一种基于FPGA的DNN推理加速器设计的制作方法
本发明属于人工智能神经网络,具体来说是一种基于fpga的dnn推理加速器设计。
背景技术:
1、随着深度学习技术在人工智能领域的广泛应用,对于能够高效执行dnn模型推理任务的硬件加速器的需求急剧增加。然而,在现有技术中,尤其是那些基于传统cpu和gpu的系统,在dnn推理加速器的设计和实施方面存在若干问题:
2、1.算力与能耗问题:现有的处理器在执行复杂dnn推理任务时面临着算力不足和能耗过高的问题。虽然传统的cpu和gpu在通用计算任务中表现良好,但它们在执行dnn推理时的能源效率低下,特别是在移动和边缘计算设备中,这些设备的能源和散热能力有限。
3、2.时延与成本考量:推理芯片需要在保持高性能的同时,考虑到时延和成本效益。cpu和gpu在处理时延敏感的任务时可能无法满足低延迟的需求,而高性能的硬件成本也可能过高,不适合成本敏感型应用。
4、3.灵活性与优化不足:虽然fpga提供了可编程性和灵活性,但许多现有的基于fpga的推理加速器在设计时未能充分利用这些特性。这导致了在针对特定dnn模型和推理任务优化时,现有方案无法提供最佳性能。
技术实现思路
1、本发明的主要目的,在于提供一种基于fpga的dnn推理加速器设计,可以有效解决背景技术中所涉及的问题。
2、为实现上述目的,本发明所采取的技术方案为:
3、一种基于fpga的dnn推理加速器设计,所述加速器包括:
4、一个计算部分,用于执行dnn推理运算;
5、一个控制部分,用于管理所述计算部分的工作模式、权重值和运算精度;
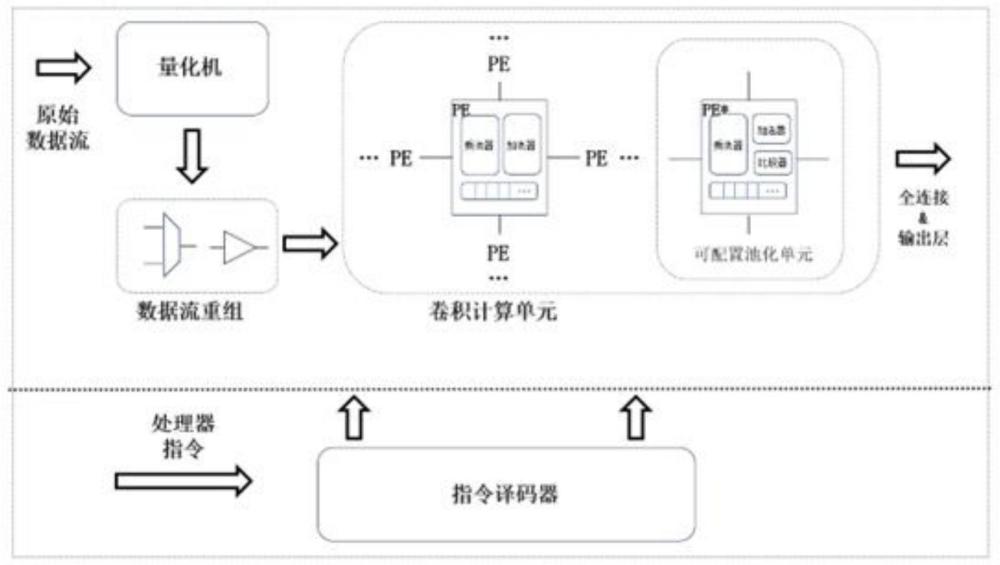
6、其中,所述计算部分包括多个处理元件(pe),每个pe包含加法器、乘法器和内部缓存,用于存储权重值参数、量化掩码和计算缓存值;
7、所述控制部分包括外部指令译码器和精简指令集的控制器,以实现对所述计算部分的配置。
8、进一步的,所述计算部分进一步包括一个量化机,用于在推理过程开始前对原始数据流进行量化。
9、进一步的,所述量化机使用掩码的方式决定量化精度,以便在保留原权重参数值的同时调整量化精度。
10、进一步的,所述计算部分进一步包括一个脉冲阵列,用于加速矩阵运算。
11、进一步的,所述脉冲阵列采用1-d结构,其中权重值参数预先装载,而数据集参数动态流入。
12、进一步的,所述脉冲阵列前设置有数据流重组模块,用于重新排列输入数据流并加入延迟,以满足矩阵运算的特性。
13、进一步的,所述数据流重组模块包括延时和多路选择器(mux),其中延时用于调整数据流结构,mux用于在需要维度匹配时调整数据流。
14、进一步的,所述pe可配置为执行池化运算或承载全连接层和激活函数的乘加运算。
15、与现有技术相比,本发明具有如下有益效果:
16、1.提升算力与降低能耗:本发明的基于fpga的dnn推理加速器设计,通过高度优化的硬件结构来增强算力,同时降低能耗。这得益于加速器中的计算单元和存储单元的紧密集成,以及对数据流和计算流程的有效管理,确保了高效的数据处理和最小化的能量消耗。这一设计特别适用于能源受限的移动和边缘计算设备。
17、2.降低时延与优化成本效益:发明中的推理加速器针对低延迟运算进行了特别优化,提供了快速的数据处理能力,以支持实时或近实时的推理任务。此外,通过利用fpga的可编程性,本设计能够在不牺牲性能的前提下,以较低的成本实现定制化硬件解决方案,从而提高整体的成本效益比。
18、3.增强设计灵活性与性能优化:本发明充分利用fpga的灵活性,提供了一种可针对特定dnn模型和推理任务进行优化的加速器设计。这种设计允许在硬件层面进行定制化调整,以适应不同模型的需求,从而提供更优的性能和更高的运算效率。
技术特征:
1.一种基于fpga的dnn推理加速器设计,其特征在于,所述加速器包括:
2.根据权利要求1所述的基于fpga的dnn推理加速器设计,其特征在于,所述计算部分进一步包括一个量化机,用于在推理过程开始前对原始数据流进行量化。
3.根据权利要求2所述的基于fpga的dnn推理加速器设计,其特征在于,所述量化机使用掩码的方式决定量化精度,以便在保留原权重参数值的同时调整量化精度。
4.根据权利要求1所述的基于fpga的dnn推理加速器设计,其特征在于,所述计算部分进一步包括一个脉冲阵列,用于加速矩阵运算。
5.根据权利要求4所述的基于fpga的dnn推理加速器设计,其特征在于,所述脉冲阵列采用1-d结构,其中权重值参数预先装载,而数据集参数动态流入。
6.根据权利要求5所述的基于fpga的dnn推理加速器设计,其特征在于,所述脉冲阵列前设置有数据流重组模块,用于重新排列输入数据流并加入延迟,以满足矩阵运算的特性。
7.根据权利要求6所述的基于fpga的dnn推理加速器设计,其特征在于,所述数据流重组模块包括延时和多路选择器(mux),其中延时用于调整数据流结构,mux用于在需要维度匹配时调整数据流。
8.根据权利要求1所述的基于fpga的dnn推理加速器设计,其特征在于,所述pe可配置为执行池化运算或承载全连接层和激活函数的乘加运算。
技术总结
本发明公开一种基于FPGA的DNN推理加速器设计,包括多个独立处理元件(PE)以及一个精简指令集的控制部分。每个PE配有加法器、乘法器和内部缓存,支持并行数据处理,加速推理运算。控制部分负责解码指令和配置计算任务,确保运算精度和效率。加速器内置量化机在推理前对数据进行优化量化,配合脉冲阵列以1‑D结构加速矩阵运算。数据流重组模块调整输入数据以符合运算需求。PE的灵活配置适应多种DNN模型,提高了推理效率和应用范围。
技术研发人员:董俊逸,赵鑫鑫,姜凯
受保护的技术使用者:山东浪潮科学研究院有限公司
技术研发日:
技术公布日:2024/2/25
- 还没有人留言评论。精彩留言会获得点赞!