一种基于大语言模型的智能数据分析方法及装置与流程
本发明涉及自然语言处理领域,尤其涉及一种基于大语言模型的智能数据分析方法及装置。
背景技术:
1、在当今数字化时代,数据量的爆发式增长以及复杂多样的数据类型对企业和组织的数据分析提出了严峻的挑战。数据分析作为一种重要的决策支持工具,被广泛应用于市场研究、业务规划、客户洞察、风险评估等多个领域。然而,传统的数据分析方法往往需要专业分析人员进行操作,其复杂性和门槛限制了许多非专业人士的参与,导致数据资源的浪费和潜在价值未能充分挖掘。
技术实现思路
1、为了解决以上技术问题,本发明提供了一种基于大语言模型的智能数据分析方法。基于gpt等大语言模型,使用提示学习、微调和智能代理等方法,降低数据分析门槛,提高数据分析效率及精度。
2、本发明的技术方案是:
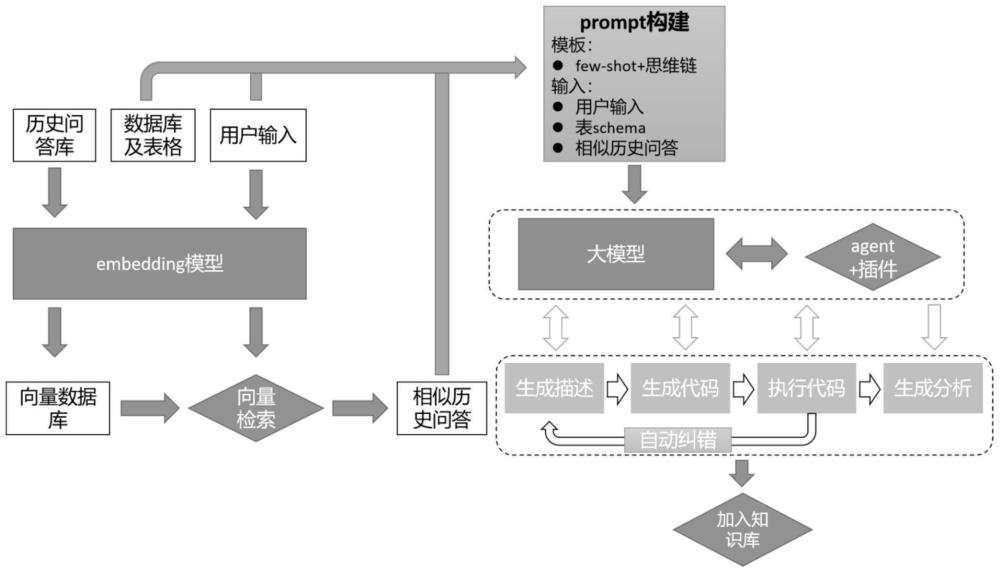
3、一种基于大语言模型的智能数据分析方法,首先收集领域常见问题形成问题库,然后人工将领域常见问题转换为对代码生成友好的描述,进而生成问题-描述数据集(下文称为问题理解数据集),然后收集常见的代码生成数据集(例如text-to-sql数据集),用两个数据集对大模型进行微调,使其在该领域的问题理解及代码生成方面具有良好的性能,用户上传数据或选择相应数据库后,通过相应数据读取工具(llama-index等)获取数据表的schema信息,获取历史相似文答信息,然后整合信息基于提示学习及思维链方法生成模型输入,输入大模型后,输出工具执行链,智能代理(agent)根据工具执行链一步步调用相关工具进行操作,得出分析结果。
4、进一步的,
5、工具执行链的流程如下:
6、步骤1-调用大模型生成问题描述;
7、步骤2-根据描述生成数据查询代码;
8、步骤3-调用相应解释器执行代码获取查询结果;
9、步骤4-调用相应工具(llm、图表生成工具等)对结果进行分析得出分析结果。
10、其中步骤3执行报错时会触发自动纠错机制,agent将报错结果再次输入步骤2,使其重新生成正确的代码。
11、进一步的,
12、获取历史相似文答信息旨在提高系统的“记忆力”,它通过embedding模型对大模型生成的结果和问题进行向量化,然后存储进向量数据库中,每次用户的提问都会经过embedding模型向量化,然后采用语义相似度检索方法从向量数据库中查找最相似的k个历史问题,将其作为few-shot一同输入大模型,以提高输出的准确率。
13、再进一步的,具体步骤如下:
14、1)收集领域常见问题及描述制作问题理解数据集;
15、2)收集问题-代码对数据制作代码生成数据集;
16、3)利用1)、2)中两个数据集微调大模型,提升其在问题理解和代码生成方面的能力;
17、4)对用户输入的问题进行检索,得到k个相似历史问答;
18、5)预处理模块处理读取数据库表格等数据生成表schema信息,利用提示模板整合相似历史问答、表schema、用户问题等信息,结合思维链方法生成prompt;
19、6)输入大模型输出工具执行链;
20、7)利用智能代理一步一步按照工具链执行相应命令,最后得出分析结果;
21、8)将大模型输出信息及用户问题进行embedding存入向量数据库。
22、此外,本发明还提供了一种基于大语言模型的智能数据分析装置,包括:预处理模块、数据分析模块、历史问答模块。其中,预处理模块用于对用户问题及数据进行预处理生成prompt,数据分析模块用于根据用户问题查询对应数据并进行分析输出分析结果,历史问答模块用于记录用户历史问答,为以后问答提供更多依据,提高问答质量。
23、进一步的,
24、首先收集领域常见问题形成问题库,然后人工将领域常见问题转换为对代码生成友好的描述,进而生成问题-描述数据集,然后收集常见的代码生成数据集,用两个数据集对大模型进行调节;用户上传数据或选择相应数据库后,通过相应数据读取工具获取数据表的schema信息,通过历史问答模块获取历史相似文答信息,然后整合信息基于提示学习及思维链方法生成模型输入,输入大模型后,输出工具执行链,智能代理(agent)根据工具执行链一步步调用相关工具进行操作,得出分析结果。
25、其中历史问答模块旨在提高系统的“记忆力”,它通过embedding模型对大模型生成的结果和问题进行向量化,然后存储进向量数据库中,每次用户的提问都会经过embedding模型向量化,然后采用语义相似度检索方法从向量数据库中查找最相似的k个历史问题,将其作为few-shot一同输入大模型,以提高输出的准确率。
26、通过问题-描述转换机制,解决模糊问题转换为相应代码正确率低的问题。设置历史问答模块,采用向量数据库作为系统记忆模块,提高对用户提问习惯的理解。设置自动纠错模块,通过智能代理实现代码的验证及纠错,提高代码生成正确率。
27、本发明的有益效果是
28、本发明的优点在于,降低了数据分析门槛,使普通人可以充分挖掘领域数据资源和潜在价值。针对模糊问题的描述理解,可以有效把握用户意图,提高反馈的可靠性和准确性。历史问答模块可以充分掌握每一个使用者的提问习惯,提高大模型对用户问题的理解能力。自动纠错模块提高了代码执行的成功率,提高了回答的准确性。
技术特征:
1.一种基于大语言模型的智能数据分析方法,其特征在于,
2.根据权利要求1所述的方法,其特征在于,
3.根据权利要求2所述的方法,其特征在于,
4.根据权利要求2所述的方法,其特征在于,
5.根据权利要求4所述的方法,其特征在于,
6.一种基于大语言模型的智能数据分析装置,其特征在于,
7.根据权利要求6所述的方法,其特征在于,
8.根据权利要求6所述的方法,其特征在于,
9.根据权利要求8所述的方法,其特征在于,
技术总结
本发明提供一种基于大语言模型的智能数据分析方法及装置,属于自然语言处理领域,本发明基于GPT等大语言模型,使用提示学习(PromptLearning)、微调(Fine‑Tuning)和智能代理(Agent),实现领域问题解析、代码生成、代码执行、结果分析的全自动数据分析流程,能够有效针对用户提出的模糊问题进行专业解析,结合历史问答和自动纠错等模块建立可靠的数据分析能力,帮助企业安全、高效的输入自然语言进行数据分析。
技术研发人员:王光鑫,高岩,邵嘉豪
受保护的技术使用者:山东浪潮科学研究院有限公司
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!