一种基于非译预处理的翻译方法与流程
本发明涉及文本标注领域,具体来说,涉及一种基于非译预处理的翻译方法。
背景技术:
1、随着全球化的发展和互联网技术的普及,跨语言信息传输变得愈发重要。机器翻译作为一种能够帮助人们快速理解和传播不同语言内容的工具,在各个领域都具有广泛应用价值。然而,现有的机器翻译系统尽管在一定程度上提高了翻译速度,但在译文质量方面仍存在诸多问题。这些问题包括翻译不准确、语义理解不足、词汇搭配不符合目标语言习惯等。
2、针对这一挑战,许多研究者专注于改进翻译引擎的性能,其中非译处理技术逐渐受到关注。非译处理(pre-editing)是指在机器翻译过程之前对源文本进行优化处理,以便让机器翻译引擎更容易地理解和翻译。通过对源文本进行预处理,可以消除歧义、简化复杂结构、统一术语表达等,从而提高机翻速度和译文质量。
3、然而,现有的基于非译处理的方法往往局限于针对特定语言对或领域的优化,并且可能需要大量的人工参与。因此,亟待需要一种非译处理方法对不同语言和领域文本的智能预处理,进而为用户提供更高效、质量更好的机器翻译服务。
技术实现思路
1、本发明提供一种基于非译预处理的翻译方法,简单便捷,能够对不同语言和领域文本中非译内容进行预处理,进而后续为用户提供更高效、质量更好的机器翻译服务。
2、本发明所采取的技术方案是:
3、一种基于非译预处理的翻译方法,包括以下步骤:
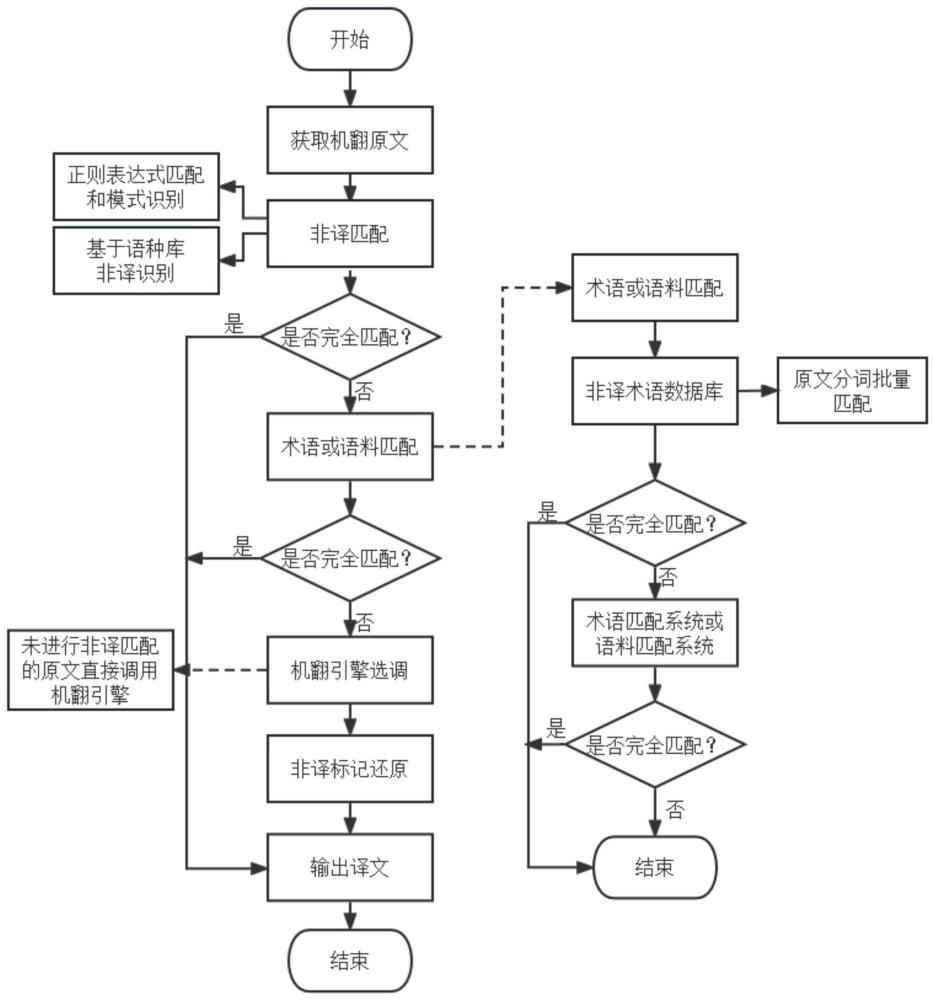
4、s1、机翻开始,获取机翻的原文并使用变量src存储得到原文a;
5、s2、对原文a进行非译匹配;
6、s3、判断所述原文a非译匹配是否完全匹配:
7、若完全匹配,则完成翻译,得到第一译文并将其作为目标译文输出;
8、否则,对所述原文a中部分非译匹配的内容进行非译标签标记作为原文b,并进入下一步骤;
9、s4、基于语料库或术语库对所述原文b进行非译匹配;
10、s5、判断所述原文b非译匹配是否完全匹配:
11、若完全匹配,则完成翻译,得到第二译文并将其作为目标译文输出;
12、否则,对所述原文b中部分匹配的内容进行非译标签标记作为原文c,并进入下一步骤;
13、s6、选调机翻引擎对所述原文c进行翻译得到第三译文;
14、s7、将所述原文c中的非译标签标记还原其对应的内容得到第四译文;
15、s8、将第四译文作为目标译文输出,机翻结束。
16、进一步地,所述s2中对原文a进行非译匹配,包括以下步骤:
17、1)基于规则匹配和模式识别对原文a进行非译匹配;
18、2)基于语种库及开源框架langid对原文a进行语种的非译识别匹配。
19、进一步地,所述规则匹配包括正则表达式匹配,其对原文中的标点符号、纯数字、单个字母、单个字母及数字、uuid、邮箱地址和网站地址中的一个或多个进行非译匹配。
20、进一步地,所述s4中的基于语料库对原文b进行非译匹配,包括以下步骤:
21、1)优化原文b:去除所述原文b中的标点符号、多余空格及大小写转换;
22、2)基于语料库通过simhash算法进行语料匹配。
23、进一步地,所述s4中的基于术语库对原文b进行非译匹配,包括以下步骤:
24、基于术语库对原文b进行等值匹配查询:
25、若存在,则完成翻译,输出得到第二译文,其中第二译文为术语库中等值匹配查询得到的匹配译文;
26、否则,进入下一步骤。
27、进一步地,所述s4中的基于术语库对原文b进行非译匹配,包括以下步骤:
28、1)对原文b进行结巴分词得到原文b1;
29、2)基于术语库中非译模块对分词后的原文b1进行等值匹配查询:
30、若完全匹配,则完成翻译并输出得到拼接译文,其中拼接译文为所有分词在非译术语库匹配查询得到的对应匹配译文;
31、否则,则在原文b1中对有术语的内容进行非译标签标记作为原文b2:使用非译标签span进行标记,属性id为数字,存储非译标签对应的译文内容设置为span-id-t,其中,属性id随着术语数量的增加而递增;t为原文b2;
32、3)基于术语库中匹配模块对原文b及原文b2进行术语匹配:
33、若完全匹配,则完成翻译,得到第二译文并将其作为目标译文输出;
34、否则,对原文b2标记出匹配的术语并输出得到原文b3:使用非译标签span进行标记,术语name为数字,存储非译标签对应的译文内容设置为span-name-t,其中,术语named随着术语数量的增加而递增;t为原文b3;
35、进一步地,所述匹配模块采用双数组字典树数据结构,确保匹配的术语高效正确。
36、进一步地,所述s7和s8中,包括以下步骤:
37、对所述第三译文进行解析,并采用html还原非译标签,根据非译标签的属性值找到非译标签对应的译文内容进行替换,最终得到第四译文作为目标译文输出。
38、本发明与现有技术相比具有以下有益效果:
39、1)通过对源文本进行预处理,消除歧义、简化复杂结构及统一术语表达,有利于生成更准确、自然且符合目标语言表达习惯的译文;
40、2)非译处理在预处理阶段对源文本进行优化,简化语言结构和格式,从而加快机器翻译引擎的处理速度;
41、3)本发明可针对特定领域和应用场景进行调整和优化,提高机器翻译在各个领域中的实用性;
42、4)通过提高机器翻译的初步质量,可以减少后期人工校对和润色的时间与成本,提高整体翻译效率;
43、5)优化后的机器翻译系统能够更好地满足用户跨语言沟通的需求,促进全球范围内的信息传播与交流;
44、6)本发明为更高级别的自然语言处理技术奠定基础。
技术特征:
1.一种基于非译预处理的翻译方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于非译预处理的翻译方法,其特征在于,所述s2中对原文a进行非译匹配,包括以下步骤:
3.根据权利要求2所述的一种基于非译预处理的翻译方法,其特征在于,所述规则匹配包括正则表达式匹配,其对原文中的标点符号、纯数字、单个字母、单个字母及数字、uuid、邮箱地址和网站地址中的一个或多个进行非译匹配。
4.根据权利要求1所述的一种基于非译预处理的翻译方法,其特征在于,所述s4中的基于语料库对原文b进行非译匹配,包括以下步骤:
5.根据权利要求1所述的一种基于非译预处理的翻译方法,其特征在于,所述s4中的基于术语库对原文b进行非译匹配,包括以下步骤:
6.根据权利要求1所述的一种基于非译预处理的翻译方法,其特征在于,所述s4中的基于术语库对原文b进行非译匹配,包括以下步骤:
7.根据权利要求6所述的一种基于非译预处理的翻译方法,其特征在于,所述匹配模块采用双数组字典树数据结构,确保匹配的术语高效正确。
8.根据权利要求1所述的一种基于非译预处理的翻译方法,其特征在于,所述s7和s8中,包括以下步骤:
技术总结
本发明公开了一种基于非译预处理的翻译方法,包括以下步骤:获取机翻的原文并使用变量SRC存储得到原文A;对原文A进行非译匹配;判断所述原文A非译匹配是否完全匹配;基于语料库或术语库对所述原文B进行非译匹配;判断所述原文B非译匹配是否完全匹配;选调机翻引擎对所述原文C进行翻译得到第三译文;将所述原文C中的非译标签标记还原其对应的内容得到第四译文;将第四译文作为目标译文输出。本发明通过对源文本进行预处理,消除歧义、简化复杂结构及统一术语表达,有利于生成更准确、自然且符合目标语言表达习惯的译文;非译处理在预处理阶段对源文本进行优化,简化语言结构和格式,从而加快机器翻译引擎的处理速度。
技术研发人员:李超雄,张云君
受保护的技术使用者:语联网(武汉)信息技术有限公司
技术研发日:
技术公布日:2024/2/8
- 还没有人留言评论。精彩留言会获得点赞!