一种基于深度学习的中文冒犯性语言检测方法及系统
本发明属于自然语言处理,尤其涉及一种基于深度学习的中文冒犯性语言检测方法及系统。
背景技术:
1、近年来,随着twitter、facebook和微博等社交媒体平台的广泛普及,人们进行在线讨论的范围和规模在不断扩大。不幸的是,少部分用户滥用了在线社交媒体提供的匿名性,将其作为一种优势,并从事在现实世界中不可接受的社交行为,导致了冒犯性语言的不断出现。
2、在过去,许多研究人员为自动检测冒犯性语言工作做出了努力,已经提出了许多方法来检测冒犯性言论,然而大多都是基于传统机器学习的方法,传统的机器学习方法是为模型建立特征工程,手动提取有意义的特征,以便用于训练朴素贝叶斯,逻辑回归和支持向量机等机器学习模型,这种方法特别消耗人力资源。
3、随着传统机器学习模型的不断改进以及针对语言任务训练的现代模型性能的大幅提高,使得基于深度学习的冒犯性语言检测在科学研究中很受欢迎。深度学习方法采用多层神经网络从输入的原始数据中自动提取有用的特征。近几年来,许多研究使用深度学习来解决冒犯性语言检测的问题,并取得了优异的表现,一些研究已经证实了深度学习模型相比于机器学习模型的优越性。然而,在冒犯性语言检测领域中大部分的工作是在英语数据集上进行的,对于中文展开的研究很少。
技术实现思路
1、为解决上述技术问题,本发明提出一种基于深度学习的中文冒犯性语言检测方法及系统,有效的检测中文冒犯性语言。
2、为实现上述目的,本发明提供了一种基于深度学习的中文冒犯性语言检测方法,包括:
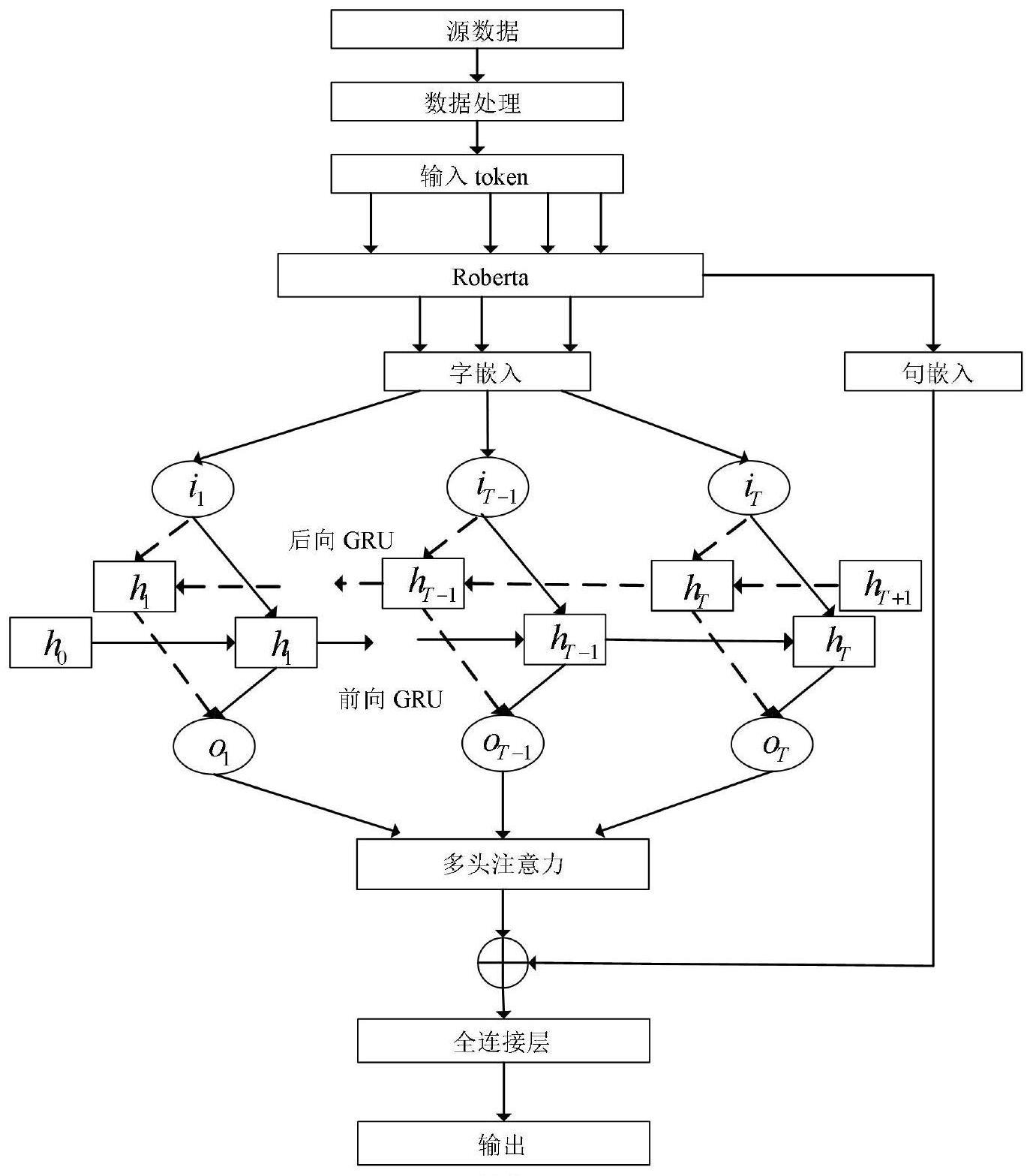
3、获取带有二元冒犯性标签的评论数据集,并对所述数据集进行预处理;
4、将预处理后的所述数据集输入roberta模型,获取句嵌入和字嵌入;
5、通过双向gru模型对所述字嵌入进行处理,获取所述双向gru模型的输出;
6、基于多头自注意力机制整合所述双向gru模型的输出,获取所述多头注意力机制的输出结果;
7、将所述多头注意力机制的输出结果和roberta模型提取的所述句嵌入进行拼接,获取中文冒犯性语言检测结果。
8、可选的,获取句嵌入和字嵌入包括:
9、将预处理后的所述数据集中的数据处理成输入序列;
10、利用所述roberta模型,提取所述输入序列的语义表示,获取所述句嵌入和所述字嵌入。
11、可选的,所述双向gru模型的输出为:
12、
13、其中,bigru(·)表示双向gru模型,dg表示gru模型的输出维度,hw表示输入的字嵌入矩阵。
14、可选的,基于多头自注意力机制整合所述双向gru模型的输出,获取所述多头注意力机制的输出结果包括:
15、可学习的权重矩阵将双向gru的输出映射为query、key、value,并将query、key、value输入到多头自注意力机制中,使用若干注意力头并行计算,将每个头的输出进行拼接,获取使用多头注意力计算得到的特征表示,之后应用一个线性层,对多头注意力的输出进行线性变换,得到输出结果,将在所述输出结果和所述句嵌入进行拼接,将拼接结果进行分类,获得中文冒犯性语言检测结果。
16、为实现上述目的,本发明还提供了一种基于深度学习的中文冒犯性语言检测系统,包括:数据集构建模块、模型构建模块和检测模块;
17、所述数据集构建模块,用于构建带有二元冒犯性标签的评论数据集,并对所述数据集进行预处理;
18、所述模型构建模块,用于构建检测模型,所述检测模型包括:roberta模型、双向gru模型和多头自注意力机制,所述检测模型用于进行中文冒犯性语言检测;
19、所述检测模块,用于根据所述检测模型获取检测结果。
20、可选地,所述模型构建模块包括:构建单元和训练单元;
21、所述构建单元,用于构建初始检测模型;
22、所述训练单元,用于根据预处理后的所述数据集对所述初始检测模型进行训练,获取所述检测模型。
23、可选地,所述检测模型为:
24、
25、
26、
27、
28、hconcat=[hr;ha]
29、o=dense(hconcat)
30、其中,roberta(·)表示roberta模型,bigru(·)表示双向gru模型,multiheadattention(·)表示多头自注意力机制,dr,dg和da分别表示roberta模型、双向gru模型和多头自注意力机制的输出维度,hr表示句嵌入,hw表示字嵌入矩阵,hg表示gru模型的输出,ha表示多头注意力的输出,hconcat表示hr和ha拼接后的结果,o表示最终输出。
31、与现有技术相比,本发明具有如下优点和技术效果:
32、1、本发明对冒犯性检测领域中中文攻击性语言问题进行了深入探讨,为中文攻击性语言检测技术的发展奠定了一定的基础。
33、2、本发明提出了一种将roberta模型的句嵌入和字嵌入、双向gru与多头自注意力机制相结合的神经架构。通过将多头注意力的输出结果与roberta的句嵌入进行拼接,该架构同时实现了对局部和全局信息的利用。将字嵌入和句嵌入这两种不同的层次的嵌入相结合,模型可以同时考虑单词级别和句子级别的信息,从而丰富了特征表示,此外,双向gru模型可以同时考虑前文和后文的信息。而句嵌入与多头注意力的结合将全局关系与原始句子级别的语义信息相结合。这些融合不仅增加了特征表示的多样性,还显著提升了模型的表征能力。
34、3、本发明在真实的数据集上进行了实验,在各种既定指标中,所提出的模型优于现有的基线模型,可以有效地检测中文冒犯性语言。
技术特征:
1.一种基于深度学习的中文冒犯性语言检测方法,其特征在于,包括:
2.根据权利要求1所述的基于深度学习的中文冒犯性语言检测方法,其特征在于,获取句嵌入和字嵌入包括:
3.根据权利要求1所述的基于深度学习的中文冒犯性语言检测方法,其特征在于,所述双向gru模型的输出为:
4.根据权利要求1所述的基于深度学习的中文冒犯性语言检测方法,其特征在于,基于多头自注意力机制整合所述双向gru模型的输出,获取所述多头注意力机制的输出结果包括:
5.一种基于深度学习的中文冒犯性语言检测系统,应用如权利要求1-4任一所述的方法,其特征在于,包括:数据集构建模块、模型构建模块和检测模块;
6.根据权利要求5所述的基于深度学习的中文冒犯性语言检测系统,其特征在于,所述模型构建模块包括:构建单元和训练单元;
7.根据权利要求5所述的基于深度学习的中文冒犯性语言检测系统,其特征在于,所述检测模型为:
技术总结
本发明公开了一种基于深度学习的中文冒犯性语言检测方法及系统,包括:获取带有二元冒犯性标签的评论数据集,并对所述数据集进行预处理;将预处理后的所述数据集输入RoBERTa模型,获取句嵌入和字嵌入;通过双向GRU模型对所述字嵌入进行处理,获取所述双向GRU模型的输出;基于多头自注意力机制整合所述双向GRU模型的输出,获取所述多头注意力机制的输出结果;将所述多头注意力机制的输出结果和RoBERTa模型提取的所述句嵌入进行拼接,获取中文冒犯性语言检测结果。本发明所提出的模型对中文冒犯性语言有较高的检测效果,具有较高的应用潜力。
技术研发人员:刘淑娴,徐美佳
受保护的技术使用者:新疆大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!