基于视频的图文网页生成方法及装置与流程
本发明涉及互联网,尤其涉及一种基于视频的图文网页生成方法及装置。
背景技术:
1、随着互联网和数字媒体的迅速发展,视频内容的传播和消费逐渐成为主流。然而,对于一些内容生产者和读者来说,快速查询、获取视频内容可能存在一定的难度和限制。
2、现阶段大多通过模型根据语音生成文字或者给视频打上字幕,对于口音、多音字等原因语音生成的文字可能存在未纠错导致准确度不高,且是直接利用搜索引擎对视频内容进行的搜索,而搜索引擎在处理视频内容时可能存在困难,影响了相关信息的检索效率。
技术实现思路
1、本发明提供一种基于视频的图文网页生成方法及装置,用以解决现有技术中受限于搜索引擎处理视频内容困难以致影响检索效率的缺陷,以根据视频快速生成图文并茂的网页,便于通过图文等方式快速获取信息,且有利于搜索引擎抓取信息。
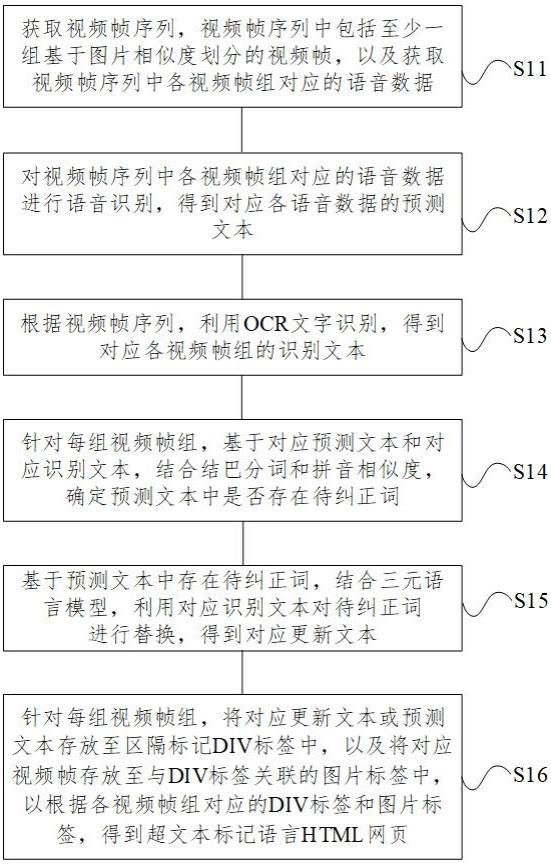
2、本发明提供一种基于视频的图文网页生成方法,包括:获取视频帧序列,视频帧序列中包括至少一组基于图片相似度划分的视频帧,以及获取视频帧序列中各视频帧组对应的语音数据;对视频帧序列中各视频帧组对应的语音数据进行语音识别,得到对应各语音数据的预测文本;根据视频帧序列,利用ocr文字识别,得到对应各视频帧组的识别文本;针对每组视频帧组,基于对应预测文本和对应识别文本,结合结巴分词和拼音相似度,确定预测文本中是否存在待纠正词;基于预测文本中存在待纠正词,结合三元语言模型,利用对应识别文本对待纠正词进行替换,得到对应更新文本;针对每组视频帧组,将对应更新文本或预测文本存放至区隔标记div标签中,以及将对应视频帧存放至与div标签关联的图片标签中,以根据各视频帧组对应的div标签和图片标签,得到超文本标记语言html网页。
3、根据本发明提供的一种基于视频的图文网页生成方法,获取视频帧序列,包括:获取目标视频;基于预设间隔或预设视频起始时间,提取目标视频中的视频帧,得到视频帧序列。
4、根据本发明提供的一种基于视频的图文网页生成方法,在基于预设间隔或预设视频起始时间,提取目标视频中的视频帧之后,包括:对提取的各个视频帧分别进行质量检测,得到对应各视频帧的质量评分;将相邻视频帧转换为向量,并利用余弦相似度,得到对应相邻视频帧的图片相似度;确定各个相邻视频帧的图片相似度大于图片预设阈值,以将对应所有相邻视频帧划分为同一视频帧组;针对同一视频帧组,将质量评分最大的视频帧作为对应视频帧组的视频帧,得到视频帧序列。
5、根据本发明提供的一种基于视频的图文网页生成方法,获取视频帧序列中各视频帧组对应的语音数据,包括:获取用于提取得到视频帧序列的目标视频;基于视频帧序列中各视频帧组的起止时间,对目标视频进行切分,得到视频帧序列中各视频帧组对应的语音数据;其中,视频帧组的起止时间是根据对应视频帧组中第一帧的开始时间和最后一帧的结束时间确定的。
6、根据本发明提供的一种基于视频的图文网页生成方法,对视频帧序列中各视频帧组对应的语音数据进行语音识别,得到对应各语音数据的预测文本,包括:将各视频帧组对应的语音数据输入至文字转换模型中,得到文字转换模型输出的各视频帧组对应的预测文本;其中,文字转换模型是基于语音训练文件和语音训练文件对应的文本标签训练得到的。
7、根据本发明提供的一种基于视频的图文网页生成方法,针对每组视频帧组,基于对应预测文本和对应识别文本,结合结巴分词和拼音相似度,确定预测文本中是否存在待纠正词,包括:针对每组视频帧组,利用结巴分别对相应预测文本和识别文本进行分词,得到对应预测文本分词和识别文本分词;根据预测文本分词和识别文本分词,利用拼音相似度,得到对应拼音相似度;基于拼音相似度大于拼音预设阈值,确定对应预测文本分词为待纠正词。
8、根据本发明提供的一种基于视频的图文网页生成方法,基于预测文本中存在待纠正词,结合三元语言模型,利用对应识别文本对待纠正词进行替换,得到对应更新文本,包括:根据待纠正词和待纠正词所属视频帧组对应预测文本,利用三元语言模型,得到第一出现概率;根据待纠正词对应的识别文本分词和待纠正词所属视频帧组对应预测文本,利用三元语言模型,得到第二出现概率;确定第二出现概率大于第一出现概率,则利用对应识别文本分词对对应待纠正词进行替换。
9、本发明还提供一种基于视频的图文网页生成装置,包括:数据获取模块,获取视频帧序列,视频帧序列中包括至少一组基于图片相似度划分的视频帧,以及获取视频帧序列中各视频帧组对应的语音数据;语音识别模块,对视频帧序列中各视频帧组对应的语音数据进行语音识别,得到对应各语音数据的预测文本;文字识别模块,根据视频帧序列,利用ocr文字识别,得到对应各视频帧组的识别文本;纠错模块,针对每组视频帧组,基于对应预测文本和对应识别文本,结合结巴分词和拼音相似度,确定预测文本中是否存在待纠正词;更新模块,基于预测文本中存在待纠正词,结合三元语言模型,利用对应识别文本对待纠正词进行替换,得到对应更新文本;网页生成模块,针对每组视频帧组,将对应更新文本或预测文本存放至区隔标记div标签中,以及将对应视频帧存放至与div标签关联的图片标签中,以根据各视频帧组对应的div标签和图片标签,得到超文本标记语言html网页。
10、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时实现如上述任一种基于视频的图文网页生成方法的步骤。
11、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种基于视频的图文网页生成方法的步骤。
12、本发明还提供一种计算机程序产品,包括计算机程序,计算机程序被处理器执行时实现如上述任一种基于视频的图文网页生成方法的步骤。
13、本发明提供的基于视频的图文网页生成方法及装置,通过对视频帧组对应的语音数据进行语音数据进行语音识别,以及通过ocr对相应视频帧组进行文字识别,从而根据识别文本确定是否对预测文本进行纠错,进而便于根据纠错后的预测文本及其对应的视频帧生成图文并茂的网页,节省了大量的时间,既保证了网页内容的准确性,又便于用户阅读,使读者能通过多种方式获取视频信息,且有利于利用搜索引擎对文字内容进行搜索。
技术特征:
1.一种基于视频的图文网页生成方法,其特征在于,包括:
2.根据权利要求1所述的基于视频的图文网页生成方法,其特征在于,所述获取视频帧序列,包括:
3.根据权利要求2所述的基于视频的图文网页生成方法,其特征在于,在所述基于预设间隔或预设视频起始时间,提取所述目标视频中的视频帧之后,包括:
4.根据权利要求1所述的基于视频的图文网页生成方法,其特征在于,所述获取所述视频帧序列中各视频帧组对应的语音数据,包括:
5.根据权利要求1所述的基于视频的图文网页生成方法,其特征在于,所述对所述视频帧序列中各视频帧组对应的语音数据进行语音识别,得到对应各语音数据的预测文本,包括:
6.根据权利要求1所述的基于视频的图文网页生成方法,其特征在于,所述针对每组视频帧组,基于对应预测文本和对应识别文本,结合结巴分词和拼音相似度,确定所述预测文本中是否存在待纠正词,包括:
7.根据权利要求6所述的基于视频的图文网页生成方法,其特征在于,所述基于所述预测文本中存在所述待纠正词,结合三元语言模型,利用对应识别文本对所述待纠正词进行替换,得到对应更新文本,包括:
8.一种基于视频的图文网页生成装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1至7任一项所述基于视频的图文网页生成方法的步骤。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述基于视频的图文网页生成方法的步骤。
技术总结
本发明提供一种基于视频的图文网页生成方法及装置,涉及互联网技术领域,方法包括:获取包括至少一组视频帧组的视频帧序列,以及获取各视频帧组对应的语音数据;对各语音数据进行语音识别;对各视频帧组进行OCR文字识别;针对每组视频帧组,基于对应语音识别得到的预测文本和对应文字识别得到的识别文本,结合结巴分词和拼音相似度,确定预测文本中存在待纠正词,并结合三元语言模型,利用对应识别文本对待纠正词进行替换;针对每组视频帧组,将替换后的文本或预测文本存放至区隔标记DIV标签中,以及将对应视频帧存放至与DIV标签关联的图片标签中,得到超文本标记语言HTML网页。本发明既保证了网页内容的准确性,又便于用户阅读。
技术研发人员:刘成书,唐海霞,王涛,韩博,刘真,高凌辉,李文永,卫世杰,孙思遥,高树奎,张小师,刘亚伟
受保护的技术使用者:北京信立方科技发展股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!