面向客户细分的关联规则挖掘方法
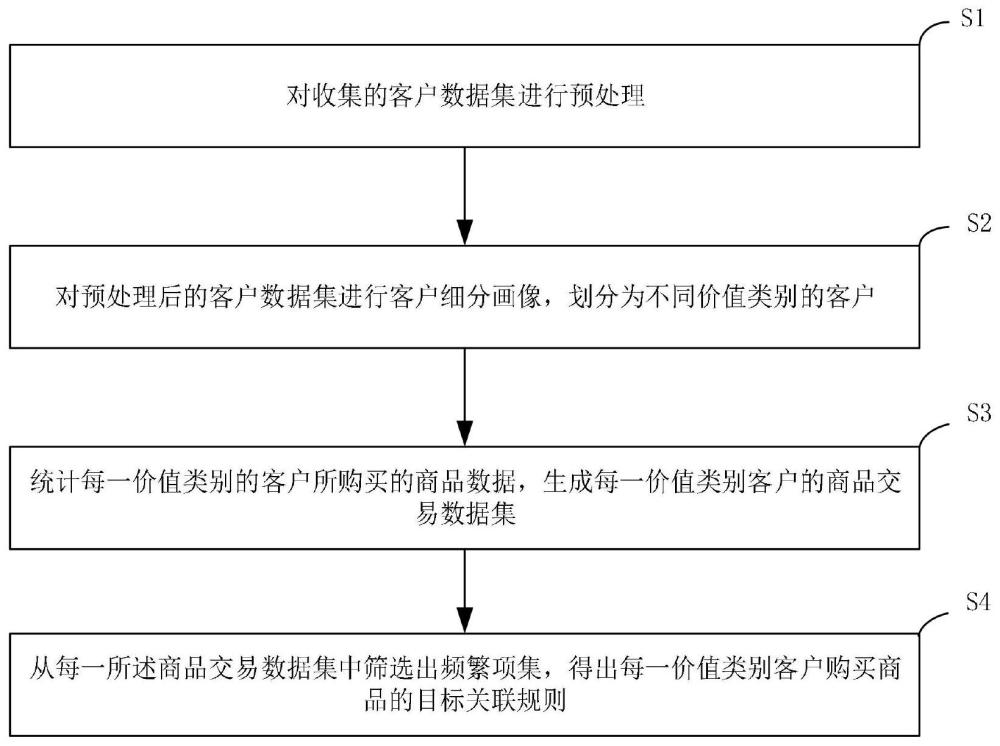
本发明属于数据挖掘,尤其涉及一种面向客户细分的关联规则挖掘方法。
背景技术:
1、面向客户细分的关联规则挖掘可以从消费者交易记录中发掘商品与商品之间的关联关系,进而通过商品捆绑销售或者相关推荐的方式带来更多的销售量。现有的方法发现的均为商品间的关联关系,没有考虑各个属性的重要程度,而且忽略了不同客户之间的差异性和多样性,并未对商品与客户群体特征之间进行关联性分析,导致挖掘出的关联规则缺乏针对性和有效性。
技术实现思路
1、针对现有技术的不足,本发明提出一种面向客户细分的关联规则挖掘方法,通过对客户进行细分,并在客户细分的条件下分析商品与客户群体特征之间的关联性,提高了关联规则挖掘的效率,提高结果的利润率。
2、为了实现上述目的,本发明一方面提供一种面向客户细分的关联规则挖掘方法,包含:
3、对收集的客户数据集进行客户细分画像,划分为不同价值类别的客户;
4、统计每一价值类别的客户所购买的商品数据,生成每一价值类别客户的商品交易数据集;
5、从每一所述商品交易数据集中筛选出频繁项集,得出每一价值类别客户购买商品的目标关联规则。
6、在一些实施例中,以客户最后一次购买日期和统计周期结束日期之间的时间间隔、客户在统计期间的购买次数、以及在统计期间客户在购买中花费的总金额与每个客户消费产生的总利润作为评价指标,构造客户细分模型,确定所述客户数据集中每一客户的价值得分,
7、score=wr×r+wf×f+wm×mp
8、其中,score表示客户价值得分,r表示客户最后一次购买日期和统计周期结束日期之间的时间间隔,为第一评价指标;f表示客户在统计期间的购买次数,为第二评价指标;为第三评价指标,m表示统计期间客户在购买中花费的总金额,p表示每个客户消费产生的总利润,q1、q2为权重;wr、wf、wm分别表示r,f,mp这三个评价指标的权重。
9、在一些实施例中,采用k-means聚类算法对客户价值得分进行聚类,划分出不同价值类别的客户,包含:
10、统计客户数据集中每一客户的价值得分,生成价值得分数据集;
11、从所述价值得分数据集中随机选择k个价值得分数据作为k个聚类的聚类中心,k表示聚类分组数;
12、将所述价值得分数据集中剩余每个数据分配到其中心距离最短的那一聚类中;
13、重新计算每一聚类的新的聚类中心,并在新的聚类中心与上一次迭代中得到的聚类中心相同时,输出所述聚类分组数。
14、在一些实施例中,通过确定不同聚类分组数k下的轮廓系数,确定最佳的k值。
15、在一些实施例中,利用熵权法结合层次分析法,确定所述客户细分模型中各个评价指标的权重,包含:
16、为所述第一评价指标、第二评价指标、第三评价指标构造层次模型,
17、从所述第一评价指标、第二评价指标、第三评价指标中选取一指标,利用熵权法确定该指标的第一权重;
18、将所述第一权重输入所述层次模型中,用层次分析法得到所述第一评价指标、第二评价指标、第三评价指标的第二权重。
19、在一些实施例中,利用熵权法确定评价指标的第一权重,包含:
20、每一评价指标包含每一客户对应的子指标;
21、对各子指标进行归一化,计算各子指标的信息熵值为:
22、
23、式中,一子指标所占的比值xij表示第i个客户样本的第j个子指标;i=1,2,…,n;j=1,2,…,m;
24、计算信息熵差异系数为:
25、pj=1-hj(j=1,2,…,m)
26、根据信息熵系数计算各子指标权重为:得到第一权重。
27、在一些实施例中,从每一所述商品交易数据集中筛选出频繁项集,得出每一价值类别客户购买商品的关联规则,包含:
28、扫描每一所述商品交易数据集,根据支持度找到频繁项目集,
29、把得到的频繁项集生成候选关联规则,丢弃置信度值低于最小置信度的候选关联规则,得到每一价值类别客户购买商品的目标关联规则。
30、在一些实施例中,根据支持度找到频繁项目集,包含:
31、统计每一所述商品交易数据集中频繁出现的项目集的出现次数,删除支持度低于第一阈值的项目,将剩余的项目按支持度降序排序并存储在项头表中;
32、读取所述项头表,删除其中的支持度低于第一支持度阈值的项目,将剩余的项目按支持度降序排序,确定频繁项集;
33、将每一所述商品交易数据集中排序后的频繁项集依次插入频繁模式树中,构建fp-tree。
34、在一些实施例中,在fp-tree的项头表前加入哈希表和有序链表,用于记录每一个数据项当前的最后一个节点。
35、在一些实施例中,对客户数据集进行客户细分画像之前,还包含:
36、对客户数据集进行预处理,包含:
37、对满足预设清洗条件的数据进行丢弃、删除;
38、对数据清理后的客户数据集进行邻域属性约简,计算每个样本的邻域,并分析邻域与样本的一致性,在剩余样本中生成正域样本。
39、本发明一方面还提供了一种面向客户细分的关联规则挖掘装置,采取上述的面向客户细分的关联规则挖掘方法,该装置至少包含:
40、客户细分模块,用于对收集的客户数据集进行客户细分画像,划分为不同价值类别的客户;
41、关联规则挖掘模块,用于统计每一价值类别的客户所购买的商品数据,生成每一价值类别客户的商品交易数据集;
42、从每一所述商品交易数据集中筛选出频繁项集,得出每一价值类别客户购买商品的目标关联规则。
43、本发明另一方面还提供了一种可读存储介质,可读存储介质上存储有程序或指令,该程序或指令被处理器执行时实现上述面向客户细分的关联规则挖掘方法的步骤,且能达到相同的技术效果。
44、由以上方案可知,本发明的优点在于:
45、本发明提供的面向客户细分的关联规则挖掘方法,通过对收集的客户数据集进行客户细分画像,划分为不同价值类别的客户;然后,统计每一价值类别的客户所购买的商品数据,生成每一价值类别客户的商品交易数据集;最后,从每一所述商品交易数据集中筛选出频繁项集,得出每一价值类别客户购买商品的目标关联规则。该方法引入利润属性改进了rfm模型,提高结果的利润率;并利用熵权法和层次分析法综合求权重来确定改进后rfm模型各个指标的权重,同时利用轮廓系数确定最优k值后,使用k-means算法进行聚类,建立客户细分模型,提高客户细分的精确度,实现企业收益的最大化。同时,采用在fp-tree筛选出频繁项集,确定每一价值类别客户购买商品的目标关联规则,并在项头表前加入哈希表和有序链表,通过避免重复扫描数据集来提高关联规则挖掘效率,大大减少了搜索时间。
技术特征:
1.一种面向客户细分的关联规则挖掘方法,其特征在于,包含:
2.根据权利要求1所述的方法,其特征在于,包含:
3.根据权利要求2所述的方法,其特征在于,包含:
4.根据权利要求3所述的方法,其特征在于,包含:
5.根据权利要求2所述的方法,其特征在于,
6.根据权利要求5所述的方法,其特征在于,
7.根据权利要求1所述的方法,其特征在于,从每一所述商品交易数据集中筛选出频繁项集,得出每一价值类别客户购买商品的关联规则,包含:
8.根据权利要求7所述的方法,其特征在于,
9.根据权利要求8所述的方法,其特征在于,还包含:
10.根据权利要求1所述的方法,其特征在于,对客户数据集进行客户细分画像之前,还包含:
技术总结
本发明提供一种面向客户细分的关联规则挖掘方法,该方法包含:对收集的客户数据集进行客户细分画像,划分为不同价值类别的客户;统计每一价值类别的客户所购买的商品数据,生成每一价值类别客户的商品交易数据集;从每一所述商品交易数据集中筛选出频繁项集,得出每一价值类别客户购买商品的目标关联规则。该方法提高客户细分的精确度,结果的利润率,实现企业收益的最大化。
技术研发人员:韩彤童,于钰娜,刘文博
受保护的技术使用者:齐鲁理工学院
技术研发日:
技术公布日:2024/3/17
- 还没有人留言评论。精彩留言会获得点赞!