一种面向多智能体强化学习决策优化的可视分析方法
本发明涉及强化学习领域,具体涉及一种面向多智能体强化学习决策优化的可视分析方法。
背景技术:
1、近年来,随着强化学习(reinforcement learning)在多个应用领域取得了令人瞩目的成果,并且考虑到在现实场景中通常会同时存在多个决策个体(智能体),部分研究者逐渐将眼光从单智能体领域延伸到多智能体。
2、由于多智能体环境相较于单智能体环境的复杂和多变,多智能体强化学习更难以看出真正的训练效果,难以判断智能体是否学习到策略以及学习到了什么样的策略、哪些因素是智能体做出决策的关键信息。目前还没有针对多智能体强化学习的分析工具,相较于单智能体环境,生活中更经常遇到的是多个智能体需要进行交互的多智能体环境。而在多智能体环境下,由于各智能体之间的相互影响、相互作用,随着智能体数量的增加和智能体动作更加复杂,想要达到训练预期也更加困难。
3、最重要的,因为多智能体环境的复杂性,单独通过一些简单的训练数据很难分析出一个智能体的行为是否影响其他智能体的决策、影响哪些智能体、产生怎样的影响、哪些因素造成这种影响等问题,如果可以确定这些问题,专家就可以通过调整网络结构或奖励值等策略来提高训练效果或速度。
技术实现思路
1、本发明的目的在于提供一种可以帮助分析多智能体强化学习训练效果的可视化系统,该系统可以帮助用户按照数据挑选感兴趣的游戏对局查看每个智能体的行为,并通过策略分析查看智能体的策略和各智能体之间的配合,还可以通过注意力分析查看智能体对于哪些信息更关注,通过哪些信息来支撑自己做出相应的决策。
2、为了解决上述技术问题,本发明的技术方案为:一种面向多智能体强化学习决策优化的可视分析系统,包括以下步骤:
3、s1、训练多智能体强化学习网络并收集训练数据:基于smac(星际争霸ii多智能体挑战)训练环境训练多种多智能体强化学习网络,得到各种多智能体强化学习模型(qmix、iql等)在难易度不同的训练环境下的训练数据。
4、s2、数据预处理:因为数据量较大且各项数据使用的频率不同,对s1得到的训练数据进行预处理,随机均匀的剔除掉部分数据并对其余数据按照使用频率进行拆分。
5、s3、使用预处理后的训练数据来制作可视化图表进行整个训练过程的整体展示并帮助用户精准锁定其感兴趣的训练对局。
6、s3.1、使用训练过程中收集的统计数据(包括平均胜率、网络损失值、梯度相关、平均q值)来绘制折线图帮助用户更快更好的确定其想要查看的训练批次(批次)进行进一步查看。
7、s3.2、总结每一个训练批次下的指标(奖励值、对局时长)帮助用户获得更全面的了解,使用平行坐标和降维散点图表现每个训练对局(训练对局)的异同,用户可以通过这些指标的差异进一步选中感兴趣的训练对局查看更详细的数据。
8、s4、通过训练过程中收集的强化学习网络产生的数据和智能体与训练交互产生的数据来查找和分析训练过程中的问题。
9、s4.1、将每个训练对局的数据整理为[动作,属性,时间]的形式并通过可视化图表进行展示,在此基础上还提供了模式匹配、常用模式查找、策略渲染等功能来帮助用户了解其训练效果。
10、s4.2、提供注意力分析图表来查看在复杂的训练环境下各智能体的关注点,以此来分析影响智能体做出选择的属性。
11、s5、进行决策优化,通过分析出的问题提出优化方案对训练进行优化,以此提高训练精度并针对性解决训练中存在的问题。
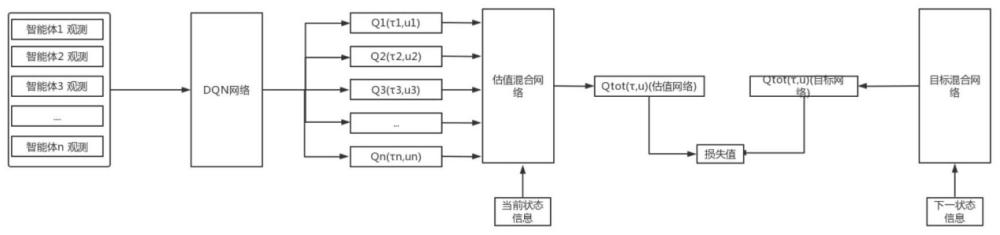
12、作为优选,步骤s1中每个智能体的强化学习dqn网络将共享参数,使用这种共享参数策略可以有效提高训练速度,提高的具体情况与智能体数量成正比。
13、作为优选,步骤s3中使用多折线图来更方便的根据多种数据来帮助用户更好地选择想要查看的批次。
14、作为优选,步骤s4.1还提供各智能体训练历史视图,可以方便用户查看每个智能体在最近一些对局中的表现和评分。
15、作为优选,步骤s4.2使用关系图来表示各智能体各属性的关注度,每个点表示一个属性,点的大小代表关注度,可以点击每个点来查看每个属性对于智能体选择各个动作的影响大小以及经过一个训练对局后的变化。
16、作为优选,步骤s5主要针对具体问题来提出具体解决方案,一般包括:优化强化学习网络、修改一些特定场景或动作的奖励值函数、添加关键输入信息等。针对一些常见的问题可以使用模式查找来找出失败对局中智能体经常采用的行为模式并在以后的训练中降低此行为模式的奖励值来提高训练效果,对于一些特殊的问题可以使用多个可视化视图进行分析来找出产生问题的原因并进行针对性解决。
17、本发明具有以下的特点和有益效果:为研究人员和开发人员提供强大的工具。本发明具有出色的数据分析能力,用户可以进行统计分析、趋势分析和比较分析,以获取关于智能体学习过程和性能的宏观视角。此外,系统还提供了行为模式的可视化,帮助用户更好地理解智能体的决策和行动。用户可以深入探索智能体行为模式的形成过程和原因,以及智能体之间的交互和合作。系统还允许用户可视化智能体网络关注分配,这比以前的工具更准确和有意义。用户可以深入了解代理对不同信息和功能的关注,从而优化他们的学习策略和网络设计。
技术特征:
1.一种面向多智能体强化学习决策优化的可视分析方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的面向多智能体强化学习决策优化的可视分析方法,其特征在于,步骤s1具体过程为:基于smac训练环境训练若干多智能体强化学习网络,得到各种多智能体强化学习模型在难易度不同的训练环境下的训练数据;
3.根据权利要求2所述的面向多智能体强化学习决策优化的可视分析方法,其特征在于,步骤s2具体过程为:随机均匀的剔除掉部分数据并对其余数据按照使用频率进行拆分。
4.根据权利要求3所述的面向多智能体强化学习决策优化的可视分析方法,其特征在于,步骤s3具体过程为:
5.根据权利要求4所述的面向多智能体强化学习决策优化的可视分析方法,其特征在于,s3.1所述统计数据包括平均胜率、网络损失值、梯度相关和平均q值;
6.根据权利要求5所述的面向多智能体强化学习决策优化的可视分析方法,其特征在于,s4具体过程为:
7.根据权利要求6所述的面向多智能体强化学习决策优化的可视分析方法,其特征在于,所述s4.1还提供各智能体训练历史视图;
8.根据权利要求7所述的面向多智能体强化学习决策优化的可视分析方法,其特征在于,s5还包括,使用模式查找,找出失败对局中智能体采用的行为模式,并在以后的训练中降低此行为模式的奖励值,提高训练效果。
技术总结
本发明公开了一个面向多智能体强化学习决策优化的可视分析方法,该方法首先训练多智能体强化学习网络,并收集训练数据进行预处理。其次使用预处理后的训练数据,制作可视化图表,进行整个训练过程的整体展示。然后通过训练过程中收集的强化学习网络产生的数据和智能体与训练交互产生的数据,查找和分析训练过程中的问题。最后进行决策优化,通过分析出的问题提出优化方案对训练进行优化,提高训练精度并针对性解决训练中存在的问题。本发明具有出色的数据分析能力,获取关于智能体学习过程和性能的宏观视角,帮助用户地理解智能体的决策和行动,优化学习策略和网络设计。
技术研发人员:吴向阳,顾浩嵚
受保护的技术使用者:杭州电子科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!