非独立同分布数据下人机对话系统的个性化联邦学习方法
本发明涉及人机对话系统中的数据隐私保护,是一种高隐私性非独立同分布数据下的人机对话系统的个性化联邦学习方法。
背景技术:
1、随着chatgpt的推出和其领域研究的重大突破,人工智能正处于一个前所未有的黄金时代,而大型语言模型已成为当前业界最引人瞩目的研究焦点。在这个领域中,人机对话系统作为大型语言模型的关键应用领域,吸引了广泛研究者的密切关注。随着对这个领域潜力的不断挖掘,对数据隐私问题的关注不断加剧,监管也变得更加严格。
2、当前的研究大多采用联邦学习算法,解决人机对话系统中的数据隐私问题。然而,当面对非独立同分布(non-iid)[5]数据分布的情况时,这些算法仍存在明显的瓶颈。因此,需要一种能够高效解决人机对话系统数据隐私问题的创新方法。在这个背景下,从个性化联邦学习的角度入手,深入研究人机对话系统中的非独立同分布数据特征。
3、现有技术的联邦学习算法泛化性能差,不能有效保护人机对话系统中的数据隐私,大大限制了人机对话系统领域的发展和广泛应用。
技术实现思路
1、本发明的目的是针对现有技术的不足而提供的一种非独立同分布数据下人机对话系统的个性化联邦学习方法,采用个性化联邦学习思想与元学习机制相融合的方法,巧妙地运用了元学习的自适应策略,并采用了双重学习的方式,实现了联邦学习与个性化学习的高效交汇。通过逐步的局部模型更新和全局对话模型的集体聚合,显著提升了人机对话系统在非独立同分布(non-iid)数据环境下的泛化性能,同时有效保护了其独特的个性化特征。此外,还深入分析了模型的收敛性,并探讨了数据异构性对系统性能的影响。通过广泛的实验验证,基于元学习的个性化联邦人机对话系统在面对非独立同分布(non-iid)数据的情境下展现出卓越的性能和隐私保护能力,有效克服了当前以fedavg为核心的联邦学习框架在保护人机对话系统数据隐私方面的限制,有效提高了人机对话系统在非独立同分布(non-iid)数据环境下的性能和数据隐私保护能力,它不仅将有望推动人机对话系统领域的发展,更为重要的是,为解决人工智能中的数据隐私问题提供了一种高效的解决方案,这将对未来的研究和应用产生深远的影响。
2、实现本发明的具体技术方案是:非独立同分布数据下人机对话系统的个性化联邦学习方法,其特点是该方法包括以下详细步骤:
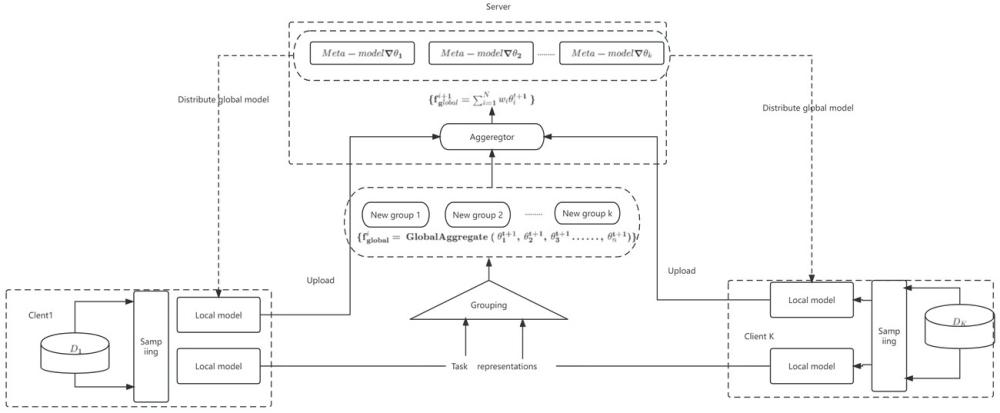
3、步骤1:为每个客户端分配本地数据集并在本地数据集训练本地对话模型其中,表示用户i的对话历史和回复,xij是输入对话历史,yij是对应的回复。
4、步骤2:基于元学习策略,为每个客户端生成个性化的本地参数元学习的目标是使每个客户端能够快速适应新的对话数据,从而提高系统的适应性。
5、步骤3:将个性化的本地参数应用于本地对话模型并使用本地数据通过下述(a)式生成更新后的本地参数
6、
7、其中,是通过计算每个客户端的本地对话模型损失函数而获得的,localupate()是每个客户端的本地对话模型损失函数,是每个客户端的本地数据集,θit是每个客户端的初始本地参数。
8、步骤4:将更新后的本地参数对本地对话模型进行更新,其更新过程采用双重学习机制,其中本地损失函数的梯度如下述(d)式所示:
9、
10、其中,l表示损失函数,表示本地对话模型的预测结果。
11、步骤5:将每个客户端更新后的本地参数上传到中央服务器,确保模型更新的数据隐私性,中央服务器聚合所有客户端上传更新后的本地参数并通过下述(b)式生成全局对话模型
12、
13、其中,是通过聚合每个客户端上传的参数生成的全局对话模型,globalaggregate()是全局对话模型的聚合函数,是由每个客户端上传更新后的本地参数。
14、根据权重分配wi对各客户端上传更新后的本地参数进行聚合,通过下述(c)式生成优化后的全局对话模型
15、
16、其中,wi表示分配给客户端i的权重,反映了联邦学习过程中的重要性,是各客户端更新后的参数,是包含各客户端数据特征的全局对话模型。
17、步骤6:将优化后的全局对话模型回传至每个客户端,用于更新下一轮每个客户端的本地参数θit,确保个性化信息的传递和保护。
18、步骤7:重复上述步骤直到模型收敛,在模型迭代的过程中,元学习策略逐渐优化了本地参数θit,同时参数聚合策略进一步优化了全局对话模型使系统性能不断提升。
19、本发明与现有技术相比具有显著提高人机对话系统在非独立同分布(non-iid)数据环境下的性能和数据隐私保护能力,元学习策略能够使个性化模型适应每个客户端的数据特点,同时保护数据隐私。双重学习机制有效融合了联邦学习和个性化学习,提高了系统的泛化能力和个性化特征。同时,参数聚合策略进一步优化了模型的全局性能。本发明基于元学习的个性化联邦学习策略不仅显著提高了系统在处理非独立同分布(non-iid)数据时的性能,还有效地增强了数据隐私保护的能力。通过元学习策略的应用,实现了个性化建模,这意味着系统能够更加智能地适应不同客户端数据的特征和差异,因而大幅度提高了系统的泛化能力,本发明进一步整合了双重学习机制,这种独特的设计有效地平衡了个性化学习与全局对话模型更新之间的权衡,为系统在处理非独立同分布数据环境下提供了卓越的性能和隐私保护能力。此外,还具备更高的通信效率,降低了数据传输的负担,从而加速了系统的运行速度。因此,这一技术创新不仅对于满足人机对话系统的个性化建模需求非常有用,还在强调数据隐私保护的应用场景中表现出色,为广泛的人机对话系统应用提供了全面的技术支持。
技术特征:
1.一种非独立同分布数据下人机对话系统的个性化联邦学习方法,其特征在于,采用个性化联邦学习与元学习的自适应和双重学习机制相融合的方法,实现人机对话系统中的数据隐私保护,具体包括以下步骤:
2.根据权利要求1所述的非独立同分布数据下人机对话系统的个性化联邦学习方法,其特征在于,所述步骤2的元学习策略具体包括以下步骤:
3.根据权利要求1所述的非独立同分布数据下人机对话系统的个性化联邦学习方法,其特征在于,所述步骤4采用双重学习机制更新本地对话模型fiθ,其更新过程具体包括以下步骤:
4.根据权利要求1所述的非独立同分布数据下人机对话系统的个性化联邦学习方法,其特征在于,所述步骤5具体包括以下步骤:
5.根据权利要求1所述的非独立同分布数据下人机对话系统的个性化联邦学习方法,其特征在于,所述步骤7具体包括以下步骤:
技术总结
本发明公开了一种非独立同分布数据下人机对话系统的个性化联邦学习方法,其特点是采用个性化联邦学习与元学习的自适应和双重学习机制相融合的方法,实现人机对话系统中的数据隐私保护,具体包括:本地数据集分配、个性化本地参数生成、本地对话模型更新和上传、全局对话模型聚合和发送、迭代收敛等步骤。本发明与现有技术相比具有显著提高人机对话系统在非独立同分布数据环境下的性能和数据隐私保护能力,成功构建个性化建模和数据隐私保护的人机对话系统应用,不仅对于满足人机对话系统的个性化建模需求非常有用,还在强调数据隐私保护的应用场景中表现出色,为广泛的人机对话系统应用提供了全面的技术支持。
技术研发人员:王廷,单文轩
受保护的技术使用者:华东师范大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!