一种大数据自适应采集方法与流程
本发明涉及大数据治理与融合,特别涉及一种大数据自适应采集方法。
背景技术:
1、大数据治理是指以最大限度地发挥数据价值、最小化生产风险为目标的数据管理过程。数据治理的作用在于保证数据的正规化以及减少数据的冗余;数据治理的核心是计划、监测和实施。其中,数据治理的规划指的是对管理数据模型的标准化进行定义,用户能够创建满足业务要求的标准模型,并对模型的属性及规则进行配置,从而设计质检规则和数据清洗原则等。数据治理的监测指的是对数据信息展开一次预览,并对表的血缘关系和字段的血缘关系进行跟踪,从而对数据在数据治理过程中的整个生命周期进行全面的把握。数据治理的实施指的是在对数据清洗、数据集中、质量稽核的规则和标准进行配置之后,进行的详细的数据治理服务。
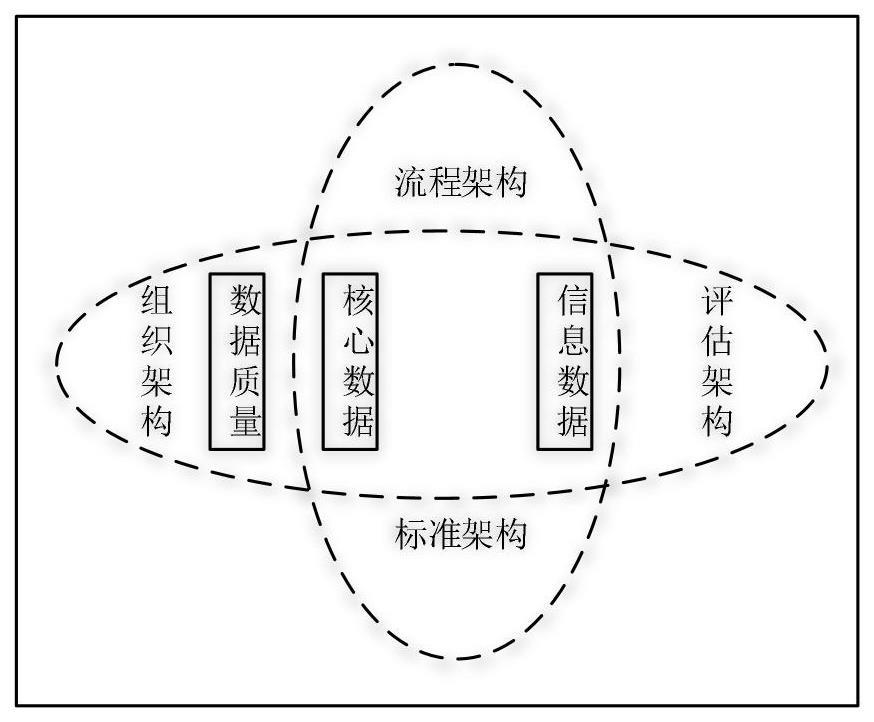
2、大数据治理是一个需要持续实施的、繁琐的、需要研究者们不断探究的项目,大数据治理的框架如图1所示,其包括组织、标准、流程、技术和评价五个架构方面的工作任务。
3、在信息技术飞速发展的背景下,大数据的涌现与应用越来越广泛,对大数据的管理与融合也提出了新的挑战。大数据治理旨在对大数据进行有效的管理、整合与分析,确保数据的高质量、高一致性与高安全性。大数据融合是指将多源、多形式、多领域的多维数据进行集成与关联,从而得到更加全面、准确、有价值的信息。
4、针对大数据治理和融合问题,国内外学者已开展了大量研究。在大数据治理领域,已有部分研究侧重于数据质量评价与清洗,例如缺失值处理,噪音数据过滤等。此外,还有学者对数据加密、访问控制、隐私脱敏等数据安全与隐私保护方法进行研究。在大数据融合领域,针对异构、不一致等问题,研究人员提出了相应的数据匹配与融合算法。另外,研究人员还提出了从多源数据中挖掘出隐含的关系和模式的相关算法。
5、然而,目前虽然有一些关于大数据治理和融合的研究,但还存在一些问题,如缺乏标准规范,缺少实践验证和应用实例等。为此,研究拟从数据收集和数据安全两个角度出发,针对已有算法在标准统一、数据适应性强、数据处理规模大、实用化等方面存在的局限性,提出一套适用于大数据治理的自适应算法。
技术实现思路
1、本发明要解决的技术问题,在于提供一种大数据自适应采集方法,在数据采集方面,能够根据数据特征和变化自动调整采集的时间间隔,具有较低的失真度,能够提高数据采集的精度。
2、本发明提供了一种大数据自适应采集方法,其特征在于:使用bisquare算法来构造一元线性回归模型,并利用所述一元线性回归模型来感知数据的变化,并根据所述一元线性回归模型倾斜度动态调节采集的时间间隔,所述动态调节包括下述步骤:
3、s1、通过最小二乘法将最近的有限个离散数据点m2(x2,y2),m1(x1,y1)…mn(xn,yn)进行线性拟合,然后得到拟合模型的初始斜率和截距的估计值ai与bi:
4、
5、
6、式中,为离散数据点的y轴坐标平均值,为离散数据点的x轴坐标平均值,i为离散数据点的序号,n为y的长度;
7、s2、利用残差最小化的方法得到权重的更新值,残差最小化的计算式为:
8、
9、f'i=aix+bi (4);
10、式中,e为数据点的权重的残差值,yi为不同离散数据点的y轴坐标值,wi为对应数据点的权重,fi为对应数据点的最佳拟合值,f'i为对应数据点的导数值,x为离散数据点的x轴坐标值;
11、s3、根据已经得到的a0和b0,然后利用残差最小化对式(4)中的ai进行求导并使e等于零,可得:
12、
13、s4、将新获得的权重wi做加权最小二乘法,得到第i+2个离散数据点的斜率ai+2与截距bi+2:
14、
15、
16、s5、通过反复所述步骤s4实现迭代,直到迭代前后两次拟合多项式的斜率和截距、之间的相对差小于容差值时结束,此时拟合模型达到最佳状态,在此状态下,输出最佳拟合斜率;
17、s6、根据得到的最佳拟合斜率所处的范围,确定下次采集的时间间隔。
18、进一步的,所述s6具体是:如果斜率绝对值|ai+2|越小,则选择越大的采集时间间隔;相反,如果斜率绝对值|ai+2|越大,则选择越小的采集时间间隔。
19、进一步的,在确定下次采集的时间间隔后,所述大数据自适应采集方法在下一次数据采集时,将最优拟合模型的上下界与标准数据源差分,将差分超过0的点作为异常数据点进行排除。
20、进一步的,在数据存储时,还通过大数据安全模型进行安全保护,所述大数据安全模型采用的数据保密机制包括用户的离线培训、模型的确认与存储以及模型的聚集;所述用户的离线培训是利用差分隐私技术来对本地数据进行深度学习,实时更新密码权值和局域错误,并将其上传至星际文件系统ipfs节点,并将其哈希值压缩成协议;所述模型的确认与存储和所述模型的聚集均是用户下载已被确认的交易,并通过各个地址下载对应的权值,完成模型聚集,确认后向区块链更新。
21、进一步的,所述离线培训是利用仿真实验来对以区块链为平台的基于隐私保护的深度学习进行协同训练,采用多层次感知器和卷积神经网络这两种最基本的建模方法,分别对独立同分布和非独立同分布两种数据进行建模,并从数据压缩速率、训练精度、训练效率三个角度对算法的性能进行评价。
22、本发明实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:在数据采集方面,使用bisquare算法来构造一元线性回归模型,并利用所述一元线性回归模型来准确感知数据的变化,通过降低噪声数据的影响,并根据所述一元线性回归模型倾斜度动态调节采集的时间间隔,具有较低的失真度,能够提高数据采集的精度。在数据存储方面,基于区块链技术的大数据隐私保护算法能够使得数据压缩率达到0.0018,一方面具有较好的数据存储效果,在ipfs中的压缩率较高,减少了存储成本;另一方面,在保证数据隐私的同时保持了模型的高可用性。
23、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
技术特征:
1.一种大数据自适应采集方法,其特征在于:使用bisquare算法来构造一元线性回归模型,并利用所述一元线性回归模型来感知数据的变化,并根据所述一元线性回归模型倾斜度动态调节采集的时间间隔,所述动态调节包括下述步骤:
2.根据权利要求1所述的一种大数据自适应采集方法,其特征在于:所述s6具体是:如果斜率绝对值|ai+2|越小,则选择越大的采集时间间隔;相反,如果斜率绝对值|ai+2|越大,则选择越小的采集时间间隔。
3.根据权利要求1所述的一种大数据自适应采集方法,其特征在于:在确定下次采集的时间间隔后,所述大数据自适应采集方法在下一次数据采集时,将最优拟合模型的上下界与标准数据源差分,将差分超过0的点作为异常数据点进行排除。
4.根据权利要求1所述的一种大数据自适应采集方法,其特征在于:在数据存储时,还通过大数据安全模型进行安全保护,所述大数据安全模型采用的数据保密机制包括用户的离线培训、模型的确认与存储以及模型的聚集;所述用户的离线培训是利用差分隐私技术来对本地数据进行深度学习,实时更新密码权值和局域错误,并将其上传至星际文件系统ipfs节点,并将其哈希值压缩成协议;所述模型的确认与存储和所述模型的聚集均是用户下载已被确认的交易,并通过各个地址下载对应的权值,完成模型聚集,确认后向区块链更新。
5.根据权利要求4所述的一种大数据自适应采集方法,其特征在于:所述离线培训是利用仿真实验来对以区块链为平台的基于隐私保护的深度学习进行协同训练,采用多层次感知器和卷积神经网络这两种最基本的建模方法,分别对独立同分布和非独立同分布两种数据进行建模,并从数据压缩速率、训练精度、训练效率三个角度对算法的性能进行评价。
技术总结
本发明提供一种方法大数据自适应采集方法,使用Bisquare算法来构造一元线性回归模型来感知数据的变化,并根据倾斜度动态调节采集的时间间隔,具体是通过最小二乘法将最近的有限个离散数据点进行线性拟合,得到拟合模型的初始斜率和截距的估计值,利用残差最小化的方法得到权重的更新值,利用残差最小化对初始斜率进行求导并使其等于零,将新获得的权重w<subgt;i</subgt;做加权最小二乘法,得到a<subgt;i+2</subgt;与b<subgt;i+2</subgt;;通过反复进行以上过程,当迭代前后两次拟合多项式的斜率和截距之间的相对差小于容差值时,拟合模型达到最佳状态,根据得到的最佳拟合斜率确定下次采集的时间间隔。具有较低的失真度,能够提高数据采集的精度。
技术研发人员:陈雯珊,王辉,杨璐璐,刘晗之,刘凌坤,林健,梁诗瑶,许燕萍,吴明魁
受保护的技术使用者:福建省星云大数据应用服务有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!