一种针对大型档案数据库的快速数据索引方法与流程
本发明涉及数据处理领域,尤其涉及一种针对大型档案数据库的快速数据索引方法。
背景技术:
1、随着信息技术的发展,大型档案数据库已经成为许多行业和领域中不可或缺的组成部分。这些数据库存储了大量的数据,如文档、图片、视频等,为用户提供了丰富的信息资源。然而,随着数据量的持续增长,如何高效地对这些数据进行索引和查询成为了一个重要的技术挑战。
2、传统的数据索引方法,如b-tree、r-tree等,虽然在小型或中型数据库中表现良好,但在大型档案数据库中,由于其固有的结构和算法限制,往往难以满足高效、实时的查询需求。特别是在高查询负载的情况下,这些方法可能会导致查询延迟增加、系统负载过高等问题。
3、因此,如何设计一种针对大型档案数据库的快速数据索引方法,既能高效地处理大量的查询请求,又能确保查询结果的准确性和完整性,同时还能在分布式环境中实现负载均衡,是当前数据库技术研究的一个热点和难点。
4、我国专利申请号:cn202310632686.5,公开日:2023.08.15,公开了一种数据库索引的优化方法、存储介质与设备。其中上述方法包括:获取数据库操作;根据数据库操作确定索引;根据索引在预设索引系统表中查找需要执行操作的索引分区,预设索引系统表用于记录索引与自身分区的对应关系;根据数据库操作的类型执行对应的操作。通过这种方法,在数据库中将索引进行分区,在接口调用数据库时根据预设系统表找到需要执行的索引分区,从而将高并发的压力分散到各个索引分区中,降低每个索引的并发访问冲突,以此来提升数据库的性能,并且索引分区能够根据调用数据库的接口中的信息来自行确定,提升了数据库使用的便利性。
5、但上述技术至少存在如下技术问题:现有技术没有采用高效预查询筛选机制,导致大量无效查询进入后续处理流程,增加了不必要的查询延迟和系统负载;没有对索引进行有效的压缩和分层存储,导致存储空间浪费和查询效率降低;难以应对节点间动态变化的负载,可能导致部分节点过载,而其他节点资源浪费;缺乏有效的查询优先级调度机制,导致关键查询的响应时间无法得到保障。
技术实现思路
1、本申请实施例通过提供一种针对大型档案数据库的快速数据索引方法,解决了现有技术没有采用高效预查询筛选机制,导致大量无效查询进入后续处理流程,增加了不必要的查询延迟和系统负载;没有对索引进行有效的压缩和分层存储,导致存储空间浪费和查询效率降低;难以应对节点间动态变化的负载,可能导致部分节点过载,而其他节点资源浪费;缺乏有效的查询优先级调度机制,导致关键查询的响应时间无法得到保障。本申请最终形成了一个完整的、高效的、自适应的数据索引系统,为大型档案数据库提供了一个高效、均衡、自适应的数据索引方法。
2、本申请提供了一种针对大型档案数据库的快速数据索引方法,具体包括以下技术方案:
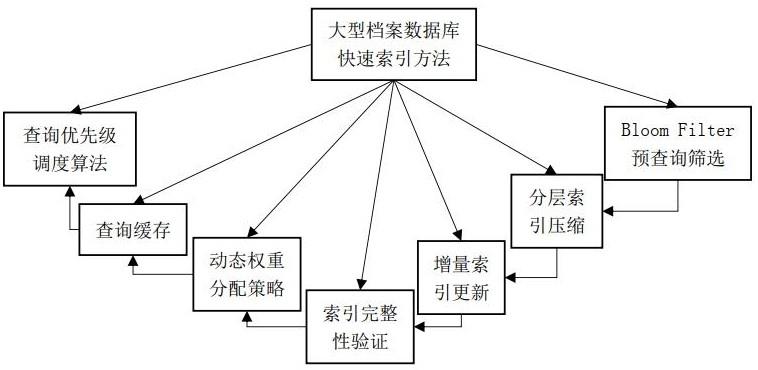
3、一种针对大型档案数据库的快速数据索引方法,包括以下步骤:
4、s100:创建bloom filter结构,进行预查询筛选;
5、s200:描述查询频率,对索引进行压缩存储,采用增量索引更新技术更新索引;
6、s300:设计分布式节点的动态权重分配策略,根据每个节点的实时负载和性能,动态调整其权重,优化各节点负载;
7、s400:选择缓存效益最大的查询进行缓存,设立查询优先级调度算法对所有查询按照其优先级进行排序。
8、优选的,所述s100,具体包括:
9、快速判断一个元素是否在数据库中,即检查一个元素是否在bloom filter中时,将元素放入k个哈希函数中。
10、优选的,所述s200,具体包括:
11、采用分层索引压缩技术,采用改进的zipf-mandelbrot法则来描述查询频率;所述改进的zipf-mandelbrot法则将频繁查询的索引项存储在顶层,使用最小的压缩,而不常查询的索引项存储在底层,使用高度压缩。
12、优选的,所述s200,还包括:
13、采用增量索引更新技术;当索引更新时,增量索引更新技术只记录变化的部分,而不是重新压缩整个索引;使用韦布尔分布来描述索引更新的频率;采用索引完整性验证技术;对于每个索引,索引完整性验证技术都计算一个向量,并使用余弦相似度来比较压缩前和压缩后的向量。
14、优选的,所述s300,具体包括:
15、定义一个负载指标,所述负载指标是基于每个节点的请求到达率和服务率的函数。
16、优选的,所述s300,还包括:
17、为每个节点分配一个权重,权重是基于节点的负载和其性能指标的函数;并对权重进行归一化。
18、优选的,所述s400,具体包括:
19、当查询请求到达节点时,首先检查查询缓存是否已经包含该查询的结果;查询缓存是一个动态维护的数据结构,它存储了最近执行的查询及其结果;引入效益函数,所述效益函数基于查询的频率查询在数据库中的执行时间。
20、优选的,所述s400,还包括:
21、为了最大化总体缓存效益,需要选择缓存效益最大的查询进行缓存。
22、优选的,所述s400,还包括:
23、当查询请求到达节点时,对于检查有缓存的查询结果则直接返回;对于没有缓存的查询结果,设立查询优先级调度算法来决定查询的处理顺序。
24、有益效果:
25、本申请实施例中提供的多个技术方案,至少具有如下技术效果或优点:
26、1、通过采用bloom filter结构,能够有效地筛选出不在数据库中的查询,从而避免了不必要的、耗时的查询,大大提高了查询效率;引入分层索引压缩技术,根据查询频率的长尾分布进行索引存储,既节省了存储空间,又确保了高频查询的快速响应;
27、2、通过设计分布式节点的动态权重分配策略,能够根据每个节点的实时负载和性能,动态调整其权重,从而实现负载均衡,提高系统整体稳定性和响应速度;引入查询缓存机制,将常用的查询结果缓存起来,从而减少查询时间;同时,通过查询优先级调度算法,确保关键查询得到及时响应,进一步提高用户体验。
28、3、采用基于日志的技术,只记录变化的部分,避免了重新压缩整个索引,从而提高了索引更新的效率;通过索引完整性验证技术,确保了在压缩和解压缩过程中数据的完整性,避免了因数据损坏导致的查询错误。
29、4、本申请的技术方案能够有效解决现有技术没有采用高效预查询筛选机制,导致大量无效查询进入后续处理流程,增加了不必要的查询延迟和系统负载;没有对索引进行有效的压缩和分层存储,导致存储空间浪费和查询效率降低;难以应对节点间动态变化的负载,可能导致部分节点过载,而其他节点资源浪费;缺乏有效的查询优先级调度机制,导致关键查询的响应时间无法得到保障。形成了一个完整的、高效的、自适应的数据索引系统,为大型档案数据库提供了一个高效、均衡、自适应的数据索引方法。
技术特征:
1.一种针对大型档案数据库的快速数据索引方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种针对大型档案数据库的快速数据索引方法,其特征在于,所述s100,具体包括:
3.根据权利要求1所述的一种针对大型档案数据库的快速数据索引方法,其特征在于,所述s200,具体包括:
4.根据权利要求1所述的一种针对大型档案数据库的快速数据索引方法,其特征在于,所述s200,还包括:
5.根据权利要求1所述的一种针对大型档案数据库的快速数据索引方法,其特征在于,所述s300,具体包括:
6.根据权利要求5所述的一种针对大型档案数据库的快速数据索引方法,其特征在于,所述s300,还包括:
7.根据权利要求1所述的一种针对大型档案数据库的快速数据索引方法,其特征在于,所述s400,具体包括:
8.根据权利要求7所述的一种针对大型档案数据库的快速数据索引方法,其特征在于,所述s400,还包括:
9.根据权利要求1所述的一种针对大型档案数据库的快速数据索引方法,其特征在于,所述s400,还包括:
技术总结
本发明涉及数据处理领域,尤其涉及一种针对大型档案数据库的快速数据索引方法。首先,创建Bloom Filter结构,进行预查询筛选;然后,描述查询频率,对索引进行压缩存储,采用增量索引更新技术更新索引;设计分布式节点的动态权重分配策略,根据每个节点的实时负载和性能,动态调整其权重,优化各节点负载;最后,选择缓存效益最大的查询进行缓存,设立查询优先级调度算法对所有查询按照其优先级进行排序。解决了现有技术未采用高效预查询筛选机制,增加了不必要的查询延迟和系统负载;没有对索引进行有效的压缩和分层存储,导致存储空间浪费和查询效率降低;难以应对节点间动态变化的负载以及缺乏有效的查询优先级调度机制的问题。
技术研发人员:李燕强,齐少华,马国伟,张泽宇
受保护的技术使用者:河北因朵科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!