基于AI语音自动生成案发现场视频的方法和系统与流程
本发明属于自然语言处理及语音识别、计算机视觉,具体涉及一种基于ai语音自动生成案发现场视频的方法和系统。
背景技术:
1、近年来,在信息化水平不断提高的情况下,人工智能的发展越来越多的应用于现实场景,特别是行政人员的日常办公。
2、在案情调查期间,针对某个案件,需要持续输入人员进行案件跟踪调查,如调查询问目击证人、嫌疑人、获取监控视频等前期案情分析工作,要分析记录多场次的笔录,这些任务会消耗大量的人力物力。在案情回顾时,只能翻阅大量卷宗文档,信息庞杂而不利于对目标任务的过程把控。在案件后期,大部分信息逐渐完善且整合好资源后,进行案件整体发展过程的合理性分析时,需要警务人员根据多方位线索在脑海里还原案发现场,这份独有的理解,不利于警员间进行案情分析的沟通。
技术实现思路
1、(一)要解决的技术问题
2、本发明要解决的技术问题是如何提供一种基于ai语音自动生成案发现场视频的方法和系统,以解决案情调查任务会消耗大量的人力物力,信息庞杂而不利于对目标任务的过程把控,且根据多方位线索在脑海里还原案发现场,不利于案情分析沟通的问题。
3、(二)技术方案
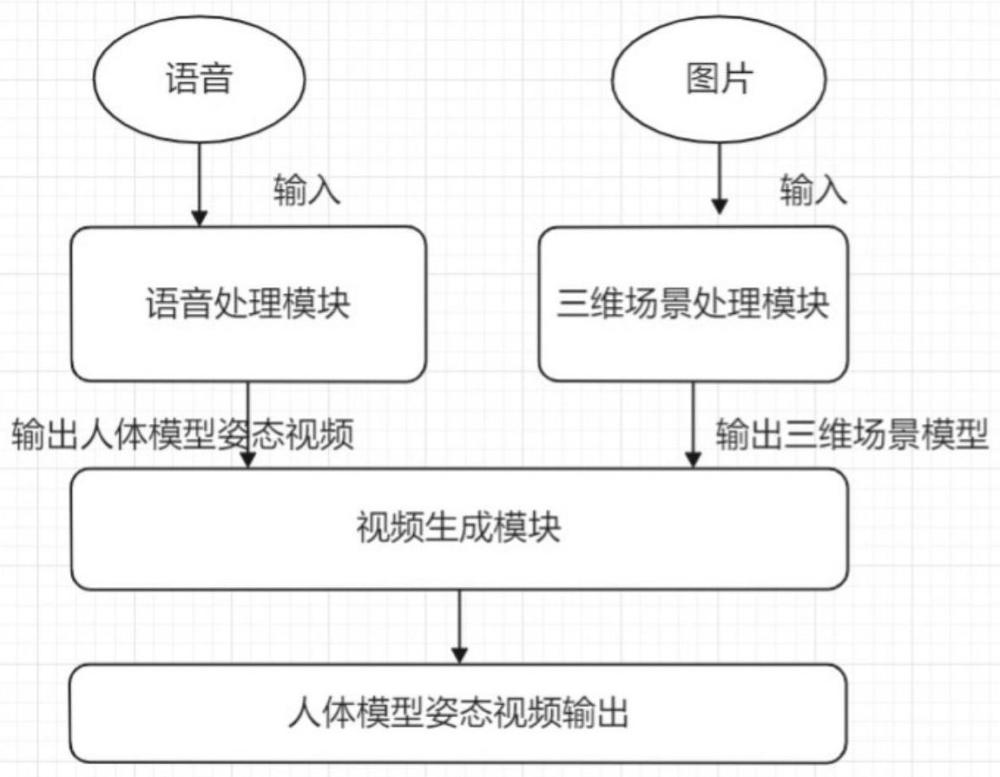
4、为了解决上述技术问题,本发明提出一种基于ai语音自动生成案发现场视频的方法,该方法包括如下步骤:
5、s1、通过收集当事人的自我叙述语音,经过语音处理模块,输出该叙述主体的人体模型姿态视频;
6、s2、将案发现场的图片输入到三维场景处理模块中,输出为具有案发实景的三维场景模型;
7、s3、将上述两部分作为输入,输入到视频生成模块中,生成该人体模型在案发现场连贯的姿态视频。
8、(三)有益效果
9、本发明提出一种基于ai语音自动生成案发现场视频的方法和系统,本发明在使用过程中,具有以下有益效果:
10、调查审讯结果不需要查看繁多的卷宗问答,与本案相关的人体的动作场景被生成一段可视化的视频,可帮助办案人员快速理清人物与案情的关系,对案情提取的响应速度快,案发现场能够被快速生成,更有利于后续警务人员办案效率的整体提升。
技术特征:
1.一种基于ai语音自动生成案发现场视频的方法,其特征在于,该方法包括如下步骤:
2.如权利要求1所述的基于ai语音自动生成案发现场视频的方法,其特征在于,所述s1由语音处理模块执行,具体包括如下步骤:
3.如权利要求2所述的基于ai语音自动生成案发现场视频的方法,其特征在于,所述步骤s12具体包括:对采集到的语音信号进行预处理,去除语音噪声、放大语音信号;将预处理后的语音用谷歌的语音识别软件google cloud speech-to-text,转换为可处理的文本。
4.如权利要求2所述的基于ai语音自动生成案发现场视频的方法,其特征在于,所述步骤s13具体包括如下步骤:
5.如权利要求2所述的基于ai语音自动生成案发现场视频的方法,其特征在于,所述步骤s14中的人体姿态估计模型首先会通过大量的文本数据集进行训练,目的是进行文本到姿态的识别转换;训练的数据集包含人体能做出的多样动作的文本,进行无监督训练;在训练完成后,能对输入的人体动作进行转换。
6.如权利要求5所述的基于ai语音自动生成案发现场视频的方法,其特征在于,人体姿态估计模型的训练和预测包括:
7.如权利要求1-6任一项所述的基于ai语音自动生成案发现场视频的方法,其特征在于,所述步骤s2由三维场景处理模块执行,具体包括如下步骤:
8.如权利要求7所述的基于ai语音自动生成案发现场视频的方法,其特征在于,所述步骤s25具体包括:以室内场景作为假设,首先获取室内多角度的图片,根据点云配准,室内的地面、墙面、天花板被对齐在三个互相垂直的主方向上;根据多视角图像立体匹配的方法进行三维建模,得到室内的三维场景模型。
9.如权利要求7所述的基于ai语音自动生成案发现场视频的方法,其特征在于,视频生成模块通过大量训练人体在场景中活动的数据集,利用递归神经网络学习人体模型姿态视频在场景空间中的映射;输入人体模型姿势视频、三维场景模型,根据姿态间帧的时间相关性在三维场景中进行特征融合,生成人体姿态在三维场景中与时间相关的连续视频。
10.如权利要求9所述的基于ai语音自动生成案发现场视频的方法,其特征在于,所述步骤s3由视频生成模块执行,具体包括如下步骤:
技术总结
本发明涉及一种基于AI语音自动生成案发现场视频的方法和系统,属于自然语言处理及语音识别、计算机视觉技术领域。本发明收集目击证人、嫌疑人等有关本案案情的口供语音作为数据集,对语音进行一系列处理,对人体在时间、地点、动作等的相关事件进行特征提取,将提取结果输入到训练好的人体姿态估计神经网络模型,得到该人体基于时间地点的连贯的姿态动作视频;把人体的姿态动作与三维场景主题输入到视频生成器模块中,将时间维度上人体模型的姿态动作与三维场景主题进行动画融合,生成人体在实景中的动态连贯的案发现场人物视频。本发明能替代人工对繁杂信息的收集及处理,有利于办案效率的整体提升。
技术研发人员:王璐,周炼赤,王红艳,周益周,孙宇
受保护的技术使用者:北京计算机技术及应用研究所
技术研发日:
技术公布日:2024/1/22
- 还没有人留言评论。精彩留言会获得点赞!