一种基于轨迹预测的智能体决策可解释性算法的制作方法
本申请属于机器学习算法领域,特别涉及一种基于轨迹预测的智能体决策可解释性算法。
背景技术:
1、人工智能是新一轮产业变革的核心驱动力,人工智能技术的飞速发展,特别是深度学习和强化学习技术的飞跃,使无人系统从感知到决策能力都有了大幅提升。深度学习解决的是感知问题,如图像识别和自然语言处理,强化学习解决的是决策问题,而人工智能的终极目的是通过感知进行智能决策。
2、强化学习是研究如何让智能体自主与环境交互、并从中学习最优决策的机器学习分支领域。近年来,强化学习已在许多场景中表现出超越人类专家的决策能力。由于深度学习和深度强化学习技术在感知和决策方面具有优秀表现,在军事应用上对该技术的使用也是令人期待。早在2018年,美国已经开始布局空中智能项目,他们提出ace项目将深度强化学习技术用在未来智能空中博弈中,该项目也是分步执行,从仿真模拟1v1近距空中博弈,到2v1验证局部协同技术,再到2v2验证多对多协同决策,最后到真机上进行实战部署。但是这个项目的最大目的,是让飞行员能够信任智能算法决策的能力,这就牵引出智能决策可解释和可信性问题。智能系统的可信验证与量化评估是一个系统性难题,首先要明确js智能系统的智能知识表征,确定智能感知认知智能决策的输出形式,根据输出形式研究先进的智能可信性、可解释性理论和方法。
3、虽然强化学习具有诸多优势,但其决策性能的好坏与环境状态特征表示的优劣有很大关系,因此如何实现环境状态特征表示就变得十分重要。如果环境中的连续状态表示可以有效地预测未来数个状态的特征表示,决策模型可以有效地进行相应的决策,上述预测结果也可以辅助解释决策模型的输出,给出决策的理由。
4、因此,希望有一种技术方案来克服或至少减轻现有技术的至少一个上述缺陷。
技术实现思路
1、本申请的目的是提供了一种基于轨迹预测的智能体决策可解释性算法,以解决现有技术存在的至少一个问题。
2、本申请的技术方案是:
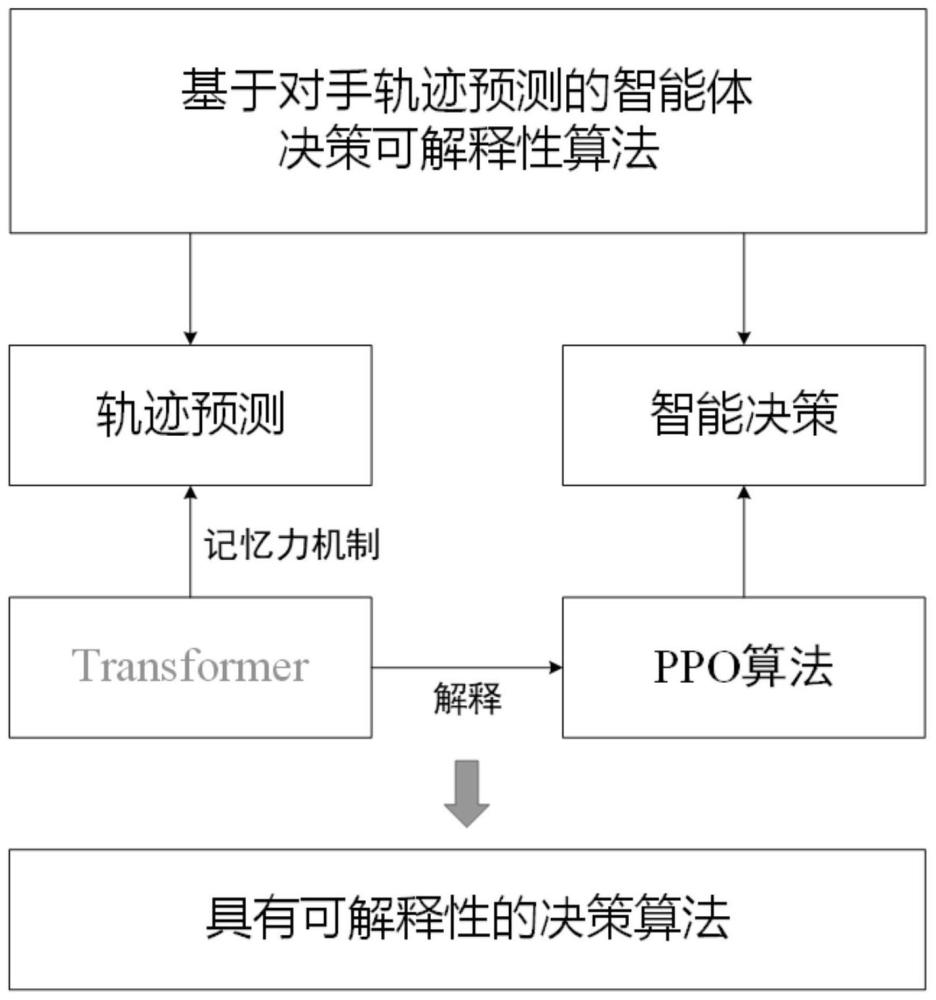
3、一种基于轨迹预测的智能体决策可解释性算法,包括:
4、步骤一、训练transformer模型,并通过训练好的所述transformer模型进行轨迹预测,得到运动轨迹;
5、步骤二、通过近端策略优化算法ppo对所述运动轨迹进行采样,并基于采样数据对智能体进行决策,得到具有可解释性的策略。
6、在本申请的至少一个实施例中,步骤一中,所述训练transformer模型,并通过训练好的所述transformer模型进行轨迹预测,得到运动轨迹,包括:
7、训练transformer模型;
8、通过训练好的所述transformer模型进行轨迹预测,得到运动轨迹;其中,通过训练好的所述transformer模型进行轨迹预测时,通过attention网络进行特征分析,基于长短时神经网络lstm叠加相同结构的网络模块实现数据的传递,使得网络参数能够表达具有时空域关联性的数据特征。
9、在本申请的至少一个实施例中,所述训练transformer模型,包括
10、将当前时刻的状态st以及前9个时刻的状态st-10~st-1作为transformer模型的输入,transformer模型的输出为后续5个时刻的状态st+1~st+5,通过已有的运动轨迹yt+1~yt+5作为监督信息对transformer模型进行大量训练,得到训练好的transformer模型。
11、在本申请的至少一个实施例中,在训练transformer模型时,评估模型预测结果和实际结果之间的差异的指标采用mse loss函数:
12、
13、其中,l为损失,yt+i为t+i时刻的运动轨迹,st+i为t+i时刻的状态。
14、在本申请的至少一个实施例中,所述attention网络为:
15、
16、其中,q为attention网络查询语句输入值,k为attention网络关键特征向量值,v为attention网络特征价值,n为特征向量维度。
17、在本申请的至少一个实施例中,所述长短时神经网络lstm的输入时刻所包含的信息由网络模块中各个门函数决定去留,所述门函数包括输入门函数、遗忘门函数以及输出门函数。
18、在本申请的至少一个实施例中,步骤二中,所述近端策略优化算法ppo采用ppoactor-critic架构,包括actor网络和critic网络。
19、在本申请的至少一个实施例中,所述近端策略优化算法ppo的采样函数为:
20、
21、
22、通过clipped方法将rt(θ)限制在预定范围内,在保守策略迭代算法中,损失函数为:
23、
24、其中,lcpi为经过clipped方法之后的损失函数,θ为神经网络参数,et指对时间t求期望,πθ指智能体当前的策略网络,πθold指智能体取得轨迹时所以的策略网络,at为时刻t下采取的动作,st为时刻t下智能体所处状态,at为智能体评估执行动作at的优势函数,rt为当前策略与轨迹策略之比,称为重要性权重系数。
25、发明至少存在以下有益技术效果:
26、本申请的基于轨迹预测的智能体决策可解释性算法,transformer模型具有很强的预测能力,利用近端策略优化算法ppo通过对手过往的运动轨迹中采样得到数据,对其未来的运动轨迹进行预测,根据预测结果可以做出相应的反馈动作,该预测解释了智能体决策的理由,因此智能体生成的策略具有可解释性。
技术特征:
1.一种基于轨迹预测的智能体决策可解释性算法,其特征在于,包括:
2.根据权利要求1所述的基于轨迹预测的智能体决策可解释性算法,其特征在于,步骤一中,所述训练transformer模型,并通过训练好的所述transformer模型进行轨迹预测,得到运动轨迹,包括:
3.根据权利要求2所述的基于轨迹预测的智能体决策可解释性算法,其特征在于,所述训练transformer模型,包括
4.根据权利要求3所述的基于轨迹预测的智能体决策可解释性算法,其特征在于,在训练transformer模型时,评估模型预测结果和实际结果之间的差异的指标采用mseloss函数:
5.根据权利要求2所述的基于轨迹预测的智能体决策可解释性算法,其特征在于,所述attention网络为:
6.根据权利要求5所述的基于轨迹预测的智能体决策可解释性算法,其特征在于,所述长短时神经网络lstm的输入时刻所包含的信息由网络模块中各个门函数决定去留,所述门函数包括输入门函数、遗忘门函数以及输出门函数。
7.根据权利要求1所述的基于轨迹预测的智能体决策可解释性算法,其特征在于,步骤二中,所述近端策略优化算法ppo采用ppoactor-critic架构,包括actor网络和critic网络。
8.根据权利要求7所述的基于轨迹预测的智能体决策可解释性算法,其特征在于,所述近端策略优化算法ppo的采样函数为:
技术总结
本申请属于机器学习算法领域,特别涉及一种基于轨迹预测的智能体决策可解释性算法。包括步骤一、训练Transformer模型,并通过训练好的所述Transformer模型进行轨迹预测,得到运动轨迹;步骤二、通过近端策略优化算法PPO对所述运动轨迹进行采样,并基于采样数据对智能体进行决策,得到具有可解释性的策略。本申请的基于轨迹预测的智能体决策可解释性算法,Transformer模型具有很强的预测能力,利用近端策略优化算法PPO通过对手过往的运动轨迹中采样得到数据,对其未来的运动轨迹进行预测,根据预测结果可以做出相应的反馈动作,该预测解释了智能体决策的理由,因此智能体生成的策略具有可解释性。
技术研发人员:徐芳芳,闫传博,费思邈,管聪,刘仲,朴海音,孙阳,王鹤,孙智孝
受保护的技术使用者:中国航空工业集团公司沈阳飞机设计研究所
技术研发日:
技术公布日:2024/1/5
- 还没有人留言评论。精彩留言会获得点赞!