一种直播自主互动方法、设备及计算机可读介质与流程
本申请涉及直播,尤其涉及一种直播自主互动方法、设备及计算机可读介质。
背景技术:
1、本部分旨在为权利要求书中陈述的本申请的实施方式提供背景或上下文。此处的描述不因为包括在本部分中就被认为是现有技术。
2、随着人工智能技术的发展,其应用的领域也越来越广泛,在直播平台中采用利用人工智能训练的虚拟主播进行直播的场景越来越广泛,采用虚拟主播进行直播不但节省人力成本,而且更具有趣味性及可控性。
3、但目前的虚拟直播技术仍存在一些不足,例如,虚拟主播与观看直播的用户以及与其他连线的主播之间无法互动,导致用户无法参与到直播互动中,直播过程中用户的问题无法及时得到反馈,从而导致直播效果差,用户体验差等问题。
技术实现思路
1、本申请的多个方面提供一种直播自主互动方法、设备及计算机可读存储介质,用以解决目前虚拟直播无法互动的问题。
2、本申请的一方面,提供一种直播自主互动方法,所述方法应用于虚拟主播直播场景,所述方法包括:
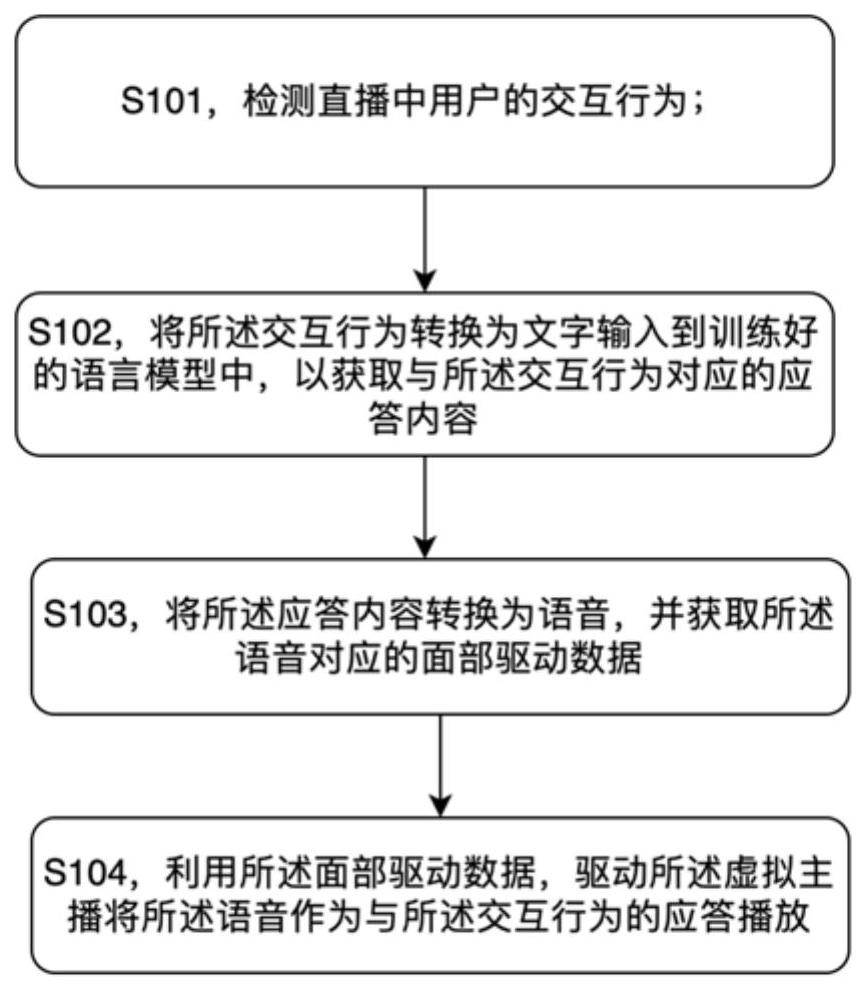
3、检测直播中用户的交互行为;
4、将所述交互行为转换为文字输入到训练好的语言模型中,以获取与所述交互行为对应的应答内容;所述语言模型为利用与所述虚拟主播预定人设相符的行为习惯数据训练的模型;
5、将所述应答内容转换为语音,并获取所述语音对应的面部驱动数据,其中,所述语音的音色与所述虚拟主播预定人设相符;所述面部驱动数据包括口型驱动数据;
6、利用所述面部驱动数据,驱动所述虚拟主播将所述语音作为与所述交互行为的应答播放。
7、可选的,所述将所述交互行为转换为文字的步骤包括:按照如下规则将所述交互行为转换为文字
8、针对第一类交互行为:直接获取所述第一类交互行为的文字,作为所述交互行为转换后的文字;
9、针对第二类交互行为:利用如下规则将所述交互行为转换为文字
10、[用户名]+<交互行为名称>;
11、针对第三类交互行为:利用如下规则将所述交互行为转换为文字
12、[用户名]+<交互行为名称>+{交互行为内容}。
13、可选的,将所述交互行为转换为文字输入到训练好的语言模型中的步骤包括:
14、根据预设的不同交互行为的应答优先级及所述交互行为发生的时间先后顺序,确定不同交互行为的应答顺序;
15、按照所确定的应答顺序将所述交互行为转换为文字输入到训练好的语言模型中。
16、可选的,所述面部驱动数据还包括:表情驱动和/或动作驱动数据,所述获取所述语音对应的面部驱动数据的步骤包括:
17、为所述语音适配与所述虚拟主播预定人设相符的表情和/或动作;
18、所述利用所述面部驱动数据,驱动所述虚拟主播将所述语音作为与所述交互行为的应答播放的步骤包括:
19、利用所述面部驱动数据,驱动所述虚拟主播以所述适配的表情和/或动作将所述语音作为所述虚拟主播与所述交互行为的应答进行播放。
20、可选的,所述为所述语音适配与所述虚拟主播预订人设相符的表情和/或动作的步骤包括:
21、将所述语音与预设的多个表情驱动数据和/或动作驱动数据进行匹配,获得对应表情驱动数据和/或动作驱动数据。
22、可选的,所述利用所述面部驱动数据,驱动所述虚拟主播以所述适配的表情和/或动作将所述语音作为所述虚拟主播与所述交互行为的应答进行播放的步骤包括:
23、控制所述表情和/或动作的驱动帧率与语音播放帧率对齐。
24、可选的,所述交互行为包括但不限于:
25、发送礼物,发送弹幕,发送留言,点赞,点歌,进入直播间,点关注,直播间特权触发指令,和/或连线的其他主播的音频。
26、本申请的另一方面,提供一种直播自主互动设备,所述装置应用于虚拟主播直播场景,所述设备包括:
27、第一单元,用于检测直播中用户的交互行为;
28、第二单元,用于将所述交互行为转换为文字输入到训练好的语言模型中,以获取与所述交互行为对应的应答内容;所述语言模型为利用与所述虚拟主播预定人设相符的行为习惯数据训练的模型;
29、第三单元,用于将所述应答内容转换为语音,并获取所述语音对应的面部驱动数据,其中,所述语音的音色与所述虚拟主播预定人设相符;所述面部驱动数据包括口型驱动数据;
30、第四单元,用于利用所述面部驱动数据,驱动所述虚拟主播将所述语音作为与所述交互行为的应答播放。
31、本申请的另一方面,提供一种电子设备,所述设备包括:
32、至少一个处理器;以及
33、与所述至少一个处理器通信连接的存储器;其中,
34、所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如上所述图像识别的方法。
35、本申请的另一方面,提供一种计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令可被处理器执行以实现所述图像识别方法。
36、本申请实施例提供的方案中,可以自动检测直播间的交互行为,并将其转换为文字输入到语言模型中以获得与虚拟主播人设相符的应答,并将应答转换为语音及面部驱动数据,以驱动虚拟主播播放所述应答,整个过程无需人为参与,自动检测,自动获取应答,自动播放应答,有效增强虚拟直播场景的互动性,及时响应用户需求及解决用户问题,使得虚拟直播更加生动,提升了用户观看直播的体验。
技术特征:
1.一种直播自主互动方法,其中,所述方法应用于虚拟主播直播场景,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述将所述交互行为转换为文字的步骤包括:按照如下规则将所述交互行为转换为文字
3.根据权利要求1所述的方法,其中,将所述交互行为转换为文字输入到训练好的语言模型中的步骤包括:
4.根据权利要求1所述的方法,其中,所述面部驱动数据还包括:表情驱动和/或动作驱动数据,所述获取所述语音对应的面部驱动数据的步骤包括:
5.根据权利要求4所述的方法,其中,所述为所述语音适配与所述虚拟主播预订人设相符的表情和/或动作的步骤包括:
6.根据权利要求4所述的方法,其中,所述利用所述面部驱动数据,驱动所述虚拟主播以所述适配的表情和/或动作将所述语音作为所述虚拟主播与所述交互行为的应答进行播放的步骤包括:
7.根据权利要求1所述的方法,其中,所述交互行为包括但不限于:
8.一种直播自主互动设备,其中,所述装置应用于虚拟主播直播场景,所述设备包括:
9.一种电子设备,所述电子设备包括:
10.一种计算机可读介质,其上存储有计算机程序指令,所述计算机程序指令可被处理器执行以实现如权利要求1至7中任一项所述的方法。
技术总结
本申请提供直播领域一种直播自主互动方法、设备及计算机可读介质,所述方法包括:检测直播中用户的交互行为;将所述交互行为转换为文字输入到训练好的语言模型中,以获取与所述交互行为对应的应答内容;将所述应答内容转换为语音,并获取所述语音对应的面部驱动数据;利用所述面部驱动数据,驱动所述虚拟主播将所述语音作为与所述交互行为的应答播放。本申请实现了虚拟直播场景下虚拟主播与用户的自主互动。
技术研发人员:章怀宙,褚波,朱爰润,张伟杰,万敏华,杨帆
受保护的技术使用者:上海哔哩哔哩科技有限公司
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!