一种针对图像分类模型的窃取攻击检测方法
本发明属于机器学习模型安全,涉及一种针对图像分类模型的窃取攻击检测方法,可应用于信息安全行业、金融服务、医疗保健和电子商务等领域。
背景技术:
1、近年来,随着互联网技术的快速发展,数据的产生量呈现爆炸式增长,这也催生了机器学习模型的兴起,并日益普及。其中基于深度神经网络的深度学习模型广泛应用于计算机视觉、图像分类、自然语言处理等领域。由于收集数据并训练一个高性能的深度神经网络模型需要耗费巨大的财力和人力,这也推动了一种新的商业模式——机器学习即服务(mlaas)的兴起。服务提供商将模型本身部署在安全的云服务器上,向没有资源训练模型的用户提供服务,只有管理者才能访问模型的参数和架构,用户只能通过基于云的应用程序接口(api)进行黑盒查询并获得模型的输出预测。
2、最近的研究表明,部署在mlaas上的模型容易受到模型窃取攻击,攻击者即使在数据受限的情况下,也能通过黑盒查询获取目标模型内部参数或构造一个无限逼近目标模型的替代模型,从而达到窃取模型信息的目的,这种攻击称为模型窃取攻击。这些模型可以在攻击者手中以各种方式被滥用,例如攻击者可以使用复制的模型来向用户提供同样的服务,从而侵犯模型拥有者的利益。此外,目标模型可用于制作对抗性样本,通过成员推理攻击损害用户隐私,并通过模型反演攻击泄露用于训练模型的敏感用户数据。在此背景下,检测模型窃取攻击对机器学习即服务提供商至关重要。
3、在现有的技术中,针对模型窃取攻击的检测方法主要通过检测用户的查询分布与良性查询分布之间的差异来判断用户是否为攻击者。攻击者想要达到窃取目标模型信息的目的往往需要对目标模型进行大量的查询,因此攻击者的查询行为与良性行为会有较大的不同。但现有针对模型窃取攻击的检测方法仍存在以下不足:通过攻击者采用向与目标模型训练数据同分布的一小部分种子样本中添加轻微的噪声的方法来构建攻击数据集,从而增加样本的隐蔽性,但如果想要检测到攻击者和良性用户之间这种轻微的查询分布差异,并保持较高的检测准确率,则需要对攻击者大量的查询数据进行检测,这会造成较大的计算开销。
4、例如北京理工大学在其申请的专利文献“结合训练集数据分布和w距离的模型窃取检测方法”(专利申请号:cn202211346069.0,申请公布号:cn115935179a)中,公开了一种结合训练集数据分布和w距离的模型窃取检测方法,该发明首先利用vae方法对训练集和查询集降维;其次利用极大似然估计计算查询集概率分布,依概率分布采样得到多组待检测样本;随后,对每组待检测样本,在训练集中随机采样得到相同数量的参考样本,计算每组待检测样本与参考样本间的w距离;最后,使用参考样本中类别数和总类别数的比值为权值,加权计算所有的w距离,当加权计算结果大于检测阈值时判定检测出为模型窃取。该发明提出关联训练集数据分布的模型窃取检测方法,同时考虑查询集和训练集样本分布特点,改进w距离计算方法,有效提升模型窃取检测的准确率。该方法存在的不足在于需要采样得到多组待检测样本,并需要计算每组待检测样本与参考样本间的w距离,这要求查询集包含较大的数量,会造成较大的计算开销。
技术实现思路
1、本发明的目的在于克服上述现有技术存在的不足,提出了一种针对图像分类模型的窃取攻击检测方法,旨在保持较高检测准确率的前提下降低计算开销。
2、为实现上述目的,本发明采取的技术方案包括如下步骤:
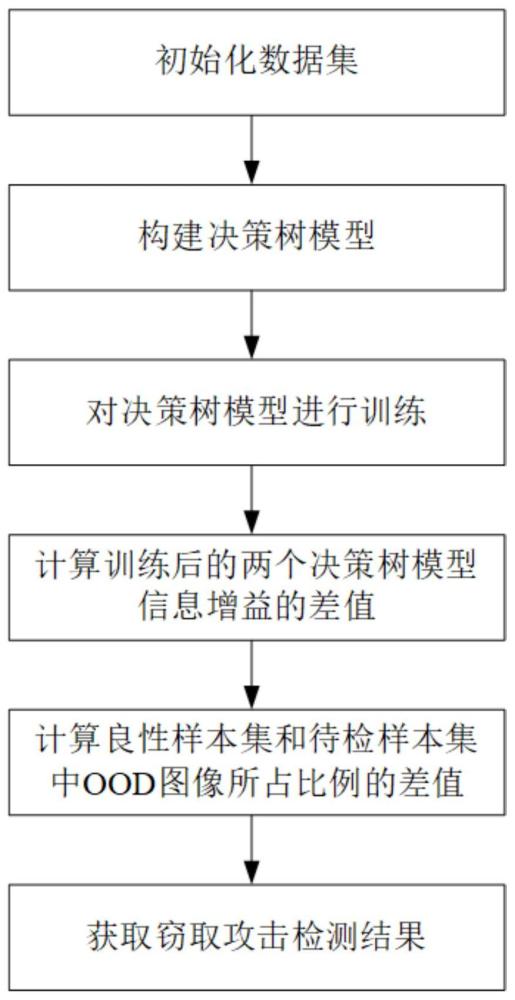
3、(1)初始化数据集:
4、将从图像分类模型的训练集中选取的包括k个目标类别的m幅图像dtr-d及其对应的标签dtr-l构成良性样本集a,n幅图像及其对应的标签构成验证样本集s,将从待检测用户的查询数据集中选取的m幅图像构成待检测图像duser及其对应的标签dlabel构成待检样本集b,其中,m≥100,n≥100,k≥2;
5、(2)构建决策树模型:
6、构建以良性样本集a中图像的每个像素值作为特征属性,以信息增益为划分准则,在分裂时考虑所有特征属性的第一决策树模型ta,和以待检样本集b中图像的每个像素值作为特征属性,以信息增益为划分准则,在分裂时考虑所有特征属性的第二决策树模型tb,并初始化ta和tb的深度为md,最大深度为md,叶子节点所需的最小样本数为ml;
7、(3)对决策树模型进行训练:
8、通过良性样本集a、待检样本集b分别对第一决策树模型ta、第二决策树模型tb进行训练,得到训练后的第一决策树模型to和第二决策树模型tu;
9、(4)计算训练后的两个决策树模型信息增益的差值:
10、将验证样本集s分别作为训练后的第一决策树模型to和第二决策树模型tu的输入进行分类,并通过分类结果计算to、tu的信息增益ing(s,to)、ing(s,tu),然后计算ing(s,to)与ing(s,tu)的差值h1=|ing(s,to)-ing(s,tu)|;
11、(5)计算良性样本集和待检样本集中ood图像所占比例的差值:
12、对良性样本集a和待检样本集b中的每个标签进行归一化,并将归一化得到的每个软标签中的最大值pmax与预先设定的阈值α满足pmax<α时该软标签对应的图像作为ood图像,否则作为id图像,然后计算a、b中ood图像所占比例po、pu,再计算po与pu的差值h2=|po-pu|;
13、(6)获取窃取攻击检测结果:
14、对ing(s,to)与ing(s,tu)的差值h1和po与pu的差值h2进行加权求和,并判断加权求和的结果h与设定的窃取攻击检测阈值τ是否满足h>τ,若是,用户认定为模型窃取攻击者,反之则认定为良性用户。
15、本发明与现有技术相比,具有以下优点:
16、本发明通过训练后的两个决策树模型信息增益的差值以及良性样本集和待检样本集中ood图像所占比例的差值的加权求和结果判断模型是否受到窃取攻击,信息增益能够有效地检测到攻击者和良性用户之间的查询分布差异,进而保证了较高的检测准确率;ood图像所占的比例可以在用户进行少量查询输入时,即可判断该用户是否为模型窃取攻击者,降低了计算开销;与现有技术相比,在保持较高检测准确率的前提下,降低了检测过程中的计算开销。
技术特征:
1.一种针对图像分类模型的窃取攻击检测方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,步骤(3)中所述的对第一决策树模型ta、第二决策树模型tb进行训练,实现步骤为:
3.根据权利要求1所述的方法,其特征在于,步骤(4)中所述的计算to、tu的信息增益ing(s,to)、ing(s,tu),计算公式分别为:
4.根据权利要求1所述的方法,其特征在于,步骤(5)中所述的对良性样本集a和待检样本集b中的每个标签进行归一化,归一化公式为:
5.根据权利要求1所述的方法,其特征在于,步骤(5)中所述的每个软标签中的最大值pmax,计算公式为:
6.根据权利要求1所述的方法,其特征在于,步骤(5)中所述的计算a、b中ood图像所占比例po、pu,计算公式分别为:
7.根据权利要求1所述的方法,其特征在于,步骤(6)中所述的对ing(s,to)与ing(s,tu)的差值h1和po与pu的差值h2进行加权求和,求和公式为:
技术总结
本发明提出了一种针对图像分类模型的窃取攻击检测方法,实现步骤为:初始化数据集;构建决策树模型;对决策树模型进行训练;计算训练后的两个决策树模型信息增益的差值;计算良性样本集和待检测样本集中OOD图像所占比例的差值;获取窃取攻击检测结果。本发明通过训练后的两个决策树模型信息增益的差值以及良性样本集和待检样本集中OOD图像所占比例的差值的加权求和结果判断模型是否受到窃取攻击,信息增益能够有效地检测到攻击者和良性用户之间的查询分布差异,进而保证了较高的检测准确率;OOD图像所占的比例可以在用户进行少量查询输入时,即可判断该用户是否为模型窃取攻击者,降低了计算开销。
技术研发人员:马卓,董嘉康,刘洋,刘心晶,张俊伟,李腾,马卓然
受保护的技术使用者:西安电子科技大学
技术研发日:
技术公布日:2024/1/5
- 还没有人留言评论。精彩留言会获得点赞!