及一种基于预训练语言模型和白化风格化的简历重构方法。
背景技术:
1、随着人工智能与大数据技术的进一步发展,nlp技术渗透到了各个行业,ai辅助简历撰写的应用程序已经出现,并且在市场上得到了广泛应用。这些应用程序使用自然语言处理和机器学习技术,通过分析大量简历和职位描述,自动生成优化的简历,以提高求职者的招聘成功率。然而,对于简历风格化的修订尚且欠缺,而这是不那么明显却依然很重要的一块。最近,人工智能系统越来越多的用于自动化许多招聘流程(如智能简历筛选),由于从训练数据和从简历中推断的个人信息中学习到的偏见,一些人群可能会在没有人类指导和干预的情况下被人工智能算法歧视。这引起了对算法招聘公平性和道德的担忧。如此前亚马逊使用的人工智能招聘工具,被证明是对女性求职者具有偏见的。然而,有大量证据已经证明从不含任何标签的书写文本就可以以较高的正确率(70~80%)推断出书写者的性别,因此通过简单的不报告性别而实施的性别匿名化可能存在问题。
2、实际上,在自然语言文本生成领域,消除性别偏见已经得到重视。现有方法,有的通过对词嵌入向量进行编辑,消除词嵌入中的性别倾向。然而,通过编辑嵌入向量来消除单词性别倾向可能会破坏单词的语义,从而导致其在上下文中的意义发生变化。此外,编辑之后仍然可能在模型生成新文本的过程中纳入性别信息或偏见。也有方法针对消除具体文本段落中的性别歧视和倾向的研究,一种可以用来消除文本文档偏见的机器学习技术是文本风格迁移,这是一种将文本实例从一个域转换到另一个域的技术,尽可能保持原始内容和含义不变的同时改变文体风格。这些方法中,基于关键字替换的局限性较大,操作不够灵活且可能导致最后文本不够流畅。基于神经网络生成方法注重于去掉性别信息,而没有重视在这个过程中,对原始文本的其他性别无关的内容和信息的保持,可能会丢失重要信息,这对于简历的重写是十分关键的。
技术实现思路
1、本发明针对现有技术存在的问题提供一种基于预训练语言模型和白化风格化的简历重构方法。
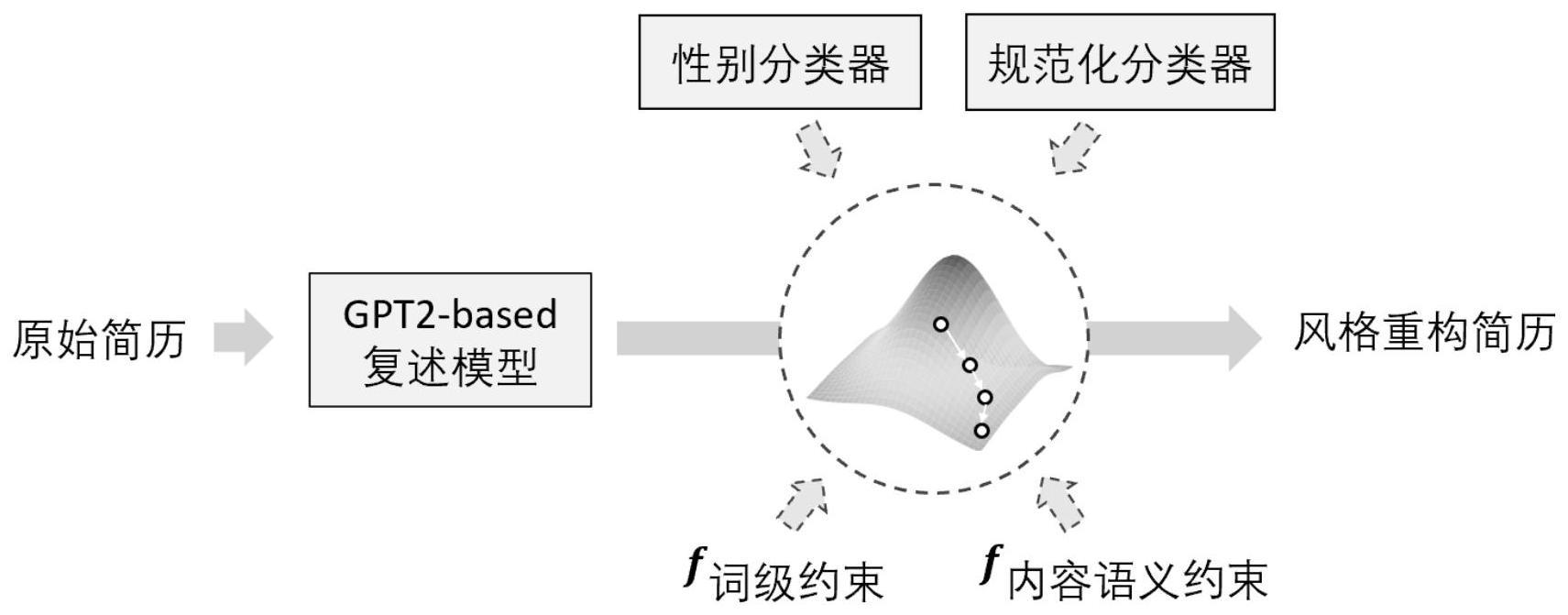
2、本发明采用的技术方案是:一种基于预训练语言模型和白化风格化的简历重构方法,包括以下步骤:
3、步骤1:获取简历数据,对数据进行预处理作为训练数据集和测试数据集;
4、步骤2:构建性别分类器和规范化分类器;
5、步骤3:构建简历复述模型并进行训练,简历复述模型以gpt2模型为主体,在靠近输出端的某一层连接用于对重构简历进行白化和风格化的白化-风格化模块;
6、白化-风格化模块首先对重构简历进行白化转换,即去除输入表达中的风格信息,生成只包含基本内容信息的文本表示;然后对白化后的文本表示进行风格化恢复;
7、步骤4:将简历输入步骤3训练完成的简历复述模型,即可得到风格重构简历。
8、进一步的,所述步骤1中预处理包括对简历数据进行数据清洗,通过正则表达式去除包含乱码和非法符号的数据;得到简历正文和应聘者性别数据对。
9、进一步的,所述步骤2中性别分类器和规范化分类器采用基于gpt模型的分类模型,性别分类器输出简历作者性别,规范化分类器输出规范化标签;性别分类器和规范化分类器均使用交叉熵损失函数进行模型训练。
10、进一步的,所述白化转换过程如下:
11、计算潜在表达z的协方差矩阵
12、∑z=e[(z-zμ)(z-zμ)t]
13、式中:zμ为z的均值,t表示转置操作,e为期望;
14、将协方差矩阵与单位矩阵i之间差值的弗罗贝尔乌斯范数最小化:
15、
16、式中:w为白化矩阵,f表示弗罗贝尼乌斯范数;
17、白化变换表示为:
18、c=wz
19、式中:z为输入简历的潜在表达,c为白化后的潜在表达。
20、进一步的,所述风格化过程如下:
21、代表风格特征的协方差矩阵∑s进行分解:
22、
23、式中:为特征值对角矩阵,为特征向量矩阵,s为风格化矩阵;
24、风格化矩阵如下:
25、
26、风格化转换如下:
27、
28、式中:为风格化的潜在表示。
29、进一步的,所述步骤4中训练过程中采用的多目标优化函数为将以下目标最小化:
30、
31、式中:x为输入简历,y为重构后的简历;logp(y|x)为原始简历x的条件概率,fgen(y)为对于重构简历的性别目标函数,fformal(y)为对于重构简历的性别目标函数,fcont(x,y)为定义在x和y之间的内容函数;
32、其中fgen(y)采用性别分类器的性别预测概率的负对数;fformal(y)采用规范化分类器的规范化预测概率的负对数;
33、fcont(x,y)定义如下:
34、
35、式中:为词语层级约束函数,fcont_sent(x,y)为句子层级约束函数,γ1和γ2为加权超参数;
36、
37、
38、
39、式中:n为模型构建的字典的大小,xi为原始简历中的词,yj为重构简历中的词,dx、dy分别为原始简历和重构简历中的词个数,tij为转移矩阵,c(xi,yj)为词语xi和yj的嵌入表示之间的欧式距离;subject to表示受限于;
40、fcont_sent(x,y)=cos(x,y)
41、式中:x和y均为句子向量。
42、进一步的,所述多目标优化函数求解过程如下:
43、最小化重构误差,同时各个约束的损失低于阈值:
44、
45、fgen(y)≤μ1,frormal(y)≤μ2,fcont(x,y)≤ε1
46、式中:μ1、μ2和ε1均为可调整的超参数;
47、构建拉格朗日函数,然后使用梯度下降来优化拉格朗日乘数和y得到最优解。
48、本发明的有益效果是:
49、(1)本发明基于预训练模型进行简历风格化修正方法,采用了预训练大模型强大的语言生成能力,使得生成的简历文本在流畅度和目标风格满足方面质量更高;
50、(2)本发明可以对简历内容进行性别中性化或规范化重写,两种风格重新可以通过多目标优化的方法同时实施或根据需求进行某一种风格改写,使用更灵活;
51、(3)本发明采用多目标优化函数,从原始简历在词语构成和语义信息层面进行多角度约束,使得生成的建立更多的保留了原始建立中的内容信息,提高了实用性和有效性。
技术特征:
1.一种基于预训练语言模型和白化风格化的简历重构方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于预训练语言模型和白化风格化的简历重构方法,其特征在于,所述步骤1中预处理包括对简历数据进行数据清洗,通过正则表达式去除包含乱码和非法符号的数据;得到简历正文和应聘者性别数据对。
3.根据权利要求1所述的一种基于预训练语言模型和白化风格化的简历重构方法,其特征在于,所述步骤2中性别分类器和规范化分类器采用基于gpt模型的分类模型,性别分类器输出简历作者性别,规范化分类器输出规范化标签;性别分类器和规范化分类器均使用交叉熵损失函数进行模型训练。
4.根据权利要求1所述的一种基于预训练语言模型和白化风格化的简历重构方法,其特征在于,所述白化转换过程如下:
5.根据权利要求4所述的一种基于预训练语言模型和白化风格化的简历重构方法,其特征在于,所述风格化过程如下:
6.根据权利要求1所述的一种基于预训练语言模型和白化风格化的简历重构方法,其特征在于,所述步骤4中训练过程中采用的多目标优化函数为将以下目标最小化:
7.根据权利要求6所述的一种基于预训练语言模型和白化风格化的简历重构方法,其特征在于,所述多目标优化函数求解过程如下:
技术总结
本发明公开了一种基于预训练语言模型和白化风格化的简历重构方法,包括以下步骤:步骤1:获取简历数据,对数据进行预处理作为训练数据集和测试数据集;步骤2:构建性别分类器和规范化分类器;步骤3:构建简历复述模型并进行训练,简历复述模型以GPT2模型为主体,在靠近输出端的某一层连接用于对重构简历进行白化和风格化的白化‑风格化模块;步骤4:将简历输入步骤3训练完成的简历复述模型,即可得到风格重构简历;本发明构建的复述模型可以对简历进行性别中性化或规范化重写,并且将原始简历内容在词语级别和语义信息层面的多角度约束融入到生成过程中,对简历风格化改写提供依据。
技术研发人员:吕建成,屈茜,刘权辉,刘祥根,叶庆,张新宇,蔡云逸,余兰兰
受保护的技术使用者:四川大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!