大模型结合双路记忆的多模态有害社交媒体内容识别方法
本发明涉及社交媒体内容识别,具体涉及一种大模型结合双路记忆的多模态有害社交媒体内容识别方法。
背景技术:
1、在社交媒体中存在大量多模态信息(例如表情包等内容),这些信息中可能包含有害信息(例如表情包及其配套文字中包括有害信息),对这些信息的识别需要对图像及文本进行有效的处理及组合。
2、现有技术没有利用大语言模型的文本建模能力,同时现有的跨模态信息组合方法使用串联多模态特征或者计算多模态特征的外积,实现多模态信息组合,不足以满足任务对多模态信息共同理解的需求。
技术实现思路
1、为解决上述技术问题,本发明提供一种大模型结合双路记忆的多模态有害社交媒体内容识别方法。本发明利用提出的双通道记忆网络,在记忆语义空间内实现多模态信息的有效对齐,并利用大模型的语言建模能力提升多模态有害内容的识别性能。
2、为解决上述技术问题,本发明采用如下技术方案:
3、一种大模型结合双路记忆的多模态有害社交媒体内容识别方法,输入给定的图像和文本,输出用于判断多模态输入是否有害的标签,具体包括:
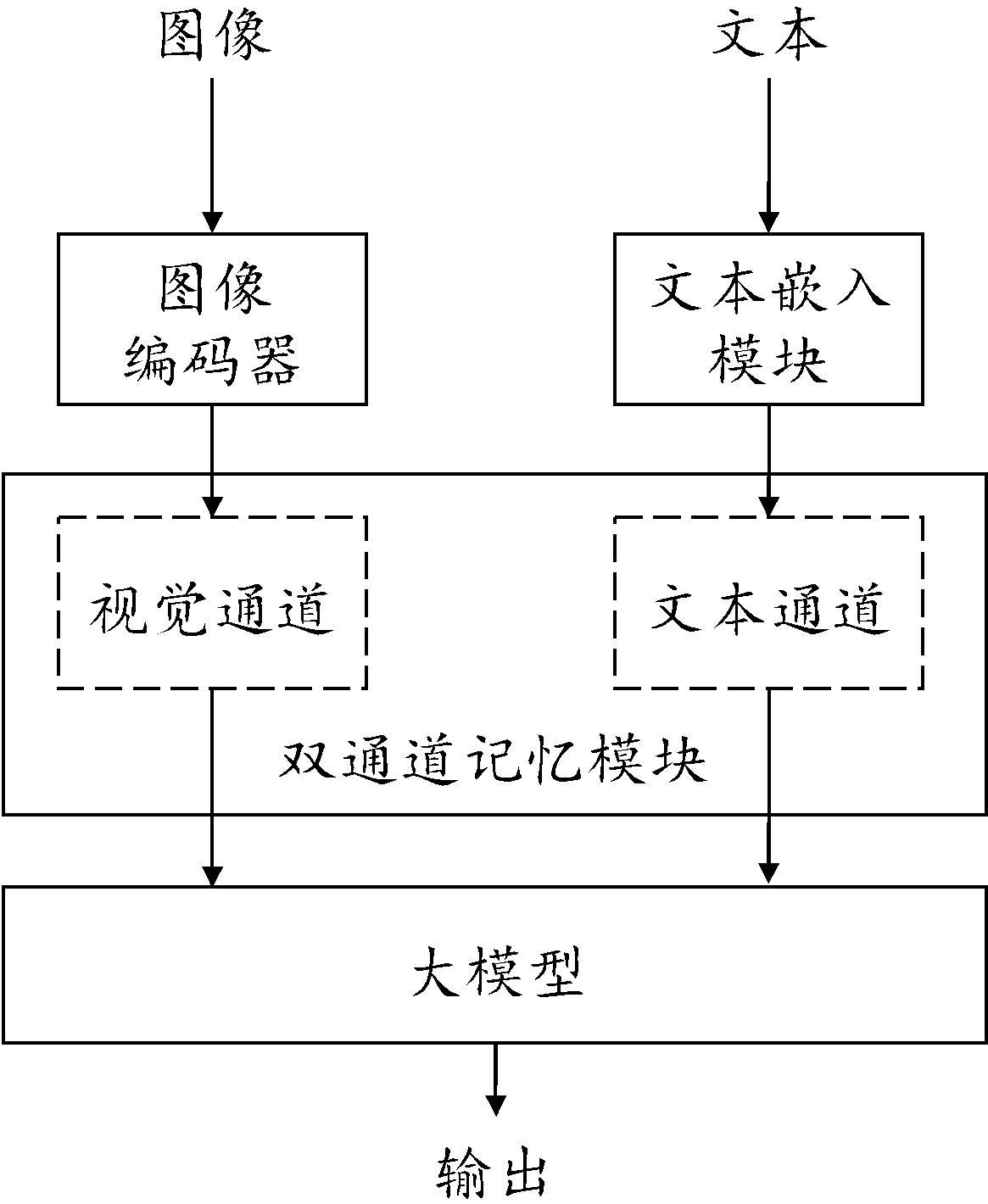
4、步骤一:利用图像编码器提取图像的图像特征;
5、步骤二:利用文本嵌入模块,提取文本的文本特征;
6、步骤三:应用双通道记忆模块对图像特征以及文本特征建模,分别得到图像向量以及文本向量;其中,双通道记忆模块包括n个记忆向量,以及视觉通道和文本通道;视觉通道和文本通道分别编码图像特征和文本特征;记忆向量是双通道记忆模块的参数,表示记忆语义空间,记为,为第个记忆向量;
7、视觉通道编码图像特征的过程,包括以下步骤:
8、s31:计算基于图像特征的不同记忆向量的权重,得到第个记忆向量的视觉权重分数;
9、s32:将应用到相应的记忆向量,计算所有记忆向量的加权和,得到对齐后的图像特征;
10、s33:串联对齐后的图像特征和图像特征,得到视觉通道输出的图像向量;
11、文本通道编码文本特征的过程,包括以下步骤:
12、s34:计算基于文本特征的不同记忆向量的权重,得到第个记忆向量的文本权重分数;
13、s35:将应用到相应的记忆向量,计算所有记忆向量的加权和,得到对齐后的文本特征;
14、s36:串联对齐后的文本特征和文本特征,得到文本通道输出的文本向量;
15、步骤四,利用大模型进行标签预测:将图像向量以及文本向量输入到大模型中,生成标签。
16、进一步地,步骤s31中,计算得到第个记忆向量的视觉权重分数时:
17、;
18、是一个可训练的参数矩阵;
19、步骤s32中,将应用到相应的记忆向量,计算所有记忆向量的加权和并得到对齐后的图像特征时:
20、;
21、步骤s33中,串联对齐后的图像特征和图像特征,得到视觉通道输出的图像向量时:
22、;
23、其中,表示向量串联。
24、进一步地,步骤s34中,计算得到第个记忆向量的文本权重分数时:
25、;
26、其中,是一个可训练的参数矩阵;
27、步骤s35中,将应用到相应的记忆向量,计算所有记忆向量的加权和并得到对齐后的文本特征时:
28、;
29、步骤s36中,串联对齐后的文本特征和文本特征,得到文本通道输出的文本向量时:
30、;
31、其中,表示向量串联。
32、与现有技术相比,本发明的有益技术效果是:
33、利用大模型优秀的文本编码及表征能力,提升多模态有害内容识别的性能。
34、通过双通道记忆模块,模型可以根据视觉特征为不同的记忆向量计算权重。这种权重分配使得模型能够更加准确地对信息进行对齐和融合。此外,视觉通道与文本通道采用相同的程序处理,确保了两种信息来源被平等且有效地考虑。
技术特征:
1.一种大模型结合双路记忆的多模态有害社交媒体内容识别方法,输入给定的图像和文本,输出用于判断多模态输入是否有害的标签,具体包括:
2.根据权利要求1所述的大模型结合双路记忆的多模态有害社交媒体内容识别方法,其特征在于:
3.根据权利要求1所述的大模型结合双路记忆的多模态有害社交媒体内容识别方法,其特征在于:
技术总结
本发明涉及社交媒体内容识别技术领域,公开了一种大模型结合双路记忆的多模态有害社交媒体内容识别方法,包括以下步骤:利用图像编码器提取图像的图像特征;利用文本嵌入模块,提取文本的文本特征;应用双通道记忆模块对图像特征以及文本特征建模,得到图像向量以及文本向量;利用大模型进行标签预测:图像向量以及文本向量输入到大模型中,生成标签。本发明通过双通道记忆模块,可以根据视觉特征为不同的记忆向量计算权重,这种权重分配使得模型能够更加准确地对信息进行对齐和融合。此外,视觉通道与文本通道采用相同的程序处理,确保了两种信息来源被平等且有效地考虑。
技术研发人员:宋彦,张勇东,田元贺
受保护的技术使用者:中国科学技术大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!