机器学习和深度学习模型的基于梯度的自动调整的制作方法
本公开涉及机器学习。本文提出的是用于机器学习算法的高效配置的水平可伸缩技术,以实现最优准确度而无需知悉的输入。
背景技术:
1、虽然机器学习(ml)的应用正变得无处不在,但数据科学专业知识可能仍将稀缺。诸如对于大型企业供应商及其企业客户,依靠数据科学家可能不是可持续的或可伸缩的。
2、ml建模涉及:
3、·选取合适的模型。
4、·将模型调整(tune)到给定的数据集,这是最耗时且特别的(ad-hoc)工作,其在很大程度上依赖于数据科学家的专业知识。
5、由于以下原因,模型调整是费力的。可能涉及大量的超参数(hyperparameter),尤其是对于具有许多参数(诸如多个层或多个神经元)的深度神经网络模型,诸如多层感知器(mlp)或卷积神经网络(cnn)。
6、也许更重要的是,超参数可能具有广泛的可能值。实际值的选择可能会严重影响模型的性能,诸如测得的预测准确度。遗憾的是,超参数值的选择通常是特别的,并且在很大程度上取决于数据科学家的经验。
7、模型的训练时间通常很长,并且调整需要重新训练模型,并在每次调整会话中对其进行几次评估。面对这些挑战,工业界寻求通过针对给定的数据集和给定的ml算法(诸如神经网络或支持向量机(svm))自动调整ml模型来提高效率。一种广泛使用的方法是穷举网格搜索(exhaustive grid search),其中尝试每个超参数的可能值的所有组合,并使用最佳的超参数组合。
8、另一种流行的方法是贝叶斯优化(bayesian optimization)。典型地,贝叶斯优化会为每个超参数分配先验分布。优化处理最初基于该分布选择超参数值,并且测量模型的性能。随后,基于所尝试的超参数值的观察到的性能,基于贝叶斯概率选择要探索的下一个最佳值,希望获得最优模型性能,并可能由目标函数来表示。遗憾的是,这些超参数调整(或自动调整)方法中的许多方法具有以下缺陷中的一个或多个:
9、·贝叶斯优化需要知悉的输入(informed input)。典型地,需要详细的参数分布信息以获得更好的模型性能。
10、·贝叶斯优化本质上是顺序的,并且很难以有意义的方式并行化。
11、·贝叶斯优化应用是特定于领域的。目标函数通常不是通用的,
12、并且不容易推广到大型数据集、ml和深度学习模型。
13、用于优化超参数的其它替代方法包括随机搜索,其中每个超参数的给定统计分布被用于在选定数量的最大试验期间进行搜索。贝叶斯优化和随机搜索二者都需要详细的输入,并且通常不能保证找到最佳的值组合。尽管采用了最先进的技术,但即使使用了诸如gpyopt python库之类的最佳解决方案,贝叶斯优化仍然是缓慢的并且可能不准确。
技术实现思路
技术特征:
1.一种计算机实现的方法,包括:
2.根据权利要求1所述的方法,其中,所述多个值包括所述第一超参数的六个值。
3.根据权利要求1所述的方法,其中,选择所述第一超参数的所述多个值包括:选择所述多个值中的第一半以及所述多个值中基于所述多个值的所述所述第一半的第二半。
4.根据权利要求1所述的方法,其中,所述两条线包含选自由以下各项组成的组中的至少一项:
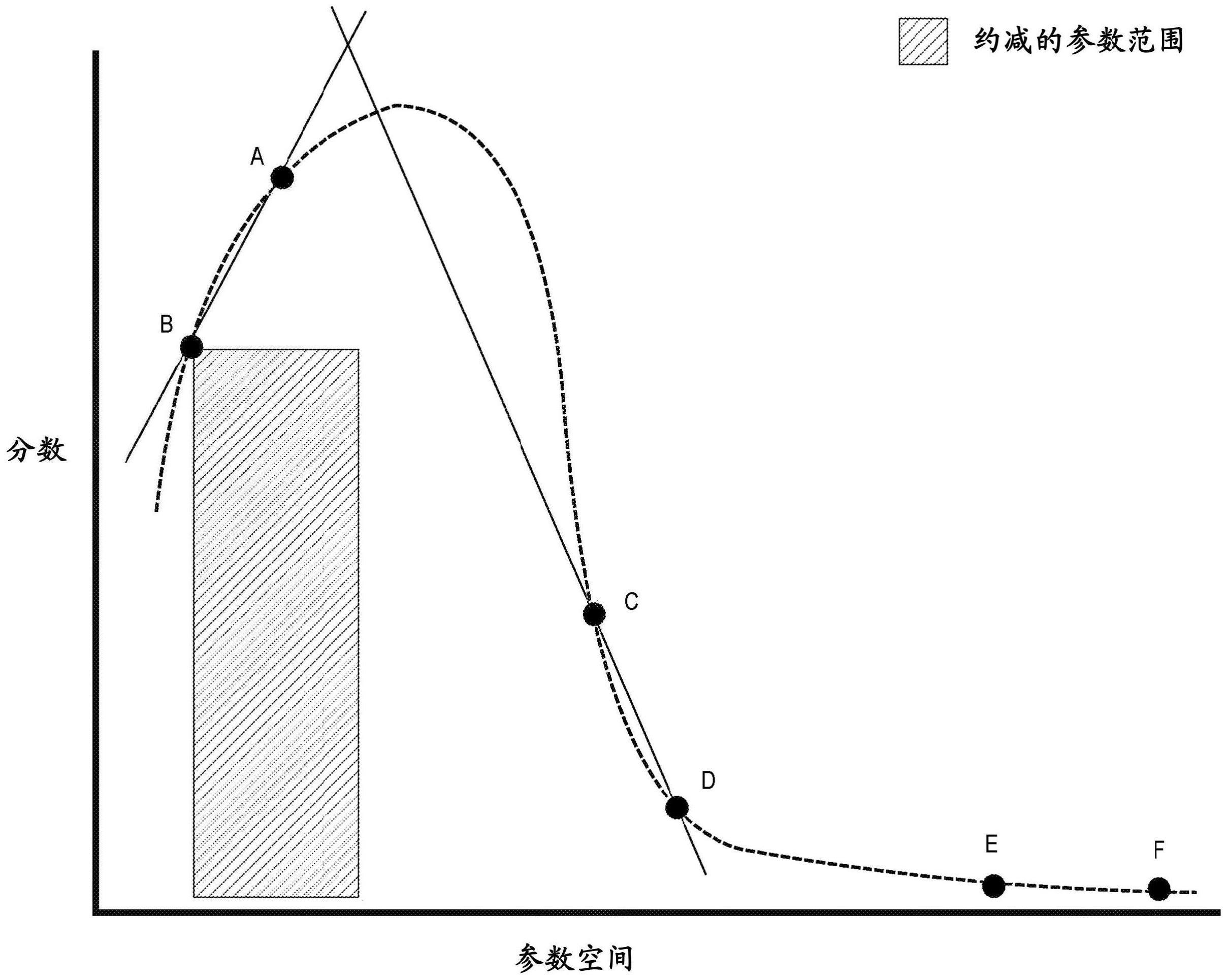
5.根据权利要求1所述的方法,其中,识别所述两条线包括:对基于训练所述ml算法的所述多个分数进行排序。
6.根据权利要求1所述的方法,还包括:在所述第一多个迭代之后迭代地进行以下操作:
7.根据权利要求6所述的方法,其中,所述第一超参数的所述值范围的所述子范围基于所述第一超参数的来自所述第一多个迭代的所述最佳值。
8.根据权利要求6所述的方法,其中,在所述第一多个迭代之后的所述迭代是响应于获得所述ml算法的所述第二超参数的新的最佳值而执行的。
9.根据权利要求6所述的方法,还包括:当所述第一超参数的所述特定最佳值与所述第一超级参数的所述最佳值之间的差超过阈值时,检测所述ml算法的类别型超参数的新的最佳值。
10.一个或多个存储指令的非暂态计算机可读介质,所述指令在由一个或多个处理器执行时,引起权利要求1-9中任一项的步骤的执行。
技术总结
本公开涉及机器学习和深度学习模型的基于梯度的自动调整。在本文中,水平可伸缩技术高效地配置机器学习算法以实现最佳准确度而无需知悉的输入。在实施例中,对于每个特定超参数,并且对于每个历元,计算机处理所述特定超参数。历元基于超参数元组探索一个超参数。从每个元组计算相应的分数。元组包含值的不同组合,每个值被包含在不同超参数的值范围内。元组的属于特定超参数的所有值都是不同的。元组的属于其它超参数的所有值都保持恒定。根据基于分数的第一线和基于分数的第二线的交点来缩小特定超参数的值范围。根据重复缩小的超参数值范围,最佳地配置机器学习算法。调用经配置的算法以获得结果。
技术研发人员:V·瓦拉达拉珍,S·伊蒂库拉,S·阿格尔沃,N·阿格尔沃
受保护的技术使用者:甲骨文国际公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!