基于深度强化学习的微电网优化能量管理系统的制作方法
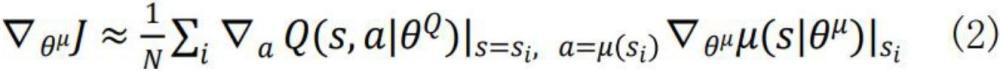
本发明涉及智能电网管理,尤其涉及基于深度强化学习的微电网优化能量管理系统。
背景技术:
1、微电网是一种以可再生能源、储能系统和传统能源系统为主要能源来源,通过能量管理系统实现能源的自主管理和优化利用的能源系统。微电网能量管理系统技术是微电网的关键技术之一,它通过智能化、自适应等技术手段,实现微电网的能量管理、优化调度、安全保障等功能。
2、微电网能量管理系统技术的发展已经取得了很大的进展,但是仍然存在一些挑战和问题,尤其在工业落地方面。其现有技术水平主要表现在以下几个方面:1、现有的微电网能量管理系统能够通过对微电网内各种能源的监测、分析和预测等手段,实现能源的合理分配和优化利用。但是,面对复杂的微电网结构、多样的能源类型和时空变化的需求,仍需要进一步提高算法的精度和实时性,以实现更加智能化、自适应的能源管理和调度;2、微电网的能源来源和管理方式更加多元化和复杂化,其安全保障也面临着更加复杂的挑战。现有的微电网能量管理系统能够通过安全监测、控制和响应等手段,提高微电网的安全性和稳定性。但是,随着微电网规模的扩大和复杂度的增加,其安全保障技术仍需进一步加强;3、微电网的商业模式需要实现对能源的市场化交易,而微电网能量管理系统则需要与能源市场化的需求相匹配,提供相应的技术支持和保障。现有的微电网能量管理系统已经开始探索新的商业模式,如能源共享、虚拟电厂等,但仍需要更加深入的研究和实践。
技术实现思路
1、本发明就是针对上述问题,提出一种基于深度强化学习的微电网优化能量管理系统,用以解决上述问题。
2、为达到上述技术目的,本发明采用了基于深度强化学习的微电网优化能量管理系统,采用drl中的soft actor-critic(sac算法,通过使用softmax函数将离散动作转换为概率分布,然后将概率分布映射到实数空间,同时实现了离散化动作空间集的控制,所述sac的具体训练过程包括以下步骤:
3、步骤一:采样数据:从环境中采样一批数据,包括状态、动作、奖励和下一个状态等信息。
4、步骤二:计算q值:使用值函数q来计算采样数据的奖励估计值,以便用于后续的策略学习和更新。
5、步骤三:更新策略:通过最小化损失函数来更新策略π的参数,损失函数包括两部分:第一部分是策略梯度,用于提高奖励值;第二部分是熵正则化,用于提高探索性。
6、步骤四:更新值函数:使用采样数据和策略π来更新值函数q的参数,以提高对累积奖励的估计。
7、步骤五:更新目标策略:使用软更新策略,将当前策略的参数更新到目标策略中,以提高算法的稳定性。
8、优选的,所述drl核心算法,包括dqn和ddpg,所述dqn适用于电力系统中控制变量为离散量的场景,所述ddpg适用于电力系统中控制变量为连续量的应用场景;
9、在dqn方法中使用神经网络更新q值的流程可描述为:
10、q′(s,a)=q(s,a)+α[r+γmaxq(s′,a′)-q(s,a)] (1)
11、式(1)中,s代表系统状态;a代表控制动作;α代表学习率;γ是衰减率;r是奖惩函数/值;q(s,a)则代表在状态s下采取动作a的值函数的q值;
12、所述ddpg的算法为:
13、
14、其中控制动作可以通过“演员”策略函数a=μ(s|θμ)直接算出;θμ是策略网络参数,而θq则是值函数网络中的参数。定义那么“评论家”的值函数网络可以通过式(3)来更新,以最小化偏差:
15、
16、在ddpg算法中,目标网络的更新方式如式(4)所示,其中τ是一个较小的更新系数:
17、
18、进一步优选的,所述步骤三中的更新策略和奖励值包括:
19、将系统节点电压幅值分为三类:即正常区域[0.95,1.05]pu、越限区域[0.8,0.95]pu或[1.05,1.25]pu和发散区域[<0.8或>1.25]pu。定义vj为母线j的电压幅值,那么控制动作的第i次迭代奖励值可用式(5)来计算:
20、
21、通过式(5)可使drl agent朝着安全范围控制节点电压。为了得到更有效的控制策略(一次迭代解决电压问题),每个训练样本的最终奖励值rf可定义为一个完整样本内所有控制迭代所得奖励的平均值:
22、
23、其中n为完成一个训练样本后所采取的控制迭代总次数。
24、采用上述技术改进后,本发明具有如下优点:
25、1、本发明对于复杂任务具有很强的表现能力:深度强化学习通过使用深度神经网络等模型,能够对复杂环境和任务进行建模,从而学习到更加高层次的特征和表示。
26、2、本发明无需手工设计特征:与传统的机器学习方法不同,深度强化学习可以直接从原始输入数据中学习特征,无需手工设计特征,大大降低了算法的开发成本和难度。
27、3、本发明能够处理高维状态空间和动作空间:深度强化学习能够有效处理高维状态空间和动作空间,适用于复杂的控制问题,如自动驾驶、机器人控制等。
28、4、本发明具有自适应性:深度强化学习可以根据任务的变化和环境的变化,自适应地调整策略,从而具有更好的适应性和泛化性。
技术特征:
1.基于深度强化学习的微电网优化能量管理系统,其特征在于,采用drl中的softactor-critic(sac算法,通过使用softmax函数将离散动作转换为概率分布,然后将概率分布映射到实数空间,同时实现了离散化动作空间集的控制,所述sac的具体训练过程包括以下步骤:
2.如权利要求1所述的基于深度强化学习的微电网优化能量管理系统,其特征在于,所述drl核心算法,包括dqn和ddpg,所述dqn适用于电力系统中控制变量为离散量的场景,所述ddpg适用于电力系统中控制变量为连续量的应用场景;
3.如权利要求1所述的基于深度强化学习的微电网优化能量管理系统,其特征在于,所述步骤三中的更新策略和奖励值包括:
技术总结
本发明公开了基于深度强化学习的微电网优化能量管理系统,采用DRL中的Soft Actor‑Critic(SAC算法,通过使用softmax函数将离散动作转换为概率分布,然后将概率分布映射到实数空间,同时实现了离散化动作空间集的控制,所述SAC的具体训练过程包括采样数据、计算Q值、更新策略、更新值函数、以及更新目标策略,本发明对于复杂任务具有很强的表现能力:深度强化学习通过使用深度神经网络等模型,能够对复杂环境和任务进行建模,从而学习到更加高层次的特征和表示。
技术研发人员:南云,段嘉俊,王雅婷,田婕丽,李小仕,廖海浩,季娓,李卫莲
受保护的技术使用者:浙江云碳科技有限公司
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!