基于语法的无监督分词方法、设备及存储介质与流程
本申请涉及自然语言处理,尤其涉及一种基于语法的无监督分词方法、设备及存储介质。
背景技术:
1、随着国家政策不断的推陈出新,企业需要借助政务服务系统及时地获取到最新的政务信息,政务服务系统为用户提供搜索功能,用户在政务服务输入搜索字段,随后政务服务系统匹配包含该搜索字段的搜索结果,并显示给用户。
2、目前的政务服务系统主要是基于国家语料库或者某些特定语料库使用分词器对用户输入的搜索字段进行拆分,再根据搜索字段的拆分结果挑选较为关键的搜索词语匹配搜索结果。
3、但是对于用户输入的搜索字段进行匹配结果的过程中,基于国家语料库或者某些特定语料库进行分词,当转换到具体的某业务领域时,拆分结果并不是很理想,从而可能导致反馈给用户的搜索结果的准确率较低。
技术实现思路
1、本申请提供了一种基于语法的无监督分词方法、设备及存储介质,能够通过识别用户搜索意图能够得到更多更准确的结果,从而有效提升反馈给用户的搜索结果的准确率。本申请提供如下技术方案:
2、第一方面,本申请提供一种基于语法的无监督分词方法,所述方法包括:
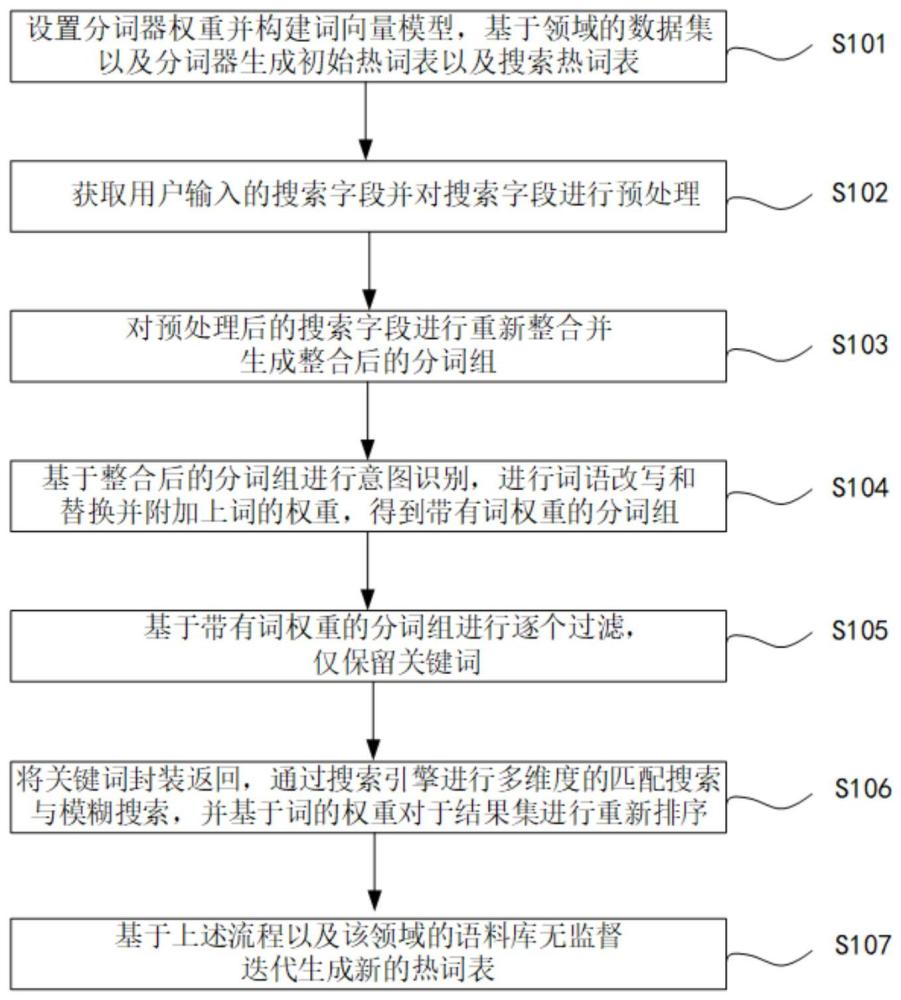
3、设置分词器权重并构建词向量模型,基于领域的数据集以及所述分词器生成初始热词表以及搜索热词表;
4、获取用户输入的搜索字段并对所述搜索字段进行预处理;
5、对预处理后的所述搜索字段进行重新整合并生成整合后的分词组;
6、基于所述整合后的分词组进行意图识别,进行词语改写和替换并附加上词的权重,得到带有词权重的分词组;
7、基于所述带有词权重的分词组进行逐个过滤,仅保留关键词;
8、将所述关键词封装返回,通过搜索引擎进行多维度的匹配搜索与模糊搜索,并基于词的权重对于结果集进行重新排序。
9、在一个具体的可实施方案中,所述设置分词器权重并构建词向量模型,基于领域的数据集以及所述分词器生成初始热词表以及搜索热词表包括:
10、对于有限的分词器,基于专家评估法和测试集,分别设置不同的权重,组合成一个分词器,并基于该领域的数据集无监督构建词向量模型;
11、随后基于该领域的数据集以及多个分词器生成初始热词表与手工配置的搜索热词表。
12、在一个具体的可实施方案中,所述对预处理后的搜索字段进行重新整合并生成整合后的分词组包括:
13、基于多个分词器对预处理后的搜索字段进行分词,得到分词组和对应的语义;
14、基于所述分词组以及所述词向量模型使用分词器做二次词语拆分与整合;
15、基于权重得到每一个分词器的处理后的分词组的权重概率,整合成新的分词组。
16、在一个具体的可实施方案中,所述基于所述分词组以及所述词向量模型使用分词器做二次词语拆分与整合包括:
17、尝试拼接多个以上拆分的词语,并判断拼接后的词语是否存在于词向量模型和搜索热词表中;
18、当新的拼接词本身不存在初始热词表中也不存在词向量模型中,此时将前后的词做单个词的拆分,再尝试做逐个拼接并再次判断是否存在于词向量模型中;
19、如果得到新的拼接词,基于原本词的语义得到新词的语义;
20、基于词性禁止某些词性进行组合;
21、根据拆分与整合的结果针对不同分词器的缺点进行优化。
22、在一个具体的可实施方案中,所述基于所述整合后的分词组进行意图识别,进行词语改写和替换并附加上词的权重,得到带有词权重的分词组包括:
23、首先逐个解析整合后的分词组,基于初始热词表和词向量模型,计算前后词的top-n关联词,如果出现拼音相似的关联度更高的词尝试进行替换;
24、随后逐个判断整合后的词语组的词性,基于不同领域的语法规则,设置词的不同权重,最后生成带有词权重的分词组。
25、在一个具体的可实施方案中,所述语法规则为动态配置,包括:
26、在相关政策的领域中,定语的修饰词权重设置为低;
27、出现动名次或者动词+名次时,后续的名词的重要度设置为高;
28、连续出现名次时,最后的名词相比之前的名词的重要度高。
29、在一个具体的可实施方案中,所述基于所述带有词权重的分词组进行逐个过滤,仅保留关键词包括:
30、当带有词权重的分词组中词为多的情况下,根据需要限制保留的关键词的词语数目;
31、基于词性,将带有词权重的分词组中的想要特殊处理与搜索的名词,分别采用单独的逻辑提取出来;
32、基于搜索热词表预设词语视为引力词,对于引力词设置更高的权重。
33、在一个具体的可实施方案中,所述基于搜索热词表预设词语视为引力词,对于引力词设置更高的权重包括:
34、基于词向量模型计算词向量的距离,词语中与所述搜索词的词向量距离最小的词即为该搜索词的引力词。
35、第二方面,本申请提供一种电子设备,所述设备包括处理器和存储器;所述存储器中存储有程序,所述程序由所述处理器加载并执行以实现如权利要求1至8任一项所述的一种基于语法的无监督分词方法。
36、第三方面,本申请提供一种计算机可读存储介质,所述存储介质中存储有程序,所述程序被处理器执行时用于实现如权利要求1至8任一项所述的一种基于语法的无监督分词方法。
37、综上所述,本申请的有益效果至少包括:
38、1)仅仅需要基于不同语料库无监督预训练好词向量即可,需要的训练资源少,此外算法流程不涉及复杂的矩阵运算,保证了数据的实时性。
39、2)将搜索拆分成多个子流程,流程之间耦合性低,不同流程处理不同的业务需求,方便进行扩展和搜索流程的定制,方便提取专门类型的词。
40、3)识别用户搜索意图能够得到更多更准确的结果,从而有效提升反馈给用户的搜索结果的准确率。
41、通过首先对预处理后的搜索字段进行清洗分词,并将搜索字段进行重组,随后基于词性做意图识别,改写词语并赋予词语不同的权重,整合多个分词器与词向量优化分词。最后保留关键词并使用es进行关键词搜索。识别用户搜索意图能够得到更多更准确的结果,从而有效提升反馈给用户的搜索结果的准确率。
42、上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,并可依照说明书的内容予以实施,以下以本申请的较佳实施例并配合附图详细说明如后。
技术特征:
1.一种基于语法的无监督分词方法,其特征在于,所述方法包括:设置分词器权重并构建词向量模型,基于领域的数据集以及所述分词器生成初始热词表以及搜索热词表;
2.根据权利要求1所述的基于语法的无监督分词方法,其特征在于,所述设置分词器权重并构建词向量模型,基于领域的数据集以及所述分词器生成初始热词表以及搜索热词表包括:
3.根据权利要求1所述的基于语法的无监督分词方法,其特征在于,所述对预处理后的搜索字段进行重新整合并生成整合后的分词组包括:
4.根据权利要求3所述的基于语法的无监督分词方法,其特征在于,所述基于所述分词组以及所述词向量模型使用分词器做二次词语拆分与整合包括:
5.根据权利要求1所述的基于语法的无监督分词方法,其特征在于,所述基于所述整合后的分词组进行意图识别,进行词语改写和替换并附加上词的权重,得到带有词权重的分词组包括:
6.根据权利要求5所述的基于语法的无监督分词方法,其特征在于,所述语法规则为动态配置,包括:
7.根据权利要求1所述的基于语法的无监督分词方法,其特征在于,所述基于所述带有词权重的分词组进行逐个过滤,仅保留关键词包括:
8.根据权利要求7所述的基于语法的无监督分词方法,其特征在于,所述基于搜索热词表预设词语视为引力词,对于引力词设置更高的权重包括:
9.一种电子设备,其特征在于,所述设备包括处理器和存储器;所述存储器中存储有程序,所述程序由所述处理器加载并执行以实现如权利要求1至8任一项所述的一种基于语法的无监督分词方法。
10.一种计算机可读存储介质,其特征在于,所述存储介质中存储有程序,所述程序被处理器执行时用于实现如权利要求1至8任一项所述的一种基于语法的无监督分词方法。
技术总结
本申请涉及自然语言处理技术领域,尤其涉及一种基于语法的无监督分词方法、设备及存储介质。方法包括设置分词器权重并构建词向量模型,基于领域的数据集以及分词器生成初始热词表以及搜索热词表;获取用户输入的搜索字段并对搜索字段进行预处理;对预处理后的搜索字段进行重新整合并生成整合后的分词组;基于整合后的分词组进行意图识别,进行词语改写和替换并附加上词的权重,得到带有词权重的分词组;基于带有词权重的分词组逐个过滤仅保留关键词;将关键词封装返回通过搜索引擎进行匹配搜索与模糊搜索,对于结果集进行重新排序。本申请能够通过识别用户搜索意图能够得到更多更准确的结果,从而有效提升反馈给用户的搜索结果的准确率。
技术研发人员:戴晔,夏晓东,徐雪阳,严世振,储建洲
受保护的技术使用者:江苏风云科技服务有限公司
技术研发日:
技术公布日:2024/1/5
- 还没有人留言评论。精彩留言会获得点赞!