基于遗传算法的有源配电网采集可信区段识别方法与流程
本发明属于配电网领域,具体涉及一种针对有源配电网的识别采集可信区段的识别方法。
背景技术:
1、配电网中,只有部分开关上采集了有功、无功、电流等量测值。在这些采集信息都准确、方向也正确的情况下,这些开关合围成的区域可以认为是“采集可信区段”。在无源配电网中,通过配网状态估计即可识别出可信数据和正确方向,形成采集可信区段。
2、近年来,随着经济的快速提升,有源配电网得到快速发展。而在有源配电网中,以负荷分配等方法进行状态估计存在较大误差,甚至会出现潮流方向识别错误的问题,通过传统方式形成的采集可信区段不再可信,从而导致有源配电网运行方式优化的计算基础被破坏,使得部分建立在配电网的分析应用无法适应有源配电网的变化。
技术实现思路
1、本发明提出了一种基于遗传算法的有源配电网采集可信区段识别方法,其目的是:解决有源配电网中采集可信区段无法正确识别的问题。
2、本发明技术方案如下:
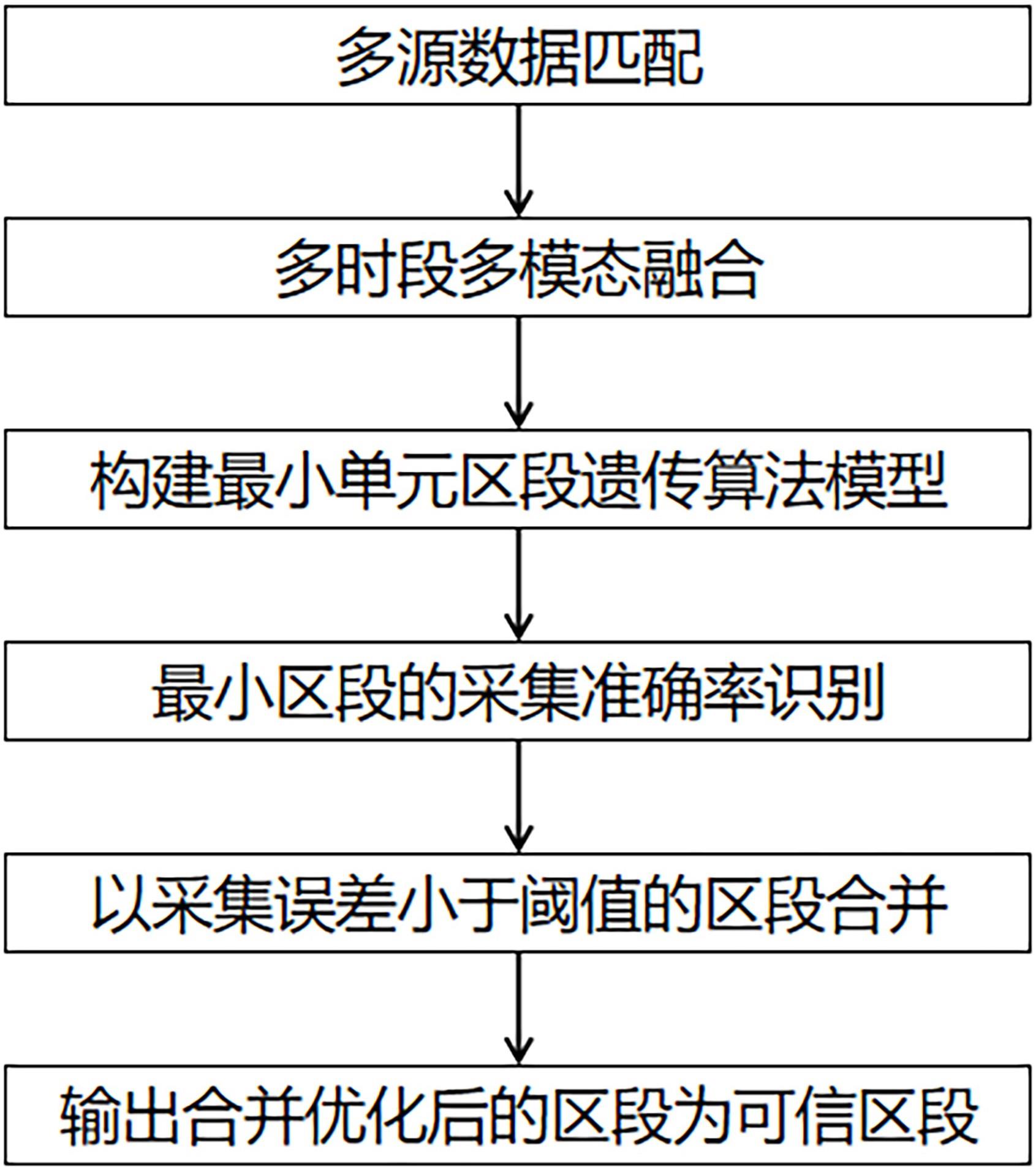
3、一种基于遗传算法的有源配电网采集可信区段识别方法,包括以下步骤:
4、步骤s1、对有源配电网进行多源数据的匹配;
5、步骤s2、将匹配后的数据进行多时段多模态融合;
6、步骤s3、建立有源配电网最小单元区段的遗传算法模型;
7、步骤s4、将融合后的数据输入到遗传算法模型中求解;
8、步骤s5、根据模型求解结果进行有源配电网最小单元区段的采集准确率识别和区段合并优化;
9、步骤s6、输出合并优化后的区段为采集可信区段。
10、作为所述基于遗传算法的有源配电网采集可信区段识别方法的进一步改进,步骤s1中,多源数据包括:有源配电网的配网模型数据,scada采集数据,以及户号数据;
11、所述配网模型中包括以下配网设备:站内母线、配网线路段、开关、刀闸、配网母线和变压器;
12、匹配时,将scada采集数据与对应的配网设备相关联,将户号数据与对应的变压器相关联。
13、作为所述基于遗传算法的有源配电网采集可信区段识别方法的进一步改进,步骤s1中,所述户号数据包括户号的用电信息采集点数据和电力营销采集点数据;对于某个户号,如果采集到了对应的用电信息采集点数据则将用电信息采集点数据中的有功量作为户号数据,否则将对应的电力营销采集点数据中的电量按对应的时长转换为有功量,然后将该有功量作为户号数据。
14、作为所述基于遗传算法的有源配电网采集可信区段识别方法的进一步改进,步骤s2中多时段多模态融合的方法为:
15、步骤s2-1、确定时段的时长,将采集数据总时间划分为多个连续的时段;
16、步骤s2-2、将scada采集数据和户号数据按采集的时间分配到对应的各个时段内;
17、步骤s2-3、对各时段中的数据进行处理:
18、如果scada采集数据的采集时间间隔小于时段时长,则对每个时段中的scada采集数据中的有功采集量进行数学平均,将平均值作为对应时段的scada采集数据,同时,将各时段内出现的开关状态变化,视为发生在对应时段的末尾;
19、如果户号数据的采集时间间隔小于时段的时长,则对每个时段中的户号数据中的有功量进行数学平均,将平均值作为对应时段的户号数据。
20、作为所述基于遗传算法的有源配电网采集可信区段识别方法的进一步改进,步骤s3中,建立遗传算法模型的方式为:
21、步骤s3-1、将配网模型中配网设备之间的连接端定义为节点,然后进行节点等效合并:将位置为合位的刀闸的两端节点进行合并,同时将配网线路段两端的节点进行合并,从而得到一个节点上连接变压器、站内母线和配网母线,同时节点间以开关分界的等效拓扑模型;
22、步骤s3-2、将等效拓扑模型中与变压器直接连接的节点定义为a类节点,其它节点定义为b类节点;
23、计算等效拓扑模型的每个a类节点在各时段的等值负荷:对于某个a类节点,根据步骤s1中创建的户号数据与变压器之间的关联关系找到与该节点关联的户号数据,将关联的且经过融合的各户号数据中有功量的负荷部分累计到该节点的等值负荷中,有功量的出力部分取反累计到该节点的等值负荷中;如果等效拓扑模型中的第j个节点属于a类节点,则将第j个节点在第i个时段的等值负荷记为pi,j;
24、步骤s3-3、为等效拓扑模型中每个开关定义始端和末端,将始端流向末端定义为正向、即有功大于0,将第k个开关在第i时段的有功记为pbri,k;将融合后的scada采集数据中第k个开关在第i个时段的状态记为ki,k,开关状态为合位则ki,k=1,开关状态为分位则ki,k=0;
25、步骤s3-4、定义遗传算法模型的目标函数为:
26、
27、式中,min表示求最小值,abs表示取绝对值,n为时段的总数量,m为等效拓扑模型中节点的总数,sl为等效拓扑模型中b类节点的集合;lj为第j个节点的网损系数,为浮点型决策变量,取值范围为-1.5~1.5;sj为等效拓扑模型中合围第j个节点的开关的集合;rbrk为第k个开关的有功取反标志,为整数型决策变量,其取值为-1或1;dirj,k为取反标志,当第j个节点是第k个开关的始端时,其值为1,否则为-1。
28、作为所述基于遗传算法的有源配电网采集可信区段识别方法的进一步改进,步骤s4中求解遗传算法模型时,进化算法选种马算法。
29、作为所述基于遗传算法的有源配电网采集可信区段识别方法的进一步改进,步骤s5的具体方法为:对于求得的第j个节点的网损系数lj,如果该网损系数超出了预设阈值范围,则认为与该节点相连接的开关的scada采集数据的采集准确率不满足要求,将该开关判定为采集不可信,舍弃该开关,并将该开关两侧的区段合并为一个区段;未被判定为采集不可信的开关加入采集可信开关列表。
30、作为所述基于遗传算法的有源配电网采集可信区段识别方法的进一步改进,步骤s6的具体步骤为:
31、将步骤s5合并后的区段数据进行整理输出,内容包含:
32、1)采集可信开关列表,以及采集可信的开关所对应的有功取反标志;
33、2)由采集可信合围的采集可信区段及二者间的对应关系,采集可信区段内的户号列表。
34、相对于现有技术,本发明具有以下有益效果:本发明对配电自动化scada采集数据、用电信息采集点数据、电力营销采集点数据等进行多模态融合,并基于遗传算法建立了求解模型,然后依据求解结果完成了有源配电网最小单元区段的采集准确率识别和区段合并优化,最终实现了有源配电网采集可信区段的准确识别。本发明充分考虑了有源配电网的经济技术水平现状,为有源配电网的分析优化以及碳流精细化计算提供了坚实可信的数据基础。
技术特征:
1.一种基于遗传算法的有源配电网采集可信区段识别方法,其特征在于包括以下步骤:
2.如权利要求1所述的基于遗传算法的有源配电网采集可信区段识别方法,其特征在于:步骤s1中,多源数据包括:有源配电网的配网模型数据,scada采集数据,以及户号数据;
3.如权利要求2所述的基于遗传算法的有源配电网采集可信区段识别方法,其特征在于:步骤s1中,所述户号数据包括户号的用电信息采集点数据和电力营销采集点数据;对于某个户号,如果采集到了对应的用电信息采集点数据则将用电信息采集点数据中的有功量作为户号数据,否则将对应的电力营销采集点数据中的电量按对应的时长转换为有功量,然后将该有功量作为户号数据。
4.如权利要求2或3所述的基于遗传算法的有源配电网采集可信区段识别方法,其特征在于:步骤s2中多时段多模态融合的方法为:
5.如权利要求4所述的基于遗传算法的有源配电网采集可信区段识别方法,其特征在于:步骤s3中,建立遗传算法模型的方式为:
6.如权利要求5所述的基于遗传算法的有源配电网采集可信区段识别方法,其特征在于:步骤s4中求解遗传算法模型时,进化算法选种马算法。
7.如权利要求5或6所述的基于遗传算法的有源配电网采集可信区段识别方法,其特征在于步骤s5的具体方法为:对于求得的第j个节点的网损系数lj,如果该网损系数超出了预设阈值范围,则认为与该节点相连接的开关的scada采集数据的采集准确率不满足要求,将该开关判定为采集不可信,舍弃该开关,并将该开关两侧的区段合并为一个区段;未被判定为采集不可信的开关加入采集可信开关列表。
8.如权利要求7所述的基于遗传算法的有源配电网采集可信区段识别方法,其特征在于步骤s6的具体步骤为:
技术总结
本发明公开了一种基于遗传算法的有源配电网采集可信区段识别方法,包括以下步骤:步骤S1、对有源配电网进行多源数据的匹配;步骤S2、将匹配后的数据进行多时段多模态融合;步骤S3、建立有源配电网最小单元区段的遗传算法模型;步骤S4、将融合后的数据输入到遗传算法模型中求解;步骤S5、根据模型求解结果进行有源配电网最小单元区段的采集准确率识别和区段合并优化;步骤S6、输出合并优化后的区段为采集可信区段。本发明充分考虑了有源配电网的经济技术水平现状,为有源配电网的分析优化以及碳流精细化计算提供了坚实可信的数据基础。
技术研发人员:李东梧
受保护的技术使用者:杭州新跃电力科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!