基于集成语义规则和表示学习的知识图谱融合方法
本发明属于人工智能,特别涉及一种知识融合方法,可用于各种知识图谱相关场景下的智能问答、信息检索和自动化推荐。
背景技术:
1、知识图谱的知识来源广泛,在对不同来源的知识进行抽取整合时,知识冗余问题严重。为解决这个问题学术界提出了知识融合的概念,知识融合是将来自不同知识源的异构等价知识在同一本体框架下进行消歧整合,以提高知识的质量。知识融合一般解决实体对齐任务,有基于传统概率模型、机器学习和深度学习三类方法。通过知识表示学习将实体嵌入到低维稠密的向量空间,再衡量向量的相似度来进行知识的融合对齐是目前一种主流的方法。其中大多数方法都使用翻译模型或图神经网络进行知识表示学习,有较强的泛化性和表示能力。
2、chen等在其发表的论文“mtranse:multilingual knowledge graph embeddingsfor cross-lingual knowledge alignment”中基于transe模型提出了一个跨语言知识图谱嵌入模型mtranse,实现不同语言知识图谱的嵌入对齐。该模型通过在分离的嵌入空间中编码每种语言的实体和关系,为每个嵌入向量提供了到其他空间中跨语言对应向量的转换,同时保留了单语言嵌入的功能。mtranse使用三种不同的技术来表示跨语言转换,即轴校准、平移向量和线性变换,并使用不同的损失函数推导出mtranse的五种变体。mtranse模型可以在部分对齐的图上进行训练,其中只有一小部分三元组与跨语言对应的三元组对齐,训练出的模型在不同的任务上取得了较佳的结果,具有一定的泛化性。该方法存在的不足之处是需要大量的监督数据来训练模型,而高质量的监督数据获取困难,存在数据采集、数据清洗、数据标注等多重困难,在缺少监督数据的情况下模型容易欠拟合,不能有效融合等价的知识三元组,准确性低。
3、申请号为202310409170.4专利文献公开了“一种面向知识融合的多域知识冲突检测方法”,其对多个来源的三元组组成的多源知识集合进行分块,得到第一多源知识集合和第二多源知识集合;其中,所述第一多源知识集合包括存在属性冗余或属性冲突的三元组;所述第二多源知识集合包括存在关系冗余或关系冲突的三元组。对所述第一多源知识集合进行属性融合对齐,对所述第二多源知识集合进行关系融合对齐。这种规则匹配方法不依赖样本的数量,在设计好的规则下能达到一定的准确度。但是该方法只能融合符合设定规则的知识三元组,欠缺一定的泛化性,适应能力差。
技术实现思路
1、本发明的目的在于针对上述现有技术的问题,提出一种基于集成语义规则和表示学习的知识图谱融合方法,以实现在少样本数据的情况下等价三元组的有效融合,提高知识图谱融合的泛化能力和准确性。
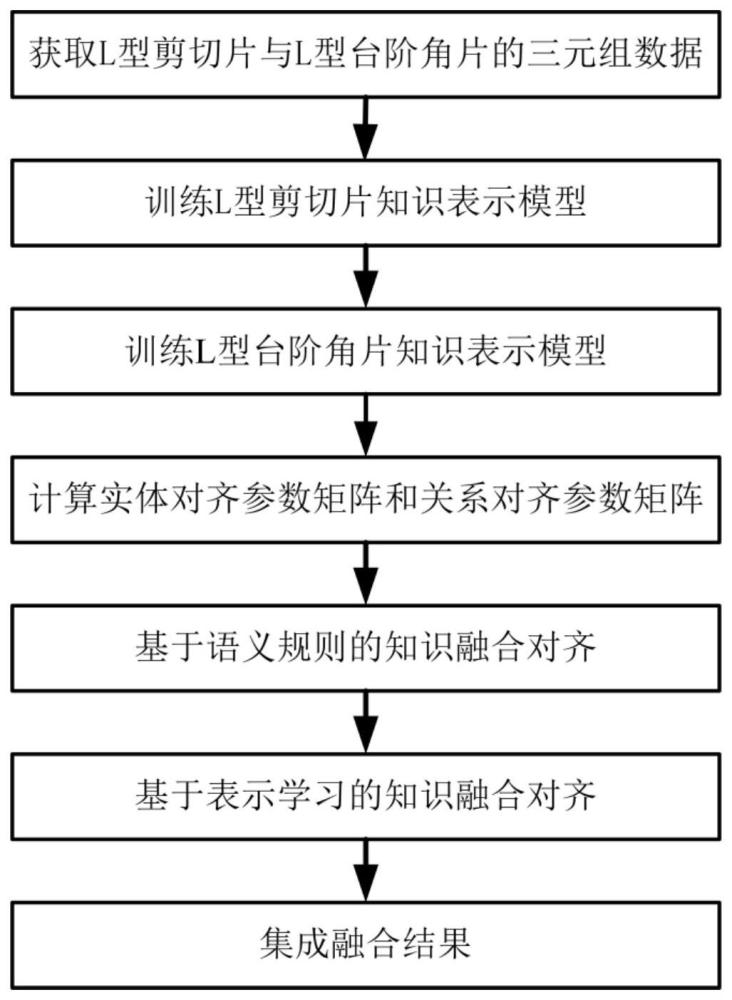
2、为了实现上述目的,本发明的技术方案包括如下步骤:
3、(1)训练两个不同的表示学习模型:
4、(1a)选用现有的l型剪切片和l型台阶角片catia三维模型,并对其进行解析得到l型剪切片三元组数据和l型台阶角片三元组数据这两种数据;
5、(1b)基于所述两种数据,采用梯度下降法分别对现有表示学习模型进行训练,得到训练好的l型剪切片表示学习模型和训练好的l型台阶角片表示学习模型;
6、(2)通过训练好的模型获得两种参数矩阵:
7、(2a)将现有预对齐的种子三元组数据分别输入到训练好的l型剪切片表示学习模型和训练好的l型台阶角片表示学习模型进行向量化表示,得到两种向量表示;
8、(2b)利用梯度下降法计算得到所述两种向量表示之间的实体对齐参数矩阵ve和关系对齐参数矩阵vr;
9、(3)定义语义规则:
10、通过计算l型剪切片和l型台阶角片的三元组数据的实体之间的语义编辑距离和杰卡德系数来度量实体的相似性;
11、通过将两类三元组实体的语义编辑距离和杰卡德系数进行平均,综合衡量实体之间的相似程度;
12、将平均相似度为1的两个实体作为等价实体,寻找等价实体对应的等价三元组,对等价三元组进行融合对齐。
13、(4)对l型剪切片三元组数据和l型台阶角片三元组数据进行两次融合:
14、(4a)一次融合:利用该定义的语义规则对l型剪切片三元组数据和l型台阶角片三元组数据之间进行相似性度量和平均,得到这两种三元组数据之间的相似度,寻找平均相似度为1的等价实体所对应的等价三元组,并对其进行等价三元组的一次融合对齐,得到一次融合后的反例和正例融合结果;
15、(4b)二次融合:
16、(4b1)将l型剪切片三元组数据一次融合后的融合反例输入到训练好的l型剪切片表示学习模型进行向量化表示,将l型台阶角片三元组数据一次融合后的融合反例输入到训练好的l型台阶角片表示学习模型进行向量化表示,并利用实体对齐参数矩阵ve和关系对齐参数矩阵vr对这两个向量进行空间的统一;
17、(4b2)在统一的空间内,计算这两种数据向量之间的余弦距离,利用该距离度量这两种数据向量之间的相似度,将相似性较大的三元组数据进行二次融合对齐;
18、(5)将l型剪切片和l型台阶角片一次融合后的融合正例和二次融合后的融合正例进行集成,即将这两次融合得到的融合正例组合到一起,完成对l型剪切片和l型台阶角片等价三元组的融合对齐。
19、本发明与现有技术相比,具有如下优点:
20、第一,泛化性高,适应性强。
21、传统的规则匹配方法只能融合符合规则的三元组,欠缺泛化性和适应性;
22、本发明由于集成了表示学习的融合方法,具有较高的泛化性,并能够通过样本的多样性实现融合的高适应性。
23、第二,在少样本的情况下准确性高。
24、传统的基于表示学习的深度学习模型需要大量的监督数据来训练模型,但是高质量的监督数据获取困难,存在数据采集、数据清洗、数据标注等多重困难,在缺少监督数据的情况下模型容易欠拟合,不能有效融合等价的三元组,准确性低。
25、本发明由于集成了语义规则的融合方法,能够在少样本的情况下提高对等价三元组融合的准确性,可有效实现等价三元组的融合对齐。
技术特征:
1.一种集成语义规则和表示学习来实现等价三元组融合对齐的方法,其特征在于,包括如下:
2.根据权利要求1所述的方法,其特征在于,步骤(1a)中对l型剪切片和l型台阶角片catia三维模型进行解析得到三元组数据,实现步骤包括如下:
3.根据权利要求1所述的方法,其特征在于,步骤(1b)中基于所述两种数据,采用梯度下降法分别对现有的表示学习模型进行训练,实现步骤包括如下:
4.根据权利要求1所述的方法,其特征在于,步骤(2b)中利用梯度下降法计算得到所述两种向量表示之间的实体对齐参数矩阵ve和关系对齐参数矩阵vr,实现步骤包括如下:
5.根据权利要求1所述的方法,其特征在于,步骤(3)中所述定义语义规则,是通过计算l型剪切片和l型台阶角片的三元组数据的实体之间的语义编辑距离和杰卡德系数来度量实体的相似性;通过将两类三元组实体的语义编辑距离和杰卡德系数进行平均,综合衡量实体之间的相似程度;将平均相似度为1的两个实体作为等价实体,寻找等价实体对应的等价三元组,对等价三元组进行融合对齐。
6.根据权利要求1所述的方法,其特征在于,步骤(4a)中利用定义的语义规则对l型剪切片三元组数据和l型台阶角片三元组数据之间进行相似性度量和平均,实现步骤包括如下:
7.根据权利要求1所述的方法,其特征在于,步骤(4a)中对平均相似度为1的等价实体对所对应的等价三元组进行一次融合对齐,是对平均相似度为1的等价实体所对应的等价三元组进行合并,获得到融合正例,剩下无法合并的三元组作为融合反例,得到一次融合的结果。
8.根据权利要求1所述的方法,其特征在于,步骤(4b2)中在统一的空间内,计算这两种数据向量之间的余弦距离,公式如下:
技术总结
本发明公开了一种基于集成语义规则和表示学习的知识图谱融合方法,主要解决现有技术无法在少样本数据情况下对等价三元组的进行有效融合和融合泛化性低的问题。其实现方案是:首先训练基于表示学习的知识融合模型,然后通过语义规则进行一次知识融合,得到一次融合后的融合反例和融合正例;接着将融合反例输入到基于表示学习知识融合模型中进行二次融合,得到二次融合后的融合反例和融合正例;最后集成两次融合结果中的正例,完成对等价三元组的融合对齐。本发明能在少样本情况下提高等价三元组融合的准确性,有效实现等价三元组的融合对齐,且具有较高的泛化性,可用于各种知识图谱相关场景下的智能问答、信息检索和自动化推荐。
技术研发人员:王奇斌,韩冰,张行行,张金刚,王超君,孙丽强,程普强,楚涛,冯莉,朱玉虎
受保护的技术使用者:西安电子科技大学
技术研发日:
技术公布日:2024/3/11
- 还没有人留言评论。精彩留言会获得点赞!