一种文字驱动数字人生成视频的方法和装置与流程
本申请涉及视频创建领域,尤其涉及一种文字驱动数字人生成视频的方法和装置。
背景技术:
1、自动化视频生成可以加快新闻播报、教学教材等业务流程,提高生产效率,让内容创作和传播更加迅速。数字人生成视频的方法可以满足用户在不同领域中对于个性化、有针对性的内容传达需求,提供更具吸引力和定制化的信息呈现。
2、但是目前还没有基于文本内容直接驱动数字人生成视频的方法。
技术实现思路
1、本申请的目的在于克服现有技术中存在的问题,提供一种文字驱动数字人生成视频的方法和装置。
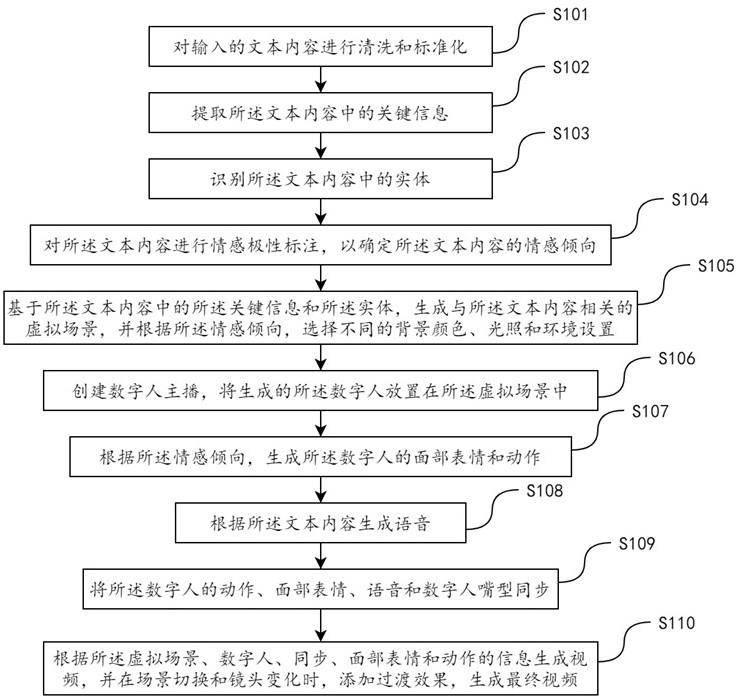
2、本申请提供一种文字驱动数字人生成视频的方法,包括:
3、对输入的文本内容进行清洗和标准化;
4、提取所述文本内容中的关键信息;
5、识别所述文本内容中的实体;
6、对所述文本内容进行情感极性标注,以确定所述文本内容的情感倾向;
7、基于所述文本内容中的所述关键信息和所述实体,生成与所述文本内容相关的虚拟场景,并根据所述情感倾向,选择不同的背景颜色、光照和环境设置;
8、创建数字人主播,将生成的所述数字人放置在所述虚拟场景中;
9、根据所述情感倾向,生成所述数字人的面部表情和动作;
10、根据所述文本内容生成语音;
11、将所述数字人的动作、面部表情、语音和数字人嘴型同步;
12、根据所述虚拟场景、数字人、同步、面部表情和动作的信息生成视频,并在场景切换和镜头变化时,添加过渡效果,生成最终视频。
13、可选地,所述将所述数字人的动作、面部表情、语音和数字人嘴型同步,包括:
14、根据所述文本内容,使用时间轴和动画曲线来同步数字人的动作、面部表情、语音和数字人嘴型。
15、可选地,所述情感倾向包括:正面、负面或者中立。
16、可选地,还包括:
17、当所述文本内容为正面时,显示高兴的面部表情和动作;
18、当所述文本内容为负面时,显示悲伤或愤怒的面部表情和动作。
19、可选地,所述过渡效果包括:淡入淡出、旋转和平移。
20、本申请提供一种文字驱动数字人生成视频的装置,包括:
21、预处理模块,用于对输入的文本内容进行清洗和标准化;
22、提取模块,用于提取所述文本内容中的关键信息;
23、识别模块,用于识别所述文本内容中的实体;
24、标注模块,用于对所述文本内容进行情感极性标注,以确定所述文本内容的情感倾向;
25、场景模块,用于基于所述文本内容中的所述关键信息和所述实体,生成与所述文本内容相关的虚拟场景,并根据所述情感倾向,选择不同的背景颜色、光照和环境设置;
26、创建模块,用于创建数字人主播,将生成的所述数字人放置在所述虚拟场景中;
27、表现模块,用于根据所述情感倾向,生成所述数字人的面部表情和动作;
28、语音模块,用于根据所述文本内容生成语音;
29、同步模块,用于将所述数字人的动作、面部表情、语音和数字人嘴型同步;
30、视频模块,用于根据所述虚拟场景、数字人、同步、面部表情和动作的信息生成视频,并在场景切换和镜头变化时,添加过渡效果,生成最终视频。
31、可选地,所述同步模块将所述数字人的动作、面部表情、语音和数字人嘴型同步,包括:
32、根据所述文本内容,使用时间轴和动画曲线来同步数字人的动作、面部表情、语音和数字人嘴型。
33、可选地,所述情感倾向包括:正面、负面或者中立。
34、可选地,还包括:
35、当所述文本内容为正面时,显示高兴的面部表情和动作;
36、当所述文本内容为负面时,显示悲伤或愤怒的面部表情和动作。
37、可选地,所述过渡效果包括:淡入淡出、旋转和平移。
38、本申请的优点和有益效果:
39、本申请提供一种文字驱动数字人生成视频的方法,包括:对输入的文本内容进行清洗和标准化;提取所述文本内容中的关键信息;识别所述文本内容中的实体;对所述文本内容进行情感极性标注,以确定所述文本内容的情感倾向;基于所述文本内容中的所述关键信息和所述实体,生成与所述文本内容相关的虚拟场景,并根据所述情感倾向,选择不同的背景颜色、光照和环境设置;创建数字人主播,将生成的所述数字人放置在所述虚拟场景中;根据所述情感倾向,生成所述数字人的面部表情和动作;根据所述文本内容生成语音;将所述数字人的动作、面部表情、语音和数字人嘴型同步;根据所述虚拟场景、数字人、同步、面部表情和动作的信息生成视频,并在场景切换和镜头变化时,添加过渡效果,生成最终视频。本申请基于文字内容直接驱动数字人生成视频,提高了视频生成效率。
技术特征:
1.一种文字驱动数字人生成视频的方法,其特征在于,包括:
2.根据权利要求1所述文字驱动数字人生成视频的方法,其特征在于,所述将所述数字人的动作、面部表情、语音和数字人嘴型同步,包括:
3.根据权利要求1所述文字驱动数字人生成视频的方法,其特征在于,所述情感倾向包括:正面、负面或者中立。
4.根据权利要求3所述文字驱动数字人生成视频的方法,其特征在于,还包括:
5.根据权利要求1所述文字驱动数字人生成视频的方法,其特征在于,所述过渡效果包括:淡入淡出、旋转和平移。
6.一种文字驱动数字人生成视频的装置,其特征在于,包括:
7.根据权利要求6所述文字驱动数字人生成视频的装置,其特征在于,所述同步模块将所述数字人的动作、面部表情、语音和数字人嘴型同步,包括:
8.根据权利要求6所述文字驱动数字人生成视频的装置,其特征在于,所述情感倾向包括:正面、负面或者中立。
9.根据权利要求8所述文字驱动数字人生成视频的装置,其特征在于,还包括:
10.根据权利要求6所述文字驱动数字人生成视频的装置,其特征在于,所述过渡效果包括:淡入淡出、旋转和平移。
技术总结
本申请提供一种文字驱动数字人生成视频的方法及装置,包括:对输入的文本内容进行清洗和标准化,对文本内容提取关键信息、识别实体;对进行情感极性标注以确定情感倾向;基于关键信息和实体,生成与文本内容相关的虚拟场景,并根据情感倾向,选择不同的背景颜色、光照和环境设置;创建数字人主播,将生成的数字人放置在虚拟场景中;根据情感倾向,生成数字人的面部表情和动作;根据文本内容生成语音;将数字人的动作、面部表情、语音和数字人嘴型同步;根据虚拟场景、数字人、同步、面部表情和动作的信息生成视频,并在场景切换和镜头变化时,添加过渡效果,生成最终视频。本申请基于文字内容直接驱动数字人生成视频,提高了视频生成效率。
技术研发人员:胡兴凯,郑航,费元华,郭建君
受保护的技术使用者:北京蔚领时代科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!