基于迪杰斯特拉算法的文本生成方法、系统、介质及终端与流程
本发明涉及自然语言文本生成,具体地,涉及一种基于迪杰斯特拉算法的文本生成方法、系统、介质及终端。
背景技术:
1、自然语言文本生成技术通常是由预训练语言模型(以下简称语言模型)根据用户输入的一段文本(记为input)来预测语言模型的词典中每个字或词作为下一个token(字或词)的概率,然后基于某个选择算法从中选择一个token作为输出;输出的token追加在input末尾,形成新的input,再输入到语言模型中预测和挑选下一个token并追加在input末尾,循环往复,直到满足一定的条件(比如遇到某个特定符号或者input已经达到预设长度),停止这个过程,输出最后生成的文本。例如,给定文本input=“人工智能对社会的影响,是一个非常大的话题。我认为人工神经网路是一个重”,输入到语言模型中,语言模型会给出这样的概率:[大0.10695966,要0.10234697,点0.03686523,…](不同的语言模型可能输出不同的概率,这里仅是一个例子)。
2、从上面的过程中可以看出,给定一段文本,生成出来的文本的内容是什么,或者说它的生成质量,由两个方面决定:(1)语言模型给出的每个token的概率,(2)从这些token中选择某一个作为输出的选择算法。本专利基于在给定语言模型的情况下,设计一个下一个token的选择算法。
3、现有技术中文本生成选择算法有以下5种:1)greedy贪心法,2)beam search,3)top-k sampling,4)top-p sampling,5)对比搜索文本解码算法(constrastive searchdecoding)。但是在现有技术中,以上所有的解码算法都是局部最优算法!都是只看当前一步中的token,并且只生成惟一一个input,所以无法对比这个input中各个token的累加的概率,无法保证这个累加概率是最优的。
4、具体来讲,文本生成是一个token一个token地生成的,需要经过n步才能生成n个token的文本。目前最流行的几种文本生成选择算法在生成token的每一步中,这些算法无一例外地都只从当前经过该算法过滤出来的若干个(贪心法是一个,beam search是b个,top-k sampling是k个、top-p sampling是p个)token中选择一个概率最高的作为下一个token输出。发明人经过仔细的研究和测试,发现这几种文本生成选择算法存在以下共同的问题:
5、1、每一步token的选择,都是选择当前最优的token,而没有从全局角度考虑,所以它不一定是全局最优的token。
6、2、由于问题1,最终生成的文本,如果从概率累积角度来评价文本质量的话,那么它不一定是最优的。
7、因此,市场上需要一种所生成的文本总会包含相同长度的所有文本中最优的文本的基于迪杰斯特拉算法的文本生成方法、系统、介质及终端。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种基于迪杰斯特拉算法的文本生成方法、系统、介质及终端。
2、根据本发明提供的一种基于迪杰斯特拉算法的文本生成方法,包括:
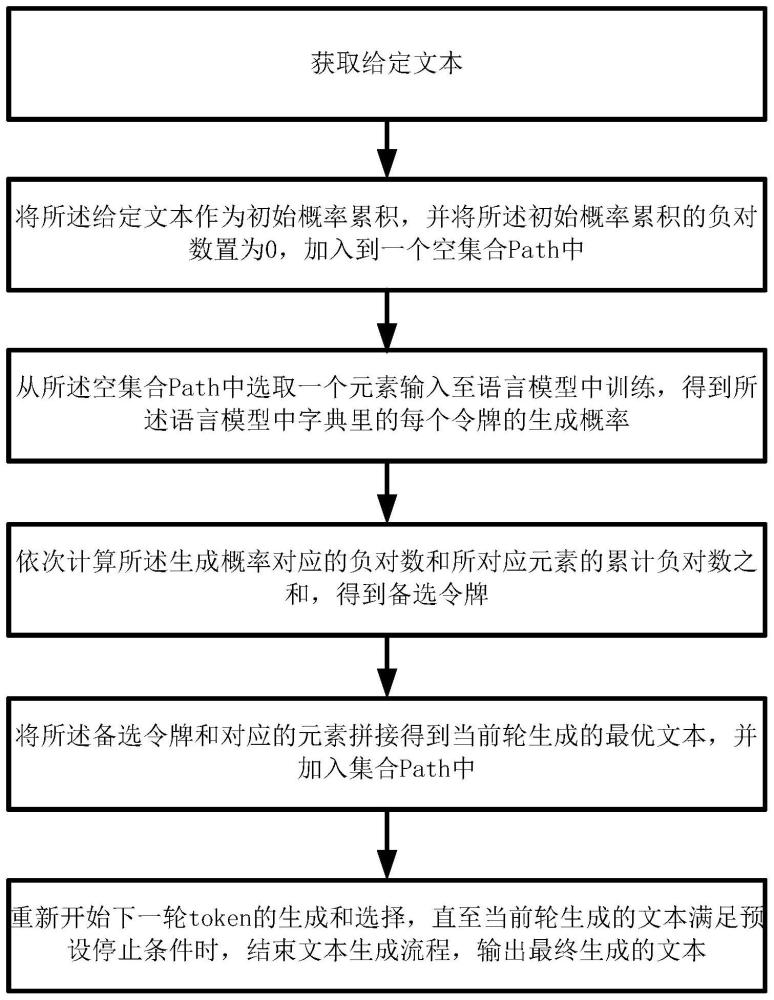
3、步骤s1:获取给定文本;
4、步骤s2:将所述给定文本作为初始概率累积,并将所述初始概率累积的负对数置为0,加入到一个空集合path中;
5、步骤s3:从所述空集合path中选取一个元素输入至语言模型中训练,得到所述语言模型中字典里的每个令牌的生成概率;
6、步骤s4:依次计算所述生成概率对应的负对数和所对应元素的累计负对数之和,得到备选令牌;
7、步骤s5:将所述备选令牌和对应的元素拼接得到当前轮生成的最优文本,并加入集合path中;
8、重复执行步骤s4至步骤s5,直至当前轮生成的文本满足预设停止条件时,结束文本生成流程,输出最终生成的文本。
9、优选地,所述步骤s4中包括选取所述生成概率对应的负对数和所对应元素的累计负对数之和中,取和最小的令牌作为备选令牌。
10、优选地,所述停止条件包括以特定符号结尾或者长度达到预设值。
11、优选地,所述每个令牌的生成概率为语言模型中字典里所有令牌参与下的概率分布,且所述概率是归一化的。
12、根据本发明提供的一种基于迪杰斯特拉算法的文本生成系统,其包括:
13、模块m1:获取给定文本;
14、模块m2:将所述给定文本作为初始概率累积,并将所述初始概率累积的负对数置为0,加入到一个空集合path中;
15、模块m3:从所述空集合path中选取一个元素输入至语言模型中训练,得到所述语言模型中字典里的每个令牌的生成概率;
16、模块m4:依次计算所述生成概率对应的负对数和所对应元素的累计负对数之和,得到备选令牌;
17、模块m5:将所述备选令牌和对应的元素拼接得到当前轮生成的最优文本,并加入集合path中;
18、重复触发模块m4至模块m5,直至当前轮生成的文本满足预设停止条件时,结束文本生成流程,输出最终生成的文本。
19、优选地,所述模块m4中包括选取所述生成概率对应的负对数和所对应元素的累计负对数之和中,取和最小的令牌作为备选令牌。
20、优选地,所述停止条件包括以特定符号结尾或者长度达到预设值。
21、优选地,所述每个令牌的生成概率为语言模型中字典里所有令牌参与下的概率分布,且所述概率是归一化的。
22、根据本发明提供的一种存储有计算机程序的计算机可读存储介质,所述计算机程序被处理器执行时实现所述的基于迪杰斯特拉算法的文本生成方法的步骤。
23、根据本发明提供的一种智能移动终端,包括所述的存储有计算机程序的计算机可读存储介质,或者包括所述的基于迪杰斯特拉算法的文本生成系统。
24、与现有技术相比,本发明具有如下的有益效果:
25、1、本发明基于迪杰斯特拉最优路径发现算法,能够生成全局最优的文本,文本质量高。
26、2、本发明在文本生成时,对于相同长度的,会先生成全局最优的,然后生成次优的、再是次次优的,也就是说本发明能够同时生成次优、次次优的多个文本。
27、3、本发明的文本生成效果不受temperature参数设置影响,无需人为调节,在减少人工成本的同时又能生成高质量的文本。
技术特征:
1.一种基于迪杰斯特拉算法的文本生成方法,其特征在于,包括:
2.根据权利要求1所述的基于迪杰斯特拉算法的文本生成方法,其特征在于,所述步骤s4中包括选取所述生成概率对应的负对数和所对应元素的累计负对数之和中,取和最小的令牌作为备选令牌。
3.根据权利要求1所述的基于迪杰斯特拉算法的文本生成方法,其特征在于,所述停止条件包括以特定符号结尾或者长度达到预设值。
4.根据权利要求1所述的基于迪杰斯特拉算法的文本生成方法,其特征在于,所述每个令牌的生成概率为语言模型中字典里所有令牌参与下的概率分布,且所述概率是归一化的。
5.一种基于迪杰斯特拉算法的文本生成系统,其特征在于,包括:
6.根据权利要求5所述的基于迪杰斯特拉算法的文本生成系统,其特征在于,所述模块m4中包括选取所述生成概率对应的负对数和所对应元素的累计负对数之和中,取和最小的令牌作为备选令牌。
7.根据权利要求5所述的基于迪杰斯特拉算法的文本生成系统,其特征在于,所述停止条件包括以特定符号结尾或者长度达到预设值。
8.根据权利要求5所述的基于迪杰斯特拉算法的文本生成系统,其特征在于,所述每个令牌的生成概率为语言模型中字典里所有令牌参与下的概率分布,且所述概率是归一化的。
9.一种存储有计算机程序的计算机可读存储介质,其特征在于,所述计算机程序被处理器执行时实现权利要求1至4中任一项所述的基于迪杰斯特拉算法的文本生成方法的步骤。
10.一种智能移动终端,其特征在于,包括权利要求9所述的存储有计算机程序的计算机可读存储介质,或者包括权利要求5至8中任一项所述的基于迪杰斯特拉算法的文本生成系统。
技术总结
本发明提供了一种基于迪杰斯特拉算法的文本生成方法、系统、介质及终端,包括:获取给定文本;将给定文本作为初始概率累积,并将初始概率累积的负对数置为0,加入到一个空集合Path中;从空集合Path中选取一个元素输入至语言模型中训练,得到语言模型中字典里的每个令牌的生成概率;依次计算生成概率对应的负对数和所对应元素的累计负对数之和,得到备选令牌;将备选令牌和对应的元素拼接得到当前轮生成的最优文本,并加入集合Path中;直至当前轮生成的文本满足预设停止条件时,结束文本生成流程,输出最终生成的文本。本发明基于迪杰斯特拉最优路径发现算法,能够生成全局最优的文本,文本质量高。
技术研发人员:李德启,王棚,陈杰,徐鑫朋,桑耘,张洁光,王盼盼,黄哲,牛硕硕,于铭华,王敬平,朱敏洁,杨佳卉,苏雨晨
受保护的技术使用者:华东计算技术研究所(中国电子科技集团公司第三十二研究所)
技术研发日:
技术公布日:2024/1/5
- 还没有人留言评论。精彩留言会获得点赞!