音频的处理方法及装置、设备、存储介质与流程
本申请实施例涉及计算机,涉及但不限于一种音频的处理方法及装置、设备、存储介质。
背景技术:
1、随着计算机技术的发展,终端设备的使用越来越广泛。目前,终端设备中应用程序(application,app)的音频场景越来越丰富,有些场景为了吸引用户的注意力,会突然发出特异的声音,但有时也会对用户带来惊吓。示例性地,用户在观看直播的时候,很难预料下一秒会听到主播说出什么内容,有可能突然说一些不文明的话语,或者不正当的言论等。
2、在目前相关技术中,对于终端设备输出的音频,也有一些语音识别的方法、对音频中部分词语进行过滤替换的方法,但是目前相关技术中的音频过滤方法不够智能化,也不能识别一些用户不想过滤的音频场景,不能很好的满足用户需求。
3、因此,如何准确识别用户想要过滤的音频场景并实现过滤,是一个亟待解决的问题。
技术实现思路
1、有鉴于此,本申请实施例提供的音频的处理方法及装置、设备、存储介质,可以准确识别用户想要过滤的音频场景并实现过滤,以避免用户被终端设备的音频噪声攻击。本申请实施例提供的音频的处理方法及装置、设备、存储介质是这样实现的:
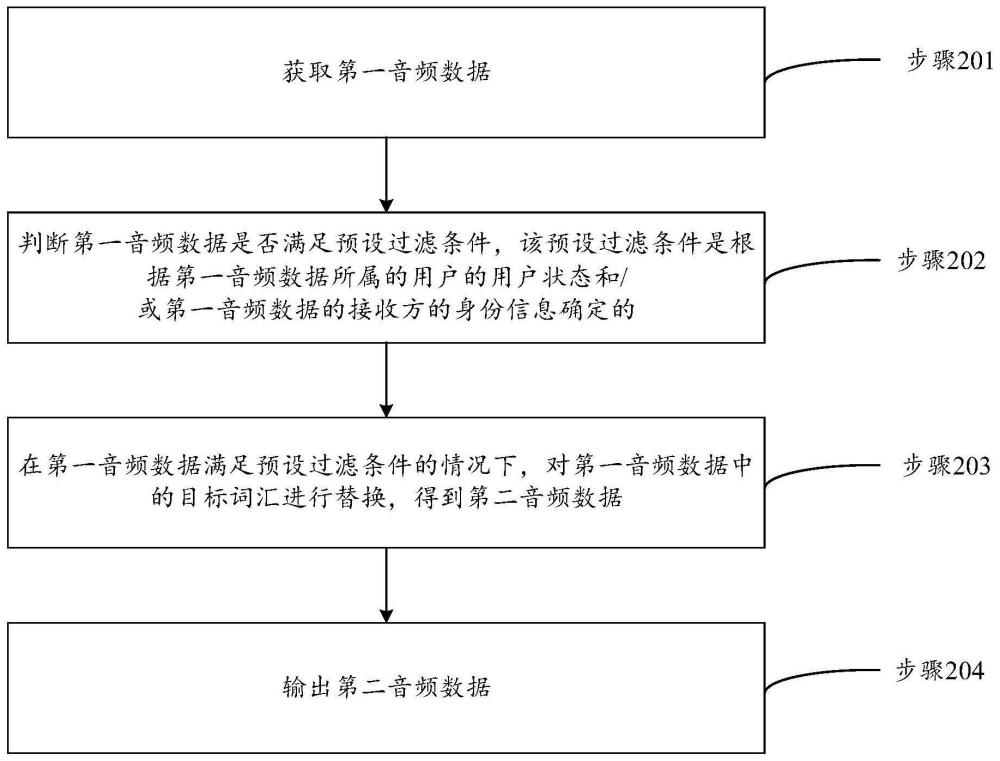
2、本申请实施例提供的音频的处理方法,包括:获取第一音频数据;判断所述第一音频数据是否满足预设过滤条件,所述预设过滤条件是根据所述第一音频数据所属的用户的用户状态和/或所述第一音频数据的接收方的身份信息确定的;在所述第一音频数据满足预设过滤条件的情况下,对所述第一音频数据中的目标词汇进行替换,得到第二音频数据;输出所述第二音频数据。
3、本申请实施例提供的音频的处理装置,包括:获取模块,用于获取第一音频数据;判断模块,用于判断所述第一音频数据是否满足预设过滤条件,所述预设过滤条件是根据所述第一音频数据所属的用户的用户状态和/或所述第一音频数据的接收方的身份信息确定的;替换模块,用于在所述第一音频数据满足预设过滤条件的情况下,对所述第一音频数据中的目标词汇进行替换,得到第二音频数据;输出模块,用于输出所述第二音频数据。
4、本申请实施例提供的计算机设备,包括存储器和处理器,所述存储器存储有可在处理器上运行的计算机程序,所述处理器执行所述程序时实现本申请实施例所述的音频的处理方法。
5、本申请实施例提供的计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现本申请实施例提供的所述的音频的处理方法。
6、本申请实施例所提供的音频的处理方法、装置、计算机设备和计算机可读存储介质中,终端设备在判断第一音频数据满足预设过滤条件的情况下,对第一音频数据中的目标词汇进行替换,得到并输出第二音频数据,该方法可以准确识别用户想要过滤的音频场景并实现过滤,以避免用户被终端设备的音频噪声攻击,解决背景技术中所提出的技术问题。
技术特征:
1.一种音频的处理方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述用户状态包括所述第一音频所属的用户的情绪状态,所述预设过滤条件包括预设情绪状态,所述判断所述第一音频数据是否满足预设过滤条件,包括:
3.根据权利要求1所述的方法,其特征在于,所述身份信息包括所述第一音频数据所属的用户与所述接收方之间的亲密关系,所述预设过滤条件包括预设亲密关系,所述判断所述第一音频数据是否满足预设过滤条件,包括:
4.根据权利要求3所述的方法,其特征在于,所述第一音频数据所属的用户与所述接收方之间的亲密关系是通过所述第一音频数据所属的用户与所述接收方之间的交互频率信息确定的。
5.根据权利要求1所述的方法,其特征在于,所述身份信息包括所述接收方的年龄,所述预设过滤条件包括预设年龄阈值,所述判断所述第一音频数据是否满足预设过滤条件,包括:
6.根据权利要求1所述的方法,其特征在于,所述对所述第一音频数据中的目标词汇进行替换,得到第二音频数据,包括:
7.根据权利要求1所述的方法,其特征在于,所述第一音频数据是通过多媒体框架对输入的原始音频数据进行解析得到的。
8.根据权利要求1所述的方法,其特征在于,所述输出所述第二音频数据,包括:
9.根据权利要求1所述的方法,其特征在于,终端设备中还设置有过滤开关单元,在所述判断所述第一音频数据是否满足预设过滤条件之前,所述方法还包括:
10.根据权利要求8所述的方法,其特征在于,所述方法还包括:
11.一种音频的处理装置,其特征在于,包括:
12.一种计算机设备,包括存储器和处理器,所述存储器存储有可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现权利要求1至10任一项所述方法的步骤。
13.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现如权利要求1至10任一项所述的方法。
技术总结
本申请实施例公开了一种音频的处理方法及装置、设备、存储介质。本申请的技术方案中,终端设备首先获取第一音频数据,然后判断第一音频数据是否满足预设过滤条件,该预设过滤条件是根据第一音频数据所属的用户的用户状态和/或第一音频数据的接收方的身份信息确定的;在第一音频数据满足预设过滤条件的情况下,对第一音频数据中的目标词汇进行替换,得到第二音频数据,最后输出第二音频数据。本申请的音频的处理方法中,终端设备在判断第一音频数据满足预设过滤条件的情况下,对第一音频数据中的目标词汇进行替换,得到并输出第二音频数据,该方法可以准确识别用户想要过滤的音频场景并实现过滤,以避免用户被终端设备的音频噪声攻击。
技术研发人员:李擎宇,杨卉年
受保护的技术使用者:OPPO广东移动通信有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!