基于多叉树和大规模语言模型的文档问答方法及相关设备与流程
本申请涉及深度学习,尤其涉及一种基于多叉树和大规模语言模型的文档问答方法及相关设备。
背景技术:
1、随着互联网的快速发展和大量信息的产生,人们需要从海量文档中快速获取准确的信息,以便更好地应对工作和生活中的各种需求。文档问答技术的出现填补了这一需求,文档问答的目标是通过深入理解问题和文档之间的语义关系,从文档中提取出与问题相关的信息,并生成准确的答案。不仅要理解问题的含义和背景,还要理解文档中的内容和上下文信息。
2、目前,文档问答技术存在一些缺陷,在长文档中所有的文本切分后,都作为一个单独的文本块进行处理,忽视了多级标题之间以及标题与正文之间的层级结构,导致标题与正文强关联性没有充分利用,不利于定位和检索与问题相关的答案。
技术实现思路
1、有鉴于此,本申请的目的在于提出一种基于多叉树和大规模语言模型的文档问答方法及相关设备,以解决上述部分或全部问题。
2、基于上述目的,本申请的第一方面提供了一种基于多叉树和大规模语言模型的文档问答方法,包括:
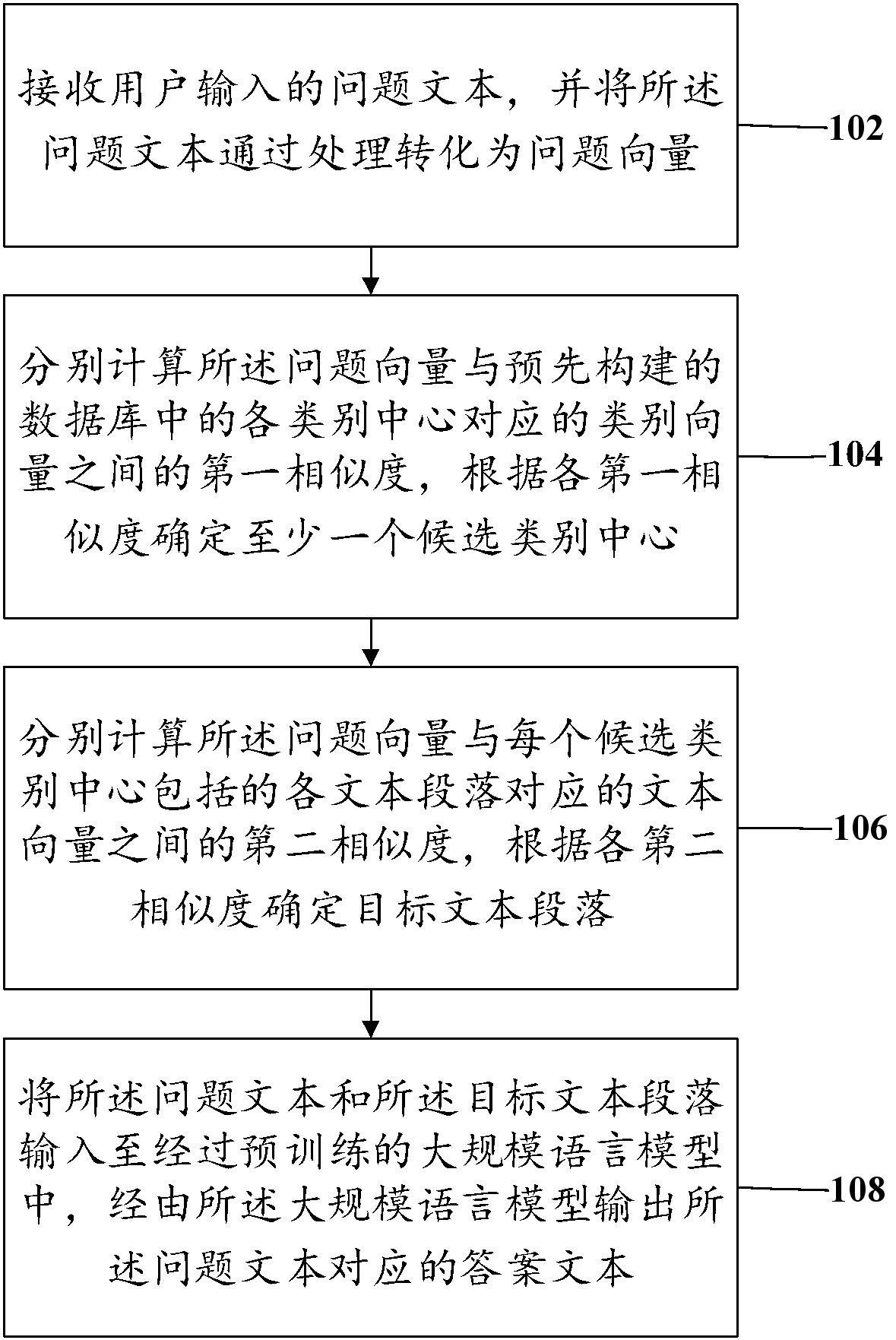
3、接收用户输入的问题文本,并将所述问题文本通过处理转化为问题向量;
4、分别计算所述问题向量与预先构建的数据库中的各类别中心对应的类别向量之间的第一相似度,根据各第一相似度确定至少一个候选类别中心;
5、分别计算所述问题向量与每个候选类别中心包括的各文本段落对应的文本向量之间的第二相似度,根据各第二相似度确定目标文本段落;
6、将所述问题文本和所述目标文本段落输入至经过预训练的大规模语言模型中,经由所述大规模语言模型输出所述问题文本对应的答案文本。
7、可选的,构建所述数据库,包括:
8、获取目标文档;
9、基于所述目标文档的层级结构构建多叉树;
10、基于所述多叉树以及所述目标文档确定各类别中心;
11、将所述目标文档与各类别中心建立映射关系,以完成所述数据库的构建。
12、可选的,所述基于所述目标文档的层级结构构建多叉树,包括:
13、对所述目标文档进行划分,以得到多个文本段落;
14、根据每个文本段落在所述目标文档中的位置信息,确定每个文本段落对应的等级和标识;
15、根据各文本段落对应的等级和标识构建所述多叉树,其中,每个文本段落对应所述多叉树中的一个节点。
16、可选的,所述基于所述多叉树以及所述目标文档确定各类别中心,包括:
17、将每个文本段落通过处理转化为对应的初始向量;
18、确定所述多叉树中每个叶子节点到根节点对应的路径;
19、根据所述路径中包含的所有节点对应的初始向量,得到所述叶子节点对应的文本段落的文本向量;
20、采用聚类算法对全部叶子节点对应的文本向量进行聚类,确定各类别中心。
21、可选的,所述根据所述路径中包含的所有节点对应的初始向量,得到所述叶子节点对应的文本段落的文本向量,包括:
22、根据各节点对应的初始向量以及预设权重系数,计算得到所述叶子节点对应的文本段落的文本向量。
23、可选的,所述将所述目标文档与各类别中心建立映射关系,以完成所述数据库的构建,包括:
24、将每个文本向量与各类别中心建立映射关系,以完成所述数据库的构建。
25、可选的,所述将所述问题文本和所述目标文本段落输入至经过预训练的大规模语言模型中,经由所述大规模语言模型输出所述问题文本对应的答案文本,包括:
26、将所述问题文本、所述目标文本段落以及预设约束条件输入至经过预训练的大规模语言模型中,经由所述大规模语言模型输出所述问题文本对应的答案文本。
27、本申请的第二方面提供了一种基于多叉树和大规模语言模型的文档问答装置,包括:
28、接收模块,被配置为接收用户输入的问题文本,并将所述问题文本通过处理转化为问题向量;
29、第一确定模块,被配置为分别计算所述问题向量与预先构建的数据库中的各类别中心对应的类别向量之间的第一相似度,根据各第一相似度确定至少一个候选类别中心;
30、第二确定模块,被配置为分别计算所述问题向量与每个候选类别中心包括的各文本段落对应的文本向量之间的第二相似度,根据各第二相似度确定目标文本段落;
31、输出模块,被配置为将所述问题文本和所述目标文本段落输入至经过预训练的大规模语言模型中,经由所述大规模语言模型输出所述问题文本对应的答案文本。
32、本申请还提供了一种电子设备,包括存储器、处理器及存储在所述存储器上并可由所述处理器执行的计算机程序,所述处理器在执行所述计算机程序时实现如上所述的方法。
33、本申请还提供了一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令用于使计算机执行如上所述的方法。
34、从上面所述可以看出,本申请提供的基于多叉树和大规模语言模型的文档问答方法及相关设备,所述方法包括接收用户输入的问题文本,并将所述问题文本通过处理转化为问题向量,以便后续采用相似度算法计算问题文本与数据库中文本段落之间的相似度。分别计算所述问题向量与预先构建的数据库中的各类别中心对应的类别向量之间的第一相似度,根据各第一相似度确定至少一个候选类别中心,通过从数据库中选取与问题向量相似度较高的候选类别中心,有效减小搜索范围,提高搜索效率。分别计算所述问题向量与每个候选类别中心包括的各文本段落对应的文本向量之间的第二相似度,根据各第二相似度确定目标文本段落。确定了候选类别中心后,再从候选类别中心包含的文本段落中选取与问题向量相似度最高的文本向量对应的文本段落作为目标文本段落,通过两次相似度的计算,能够快速确定与问题向量最接近的文本段落,提高文档问答的效率和准确率。将所述问题文本和所述目标文本段落输入至经过预训练的大规模语言模型中,经由所述大规模语言模型输出所述问题文本对应的答案文本,大模型能够处理跨领域和复杂的问题,根据输入的问题文本和目标文本段落进行推理,进而给出更加准确的答案文本。
技术特征:
1.一种基于多叉树和大规模语言模型的文档问答方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,构建所述数据库,包括:
3.根据权利要求2所述的方法,其特征在于,所述基于所述目标文档的层级结构构建多叉树,包括:
4.根据权利要求3所述的方法,其特征在于,所述基于所述多叉树以及所述目标文档确定各类别中心,包括:
5.根据权利要求4所述的方法,其特征在于,所述根据所述路径中包含的所有节点对应的初始向量,得到所述叶子节点对应的文本段落的文本向量,包括:
6.根据权利要求4所述的方法,其特征在于,所述将所述目标文档与各类别中心建立映射关系,以完成所述数据库的构建,包括:
7.根据权利要求1所述的方法,其特征在于,所述将所述问题文本和所述目标文本段落输入至经过预训练的大规模语言模型中,经由所述大规模语言模型输出所述问题文本对应的答案文本,包括:
8.一种基于多叉树和大规模语言模型的文档问答装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至7任意一项所述的方法。
10.一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,其特征在于,所述计算机指令用于使计算机执行权利要求1至7任一所述方法。
技术总结
本申请提供一种基于多叉树和大规模语言模型的文档问答方法及相关设备,所述方法包括接收用户输入的问题文本,并将所述问题文本通过处理转化为问题向量。分别计算所述问题向量与预先构建的数据库中的各类别中心对应的类别向量之间的第一相似度,根据各第一相似度确定至少一个候选类别中心。分别计算所述问题向量与每个候选类别中心包括的各文本段落对应的文本向量之间的第二相似度,根据各第二相似度确定目标文本段落。将所述问题文本和所述目标文本段落输入至经过预训练的大规模语言模型中,经由所述大规模语言模型输出所述问题文本对应的答案文本。本申请提供的问答方法提升了问答检索的效率和准确率,提升用户的体验感。
技术研发人员:余梓飞,朵思惟,刘双勇,张程华,薛晨云,张艳丽
受保护的技术使用者:天津汇智星源信息技术有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!