一种流数据处理系统支持批数据处理的方法与流程
本发明属于计算机数据处理领域,尤其涉及一种流数据处理系统支持批数据处理的方法。
背景技术:
1、传统的离线etl场景中,通常需要使用多个独立的工具和框架进行数据抽取、转换和加载。这些工具之间缺乏紧密的集成和协作,导致数据处理流程复杂、效率低下,并且难以管理和监控。目前,kafka connect框架作为一种流数据集成解决方案,提供简单、可扩展和可靠的数据传输能力,广泛应用于实时数据处理场景。然而,对于离线etl(extract-transform-load,即抽取-转换-加载)场景,传统的kafka connect框架存在一些限制,无法满足精确时间范围(t + 1、t - 1等类似场景)下的大规模数据处理和数据转换的要求。
2、dolphinscheduler是一种开源的分布式任务调度框架,旨在提供高可靠性、高性能和高可扩展性的任务调度和管理解决方案。
3、因此,需要对kafka connect框架进行改造,并集成调度框架dolphinscheduler来简化离线etl的开发和管理流程。
技术实现思路
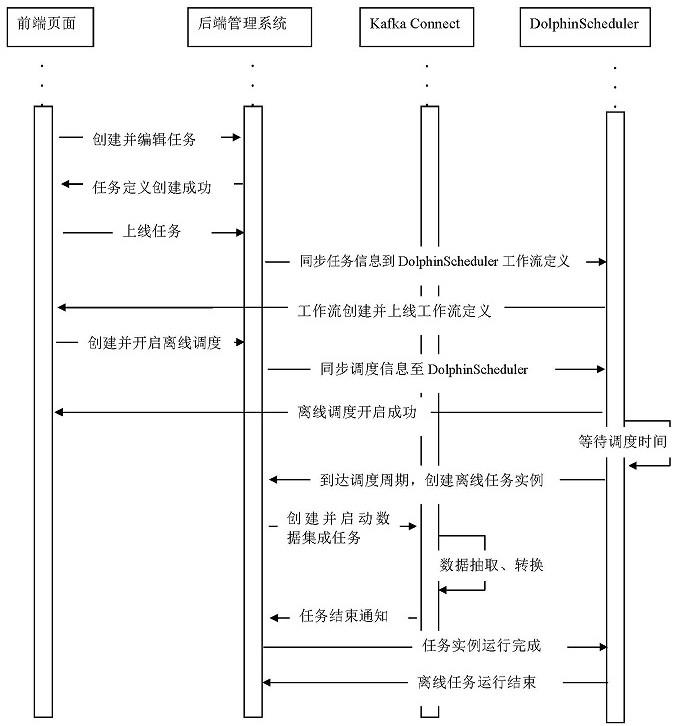
1、发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种流数据处理系统支持批数据处理的方法,包括以下步骤:
2、步骤1,配置数据输入节点:通过页面方式配置kafka connect框架中的输入连接器参数,定义来源数据源、来源字段信息;
3、步骤2,定义转换规则节点:使用kafka connect框架中transforms组件来定义离线etl任务的转换规则,例如:添加时间字段、数据过滤、数据映射等操作;
4、步骤3,配置输出节点:通过页面配置kafka connect框架中的输出连接器参数,定义目标数据源、字段映射信息;
5、步骤4,编排任务流程:以有向无环图dag的方式在页面上将kafka connect节点和转换规则节点连接成完整etl任务的执行流程图,再以http节点的形式同步到dolphinscheduler中,同时,设置任务实例的执行顺序,对于离线任务,在页面上设置任务的调度策略配置;
6、步骤5,执行任务调度:dolphinscheduler框架根据步骤4中配置好的任务的调度策略,自动触发和执行离线etl任务;
7、步骤6,离线任务实例停止:通过边界消息的方式,控制数据流的结束;
8、步骤7,监控和管理:提供任务的链路监控、数据监控和告警功能,实时监测任务的执行情况和运行状态。
9、步骤4中,所述任务实例的执行顺序包含以下四种:
10、并行:如果对于同一个任务定义,同时有两个以上任务实例,则并行执行任务实例;
11、串行等待:如果对于同一个任务定义,同时有两个以上任务实例,则后面是实例会等待前面实例执行完成之后再执行;
12、串行抛弃:如果对于同一个工作流定义,同时有两个以上工作流实例,则抛弃后生成的工作流实例并清除正在跑的实例;
13、串行优先:如果对于同一个工作流定义,同时有两个以上工作流实例,则按照优先级串行执行工作流实例。
14、步骤4中,所述调度策略配置是通过cron表达式的方式来配置,例如:每天中午12点触发,cron表达式可以设置为:0 0 12 * * ?;
15、步骤5中,在执行时间增量抽取的相关任务时,使用dolphinscheduler内置参数的方式去解析动态时间表达式。
16、步骤6包括:
17、步骤6-1,在输入任务的workersourcetask.poll()方法抽取完所有数据后,在最后一批数据的返回结果集(即:list<sourcerecord>)中加入离线任务抽取结束的消息,并保证消息处于返回结果集中的最后;同时保证kafka(kafka和kafka connect是属于不同的框架,前者是一种消息队列框架,后者是数据集成框架,后者在使用过程中会依赖前者)中每个分区都会有边界消息;
18、步骤6-2,在经过转换规则节点时,通过过滤识别的方式,放行边界消息;
19、步骤6-3,在输出节点任务执行数据写入相关方法后,识别到消息流中的边界消息,然后等待所有分区的边界消息都到达后,发送停止任务消息到kafka的主题topic中;在后端管理系统中监听主题topic,调用实例停止接口来停止离线任务实例。
20、步骤6-3中,所述相关方法指workersinktask的delivermessage()方法。
21、步骤7中,所述链路的监控是监测任务使用到的数据源的可用情况,所述数据监控是监控任务在一个固定时间段内输入和输出的数据量是否满足预期值,当监控到异常时,通过短信或者邮件的方式发送告警信息到指定用户。
22、本发明还提供了一种存储介质,存储有计算机程序或指令,当所述计算机程序或指令被运行时,实现所述一种流数据处理系统支持批数据处理的方法。
23、本发明涉及kafka、kafka connect框架、dolphinscheduler调度系统以及离线etl使用等技术,旨在提供一种有效的数据集成方案,在支持实时数据流处理引擎的系统上扩展了离线数据处理能力。
24、有益效果:通过本发明,可以让流数处理据框架上拥有运行批数据处理能力,使用统一接口方式来管理数据集成处理任务。同时在集群部署时,运行批处理任务的时候,借助kafka connect框架的重平衡机制,可以保证服务的高可用,单一节点故障时,系统能够自动恢复中断的任务,这个是传统批处理框架无法实现的。对于整个系统,所有服务都是无状态的,可以非常便捷地进行服务扩容与缩容,满足不同资源场景使用。
技术特征:
1.一种流数据处理系统支持批数据处理的方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,步骤4中,所述任务实例的执行顺序包含以下四种:
3.根据权利要求2所述的方法,其特征在于,步骤4中,所述调度策略配置是通过cron表达式的方式来配置。
4.根据权利要求3所述的方法,其特征在于,步骤5中,在执行时间增量抽取的相关任务时,使用dolphinscheduler内置参数的方式去解析动态时间表达式。
5.根据权利要求4所述的方法,其特征在于,步骤6包括:
6.根据权利要求5所述的方法,其特征在于,步骤6-3中,所述相关方法指workersinktask的delivermessage()方法。
7.根据权利要求6所述的方法,其特征在于,步骤7中,所述链路的监控是监测任务使用到的数据源的可用情况,所述数据监控是监控任务在一个固定时间段内输入和输出的数据量是否满足预期值,当监控到异常时,通过短信或者邮件的方式发送告警信息到指定用户。
8.一种存储介质,其特征在于,存储有计算机程序或指令,当所述计算机程序或指令被运行时,实现如权利要求1至7中任一项所述的方法。
技术总结
本发明提供了一种流数据处理系统支持批数据处理的方法,包括:步骤1,配置数据输入节点;步骤2,定义转换规则节点;步骤3,配置输出节点;步骤4,编排任务流程;步骤5,执行任务调度:DolphinScheduler框架根据步骤4中配置好的任务的调度策略,自动触发和执行离线ETL任务;步骤6,离线任务实例停止:通过边界消息的方式,控制数据流的结束;步骤7,监控和管理:提供任务的链路监控、数据监控和告警功能,实时监测任务的执行情况和运行状态。通过本发明,可以让流数处理据框架上拥有运行批数据处理能力,使用统一接口方式来管理数据集成处理任务。
技术研发人员:温立旭,狄云,胡蕾蕾,林锋
受保护的技术使用者:江苏数兑科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!