一种面向恶意代码图像的可解释性评估方法与流程
本发明属于网络安全,特别涉及一种面向恶意代码图像的可解释性评估方法。
背景技术:
1、随着计算机技术的快速发展,恶意代码的种类和数量不断增加,这增加了安全专业人员的挑战。近年来,智能化恶意代码检测方法逐渐受到重视,并取得了较好的结果。然而,基于深度学习的恶意代码检测模型存在着“黑盒”特性,缺乏可解释性,安全研究人员无法理解模型产出特定决策的原因,难以建立对模型决策的信任。恶意代码图像是一种表示恶意代码的图像,这种表示方法可以帮助安全专业人员更好地理解恶意代码的结构和行为。对恶意代码检测模型进行可解释性评估,增强恶意代码检测模型预测结果的可信度,可以帮助安全专业人员更准确地识别恶意代码,更好地保护计算机系统和网络。
技术实现思路
1、本发明的目的在于针对现有技术存在的缺陷和实际需求,提供一种面向恶意代码图像的可解释性评估方法,能够有效地识别恶意代码并提供其分类结果的可解释性评估,提高恶意代码检测的准确性和可解释性,有助于建立对深度学习技术的信任,使得安全研究人员很难根据训练结果有针对性地进行调优,能为实际网络环境中安全防护提供有力的技术支撑。
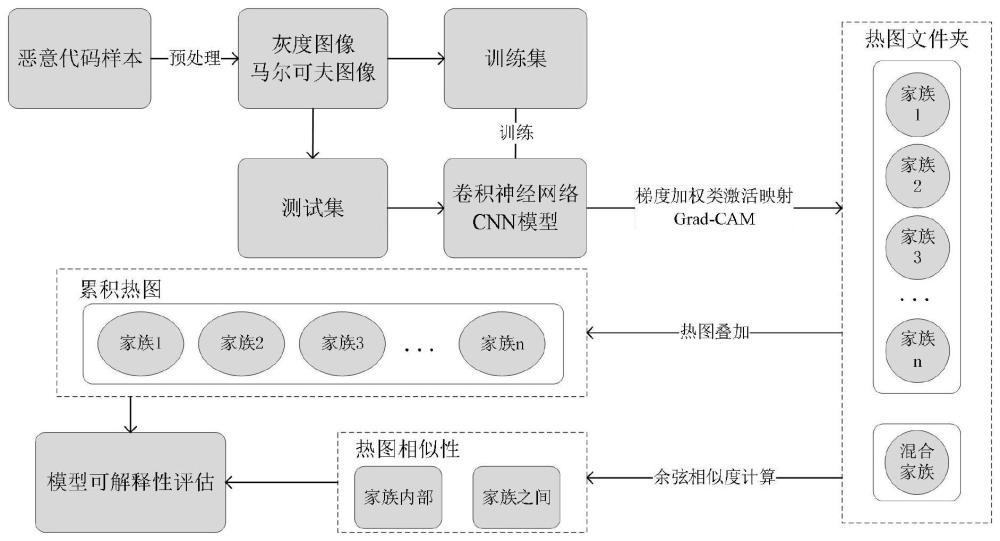
2、本发明方案旨在提高恶意代码检测的准确性和可解释性,有效地识别恶意代码并提供其分类结果的可解释性评估。首先,经过数据预处理生成恶意代码样本对应的灰度图像和马尔可夫图像。利用生成的恶意代码图像数据,构建基于卷积神经网络的恶意代码图像分类模型。然后,使用局部可解释性方法,获取特定恶意代码图像样本在模型决策过程中的关键特征,计算模型的梯度信息,根据模型预测结果对输入数据生成对应的热图,并叠加属于同一家族的热图,为每一个家族生成累积热图。最后,计算家族内部的平均热图相似性以及不同家族之间的平均热图相似性,以评估模型预测结果的合理性,了解模型是否正确地学习。
3、为实现上述目的,本发明的技术方案是:一种面向恶意代码图像的可解释性评估方法,包括如下步骤:
4、步骤s1、对恶意代码样本进行数据预处理,生成基于字节流的灰度图像和基于操作码的马尔可夫图像;
5、步骤s2、将预处理生成的恶意代码图像作为模型数据,构建卷积神经网络判别模型;
6、步骤s3、根据模型预测,基于梯度加权类激活映射方法grad-cam生成对应恶意代码图像热图;
7、步骤s4、基于相同家族的恶意代码图像热图,生成家族对应的累积热图;
8、步骤s5、对各个家族的热图文件夹和混合家族的热图文件夹分别进行热图相似性计算;
9、步骤s6、根据家族累积热图和热图相似性计算结果对模型进行可解释性评估。
10、在本发明一实施例中,步骤s1中,生成恶意代码样本基于字节流的灰度图像,具体包括以下步骤:
11、步骤s1a1、将恶意代码样本二进制字节流中的每8位二进制数据转化为0-255的十进制数值,生成十进制一维数组;
12、步骤s1a2、将读取的一维数组转化成固定列的二维数组;
13、步骤s1a3、将二维数组转化为灰度图像,并要对图像大小进行缩放处理,统一图像大小。
14、在本发明一实施例中,步骤s1中,生成恶意代码样本基于操作码的马尔可夫图像,具体包括以下步骤:
15、步骤s1b1、从恶意代码的反汇编asm文件中提取恶意代码操作码序列;
16、步骤s1b2、引入马尔可夫假设,计算操作码序列的马尔可夫转移概率矩阵tm;
17、步骤s1b3、根据计算马尔可夫转移概率矩阵,生成马尔可夫图像。
18、在本发明一实施例中,步骤s1b1中,从恶意代码的反汇编asm文件中提取恶意代码操作码序列,具体包括以下步骤:
19、步骤s1b11、将恶意代码样本进行反汇编操作,获取asm文件;
20、步骤s1b12、通过匹配segment type:pure code定位代码节位置,获取代码节名称;
21、步骤s1b13、根据得到的代码节名称匹配代码节区内容,按行读取代码节中的内容;
22、步骤s1b14、通过正则匹配,获取文件所包含的操作码,提取二进制文件的操作码序列;
23、步骤s1b15、选取出现次数较多的前255种操作码类型,将其余操作码类型统一为第256种操作码,并标记为0-255号,将提取的操作码序列转化为由十进制数0-255组成的一维数组。
24、在本发明一实施例中,步骤s1b3中,根据计算马尔可夫转移概率矩阵,生成马尔可夫图像,具体包括以下步骤:
25、步骤s1b31、获取马尔可夫转移概率矩阵中的最大值mp;
26、步骤s1b32、将马尔可夫转移概率矩阵中的概率值乘以255/mp,并进行模256计算;
27、步骤s1b33、将步骤s2b32计算后的数组转化为马尔可夫图像。
28、在本发明一实施例中,步骤s2中,将预处理生成的恶意代码图像作为模型数据,构建卷积神经网络判别模型,具体包括以下步骤:
29、步骤s21、使用生成的恶意代码图像样本构建数据集,划分为训练集和测试集;
30、步骤s22、构建面向恶意代码图像分类的卷积神经网络判别模型,并使用训练集对其进行训练。
31、在本发明一实施例中,步骤s3中,对于各个家族的热图文件夹根据模型预测,基于grad-cam生成对应恶意代码图像的热图,具体包括以下步骤:
32、步骤s31、将测试集数据输入卷积神经网络判别模型进行预测;
33、步骤s32、获取模型的最后一层卷积层;
34、步骤s33、获取模型输出层;
35、步骤s34、利用反向传播的梯度计算权重,生成对应的热图。
36、在本发明一实施例中,步骤s4中,根据各个家族的恶意代码样本热图生成对应的累积热图,具体包括以下步骤:
37、步骤s41、将生成的热图按照家族标签分类,为每个恶意代码家族构建一个热图文件夹;
38、步骤s42、将每个家族的累积热图为各通道像素均为0的图像;
39、步骤s43、家族对应的累积热图叠加上家族热图文件夹中的热图,并进行平均,得到最终的家族累积热图。
40、在本发明一实施例中,步骤s5中,对各个家族的热图文件夹和混合家族的热图文件夹分别进行热图相似性计算,具体包括以下步骤:
41、步骤s51、将生成的热图按照家族标签分类,为每个恶意代码家族构建一个热图文件夹;
42、步骤s52、取来自不同家族的恶意代码样本对应的热图构建一个混合家族的热图文件;
43、步骤s53、计算属于同一个热图文件夹中两两热图之间的余弦相似度;
44、步骤s54、对热图文件夹中所计算的热图相似性进行求和平均,获得各个家族平均热图相似性和混合家族平均热图相似性。
45、在本发明一实施例中,步骤s6中,根据家族累积热图和热图相似性计算结果对模型进行可解释性评估,具体包括以下步骤:
46、步骤s61、观察生成的各家族累积热图,当图像在位置分布上呈现规律时,根据累积热图显示模式能够对于模型是否正确地识别整个恶意代码家族的某点和特征进行判断;理论上,不应该存在两个相似或相等的累积热图,否则将意味着来自不同恶意软件家族的样本被错误地分类在同一类中;
47、步骤s62、对家族内部的平均热图相似性和不同家族之间的平均热图相似性进行对比,理论上,不同家族之间的平均热图相似性应小于家族内部的平均热图相似性。
48、本发明通过将恶意代码样本转化为基于字节流的灰度图像和基于操作码的马尔可夫图像,构建基于卷积神经网络的恶意代码图像分类模型,并实现面向恶意代码图像的可解释性评估,增强模型分类结果的可信度,有助于安全研究人员有针对性地对模型进行调优,提高恶意代码分类模型的准确性和可解释性。
49、相较于现有技术,本发明具有以下有益效果:本发明构造了一种恶意代码图像的可解释性评估方法。本发明的方法能够有效地识别恶意代码并提供其分类结果的可解释性评估,提高恶意代码检测的准确性和可解释性,有助于建立对深度学习技术的信任,使得安全研究人员很难根据训练结果有针对性地进行调优,能为实际网络环境中安全防护提供有力的技术支撑。
- 还没有人留言评论。精彩留言会获得点赞!