本发明涉及机器翻译,尤其涉及一种基于互信息和强化学习的无监督机器翻译方法。
背景技术:
1、在目前的无监督机器翻译方法中,反向翻译是模型获得双语对齐信息的主要方式,其核心思想是通过一个反向翻译模型对目标语言句子进行翻译,以得到伪平行语料。这种生成伪平行语料的方式存在两个主要缺点:一是反向翻译存在误差累积问题,即模型初始反向翻译产生的误差会随着训练迭代过程不断累积;二是模型训练与测试不一致问题,包含两个方面:一方面是数据不一致问题,即训练阶段反向翻译生成的源语言数据与测试阶段的源语言数据存在分布差异,前者是机器翻译风格,后者是自然风格;另一方面是暴露偏差(exposure bias)问题,即模型训练阶段的解码方式与测试阶段的解码方式不一致,具体为:训练阶段,模型解码器的输入为参考译文;而在测试阶段,模型解码器的输入为上一步骤解码器的输出,这种不一致性导致无监督机器翻译系统性能难以提高。
技术实现思路
1、对于很多小语种,平行语料的获取十分困难。在完全没有平行语料的条件下,由于没有监督信息,机器翻译系统难以学习得到源语言与目标语言句子之间的映射关系。针对此问题,本发明提出一种基于互信息和强化学习的无监督神经机器翻译方法。
2、本发明提供的一种基于互信息和强化学习的无监督机器翻译方法,包括:
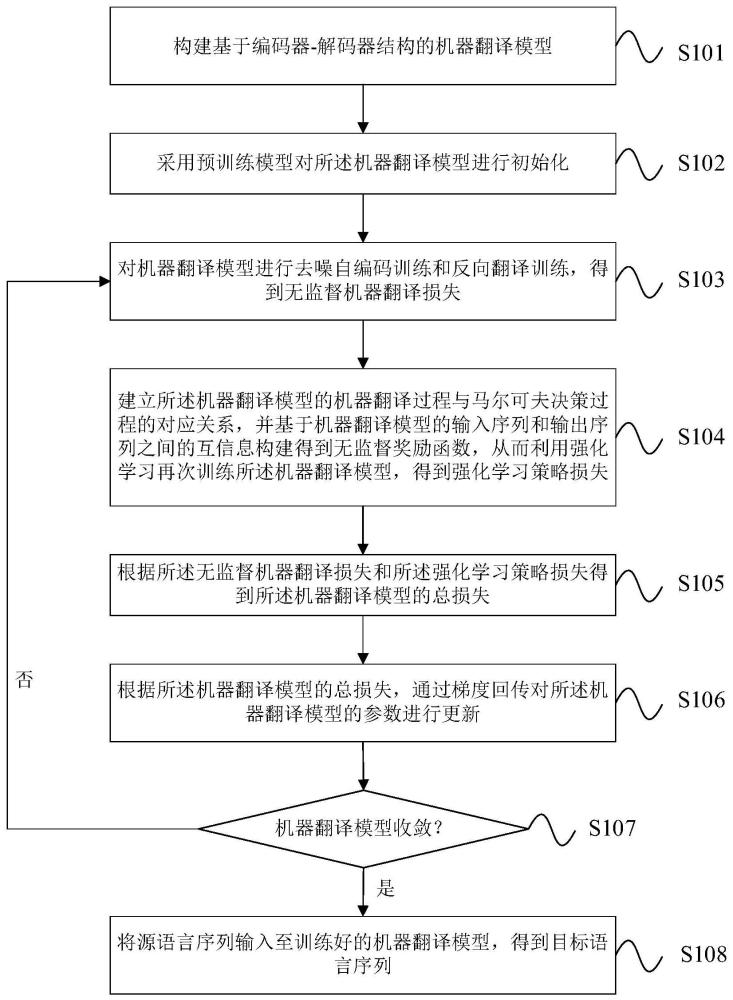
3、步骤1:构建基于编码器-解码器结构的机器翻译模型;
4、步骤2:采用预训练模型对所述机器翻译模型进行初始化;
5、步骤3:对所述机器翻译模型进行去噪自编码训练和反向翻译训练,得到无监督机器翻译损失;
6、步骤4:建立所述机器翻译模型的机器翻译过程与马尔可夫决策过程的对应关系,并基于机器翻译模型的输入序列和输出序列之间的互信息构建得到无监督奖励函数,从而利用强化学习再次训练所述机器翻译模型,得到强化学习策略损失;
7、步骤5:根据所述无监督机器翻译损失和所述强化学习策略损失得到所述机器翻译模型的总损失;
8、步骤6:根据所述机器翻译模型的总损失,通过梯度回传对所述机器翻译模型的参数进行更新;
9、步骤7:重复步骤3至步骤6,直至所述机器翻译模型收敛,得到训练好的机器翻译模型;
10、步骤8:将源语言序列输入至训练好的机器翻译模型,得到目标语言序列。
11、进一步地,步骤2中,所述预训练模型为xlm模型或mass模型。
12、进一步地,步骤3具体包括:
13、将单语语料库中选取当前批次的输入序列s,将所述输入序列s进行加噪处理,得到含噪序列s';
14、将所述含噪序列s'输入到去噪自编码器进行重建,得到输入序列s和重建序列之间的损失
15、将输入序列s输入到当前的机器翻译模型进行翻译,得到输出序列y;
16、将(y,s)作为平行句对输入至当前的机器翻译模型进行反向翻译训练,得到输入序列s和译文序列s”之间的损失其中,译文序列s”表示输入序列为y时的机器翻译模型的输出;
17、计算得到无监督机器翻译损失
18、进一步地,步骤4中,建立所述机器翻译模型的机器翻译过程与马尔可夫决策过程的对应关系,具体包括:
19、将翻译状态对应环境状态,将在时刻t的环境状态表示为st=<y<t,z>;其中,初始状态为s0=z,结束状态为st=<y,z>;y<t表示解码器已解码输出的部分翻译结果向量,t表示位于0~t时间段内的任一时刻,z=enc(x)表示编码器的编码输出向量,x为输入到机器翻译模型中的源语言序列,y为机器翻译模型输出的目标语言序列;
20、将目标语言的词汇表作为动作空间,存在at表示在时刻t采取的动作,yt表示机器翻译模型在时刻t输出的目标语言单词;
21、将解码器输出的条件概率作为策略函数,存在π=p(yt|y<t,z);
22、定义状态转移矩阵为p(st+1|st,at)=1。
23、进一步地,步骤4中,基于机器翻译模型的输入序列和输出序列之间的互信息构建得到无监督奖励函数,从而利用强化学习再次训练所述机器翻译模型,得到强化学习策略损失,具体包括:
24、将无监督奖励函数r1(st,at)定义为:
25、
26、其中,q(y|x)表示输入序列为x时,输出序列为y的条件概率的近似值,plm(y)表示目标语言模型lm的输出序列为y的概率;
27、计算强化学习策略损失
28、
29、其中,n表示批次大小,tn表示第n个输入序列样本对应的时间步长。
30、进一步地,所述目标语言模型lm采用n-gram语言模型。
31、进一步地,所述机器翻译模型的总损失为:
32、
33、其中,表示无监督机器翻译损失,表示强化学习策略损失,α为权重。
34、本发明的有益效果:
35、(1)本发明将机器翻译过程视为一种马尔可夫决策过程,将机器翻译模型视为策略函数,基于输入输出之间的互信息构建得到一种无需正确翻译结果的无监督奖励函数,采用强化学习算法训练机器翻译模型,通过不断调整模型参数使得累积奖励最大化,有效提升了无监督机器翻译系统的性能。
36、(2)在具体的互信息奖励函数计算过程中,利用目标语言单语语料训练语言模型计算翻译结果的先验概率,基于当前翻译模型对源语言数据进行解码翻译计算翻译结果的后验概率,利用二者的对数得分差值得到输入、输出互信息的下界,进而通过最大化该下界来达到最优化互信息的目的。
37、(3)相比于基于回译的无监督机器翻译方法,本发明方法可以在不增加训练开销的条件下,有效提升无监督机器翻译模型性能;同时由于没有平行语料的约束,并得益于强化学习的强大探索能力,翻译结果的多样性也得到有效提升。
技术特征:1.一种基于互信息和强化学习的无监督机器翻译方法,其特征在于,包括:
2.根据权利要求1所述的一种基于互信息和强化学习的无监督机器翻译方法,其特征在于,步骤2中,所述预训练模型为xlm模型或mass模型。
3.根据权利要求1所述的一种基于互信息和强化学习的无监督机器翻译方法,其特征在于,步骤3具体包括:
4.根据权利要求1所述的一种基于互信息和强化学习的无监督机器翻译方法,其特征在于,步骤4中,建立所述机器翻译模型的机器翻译过程与马尔可夫决策过程的对应关系,具体包括:
5.根据权利要求4所述的一种基于互信息和强化学习的无监督机器翻译方法,其特征在于,步骤4中,基于机器翻译模型的输入序列和输出序列之间的互信息构建得到无监督奖励函数,从而利用强化学习再次训练所述机器翻译模型,得到强化学习策略损失,具体包括:
6.根据权利要求5所述的一种基于互信息和强化学习的无监督机器翻译方法,其特征在于,所述目标语言模型lm采用n-gram语言模型。
7.根据权利要求1所述的一种基于互信息和强化学习的无监督机器翻译方法,其特征在于,所述机器翻译模型的总损失为:
技术总结本发明提供一种基于互信息和强化学习的无监督机器翻译方法。该方法包括:构建基于编码器‑解码器结构的机器翻译模型;采用预训练模型对机器翻译模型进行初始化;对机器翻译模型进行去噪自编码训练和反向翻译训练,得到无监督机器翻译损失;建立机器翻译模型的机器翻译过程与马尔可夫决策过程的对应关系,并基于机器翻译模型的输入序列和输出序列之间的互信息构建得到无监督奖励函数,从而利用强化学习再次训练机器翻译模型,得到强化学习策略损失;根据无监督机器翻译损失和强化学习策略损失得到机器翻译模型的总损失;通过梯度回传对机器翻译模型的参数进行更新;重复上述训练过程,直至机器翻译模型收敛。
技术研发人员:张文林,万玉宪,李真,屈丹,陈琦,张昊
受保护的技术使用者:中国人民解放军战略支援部队信息工程大学
技术研发日:技术公布日:2024/1/15