数据清洗方法、终端设备及存储介质与流程
本发明涉及数据清洗,尤其涉及一种数据清洗方法、终端设备及存储介质。
背景技术:
1、数据清洗(data cleaning)是指对原始数据进行处理和加工,以消除或纠正其中的错误、不一致性、缺失值和异常值等问题,使数据符合预期的标准和要求的过程。数据清洗是数据预处理的重要步骤之一,其目的是确保数据的质量和可靠性,为后续的数据分析、建模和决策提供可靠的基础。
2、在相关的数据清洗方案中,通过人工编写待清洗数据对应的清洗规则,根据清洗规则对待清洗数据逐条进行清洗,从而检测并修复待清洗数据中的错误和噪声。然而,基于人工制定的清洗规则对待清洗数据进行清洗的方式,难以涵盖所有可能的数据情况,容易导致数据清洗质量差的技术问题。
3、上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现思路
1、本发明实施例通过提供一种数据清洗方法、终端设备及计算机可读存储介质,旨在解决数据清洗质量差的技术问题。
2、为实现上述目的,本发明实施例提供一种数据清洗方法,所述数据清洗方法包括以下:
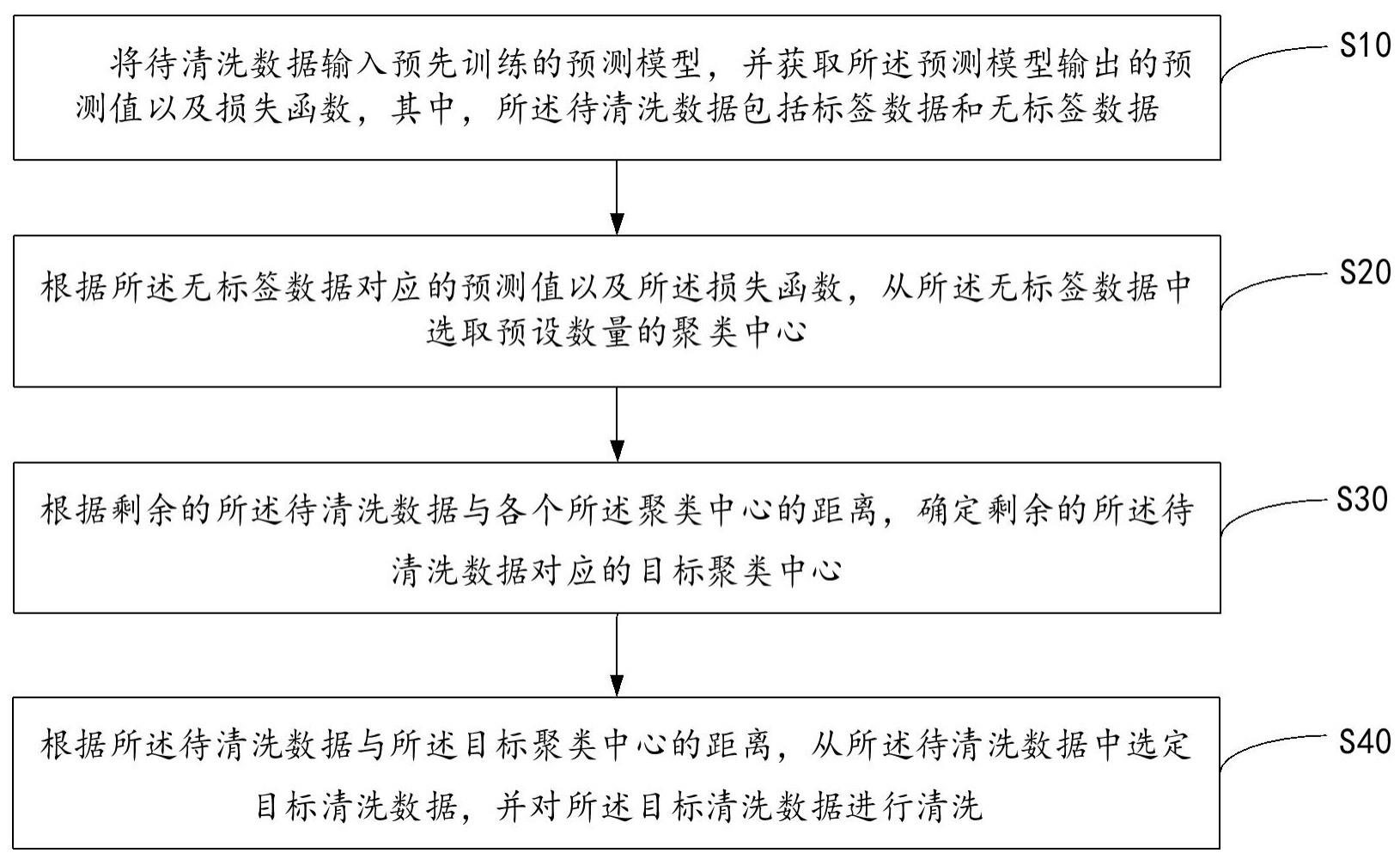
3、将待清洗数据输入预先训练的预测模型,并获取所述预测模型输出的预测值以及损失函数,其中,所述待清洗数据包括标签数据和无标签数据;
4、根据所述无标签数据对应的预测值以及所述损失函数,从所述无标签数据中选取预设数量的聚类中心;
5、根据剩余的所述待清洗数据与各个所述聚类中心的距离,确定剩余的所述待清洗数据对应的目标聚类中心;
6、根据所述待清洗数据与所述目标聚类中心的距离,从所述待清洗数据中选定目标清洗数据,并对所述目标清洗数据进行清洗。
7、可选地,所述根据所述无标签数据对应的预测值以及所述损失函数,从所述无标签数据中选取预设数量的聚类中心的步骤,包括:
8、根据所述无标签数据对应的预测值以及所述损失函数,确定所述无标签数据对应的梯度向量;
9、将满足预设条件的梯度向量对应的无标签数据作为所述聚类中心。
10、所述根据剩余的所述待清洗数据与各个所述聚类中心的距离,确定剩余的所述待清洗数据对应的目标聚类中心的步骤之后,包括:
11、将剩余的所述待清洗数据划分至所述目标聚类中心所属的目标聚类;
12、根据所述目标聚类对应的所述待清洗数据,更新所述目标聚类的所述目标聚类中心;
13、在所述目标聚类中心收敛时,执行所述根据所述待清洗数据与所述目标聚类中心的距离,从所述待清洗数据中选定目标清洗数据,并对所述目标清洗数据进行清洗的步骤。
14、可选地,所述将剩余的所述待清洗数据划分至所述目标聚类中心所属的目标聚类的步骤之后,包括:
15、删除所述目标聚类中与所述目标聚类中心的距离最小的所述待清洗数据。
16、所述根据剩余的所述待清洗数据与各个所述聚类中心的距离,确定剩余的所述待清洗数据对应的目标聚类中心的步骤,包括:
17、获取剩余的所述待清洗数据在所述预测模型的全连接层的特征值,并根据所述特征值,确定剩余的所述待清洗数据与各个所述聚类中心的距离;
18、将与所述待清洗数据的距离最小的聚类中心,作为所述待清洗数据对应的所述目标聚类中心。
19、可选地,所述将待清洗数据输入预先训练的预测模型,并获取所述预测模型输出的预测值以及损失函数的步骤之前,包括:
20、获取训练的样本数据,将所述样本数据作为节点,将所述样本数据之间的相似度作为边关系,其中,所述样本数据包括标签数据和无标签数据,所述标签数据对应的节点为标签节点,所述无标签数据对应的节点为无标签节点;
21、根据所述节点和所述边关系构建图结构;
22、根据所述图结构的边关系,将所述标签节点的标签信息传播至所述无标签节点;
23、基于所述标签节点的所述标签信息和所述标签数据,构建并训练所述预测模型。
24、可选地,所述根据所述待清洗数据与所述目标聚类中心的距离,从所述待清洗数据中选定目标清洗数据,并对所述目标清洗数据进行清洗的步骤之后,包括:
25、获取所述预测模型对应的召回率和/或准确率,在所述召回率和/或准确率小于预设阈值时,继续执行所述将待清洗数据输入预先训练的预测模型,并获取所述预测模型输出的预测值以及损失函数的步骤;和/或,
26、在所述目标清洗数据的数量小于预设清洗数量时,继续执行所述将待清洗数据输入预先训练的预测模型,并获取所述预测模型输出的预测值以及损失函数的步骤。
27、可选地,所述获取所述预测模型对应的召回率和/或准确率的步骤之后,还包括:
28、根据所述召回率和/或准确率,确定所述预测模型的评估结果;
29、根据所述评估结果,更新所述预测模型的模型参数。
30、此外,本发明为实现上述目的,本发明还提供一种终端设备,所述终端设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的数据清洗程序,所述数据清洗程序被所述处理器执行时实现如上所述的数据清洗方法的步骤。
31、此外,本发明为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有数据清洗程序,所述数据清洗程序被处理器执行时实现如上所述的数据清洗方法的步骤。
32、本发明一实施例提出的一种数据清洗方法,终端设备及计算机可读存储介质,通过将待清洗数据输入预先训练的预测模型,并获取预测模型输出的预测值以及损失函数,其中,待清洗数据包括标签数据和无标签数据,然后根据无标签数据对应的预测值以及损失函数,从无标签数据中选取预设数量的聚类中心,根据剩余的待清洗数据与各个聚类中心的距离,确定剩余的待清洗数据对应的目标聚类中心,根据待清洗数据与目标聚类中心的距离,从待清洗数据中选定目标清洗数据,并对目标清洗数据进行清洗。由于无标签数据不受任何预先定义的标签或类别限制,可以更好地反映数据的内在结构和相似性,因此以无标签数据作为初始的聚类中心进行分类,使得选定的目标清洗数据,涵盖了所有可能出现的数据情况,达成提高数据清洗质量的技术效果。
技术特征:
1.一种数据清洗方法,其特征在于,所述数据清洗方法包括:
2.如权利要求1所述的数据清洗方法,其特征在于,所述根据所述无标签数据对应的预测值以及所述损失函数,从所述无标签数据中选取预设数量的聚类中心的步骤,包括:
3.如权利要求1所述的数据清洗方法,其特征在于,所述根据剩余的所述待清洗数据与各个所述聚类中心的距离,确定剩余的所述待清洗数据对应的目标聚类中心的步骤之后,包括:
4.如权利要求1所述的数据清洗方法,其特征在于,所述将剩余的所述待清洗数据划分至所述目标聚类中心所属的目标聚类的步骤之后,包括:
5.如权利要求1所述的数据清洗方法,其特征在于,所述根据剩余的所述待清洗数据与各个所述聚类中心的距离,确定剩余的所述待清洗数据对应的目标聚类中心的步骤,包括:
6.如权利要求1所述的数据清洗方法,其特征在于,所述将待清洗数据输入预先训练的预测模型,并获取所述预测模型输出的预测值以及损失函数的步骤之前,包括:
7.如权利要求1所述的数据清洗方法,其特征在于,所述根据所述待清洗数据与所述目标聚类中心的距离,从所述待清洗数据中选定目标清洗数据,并对所述目标清洗数据进行清洗的步骤之后,包括:
8.如权利要求7所述的数据清洗方法,其特征在于,所述获取所述预测模型对应的召回率和/或准确率的步骤之后,还包括:
9.一种终端设备,其特征在于,所述终端设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的终端设备的数据清洗程序,所述终端设备的数据清洗程序被所述处理器执行时实现如权利要求1至8中任一项所述的数据清洗方法的步骤。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有终端设备的数据清洗程序,所述终端设备的数据清洗程序被处理器执行时实现如权利要求1至8中任一项所述的数据清洗方法的步骤。
技术总结
本发明公开了一种数据清洗方法、终端设备及存储介质,所述方法包括:将待清洗数据输入预先训练的预测模型,并获取所述预测模型输出的预测值以及损失函数,其中,所述待清洗数据包括标签数据和无标签数据;根据所述无标签数据对应的预测值以及所述损失函数,从所述无标签数据中选取预设数量的聚类中心;根据剩余的所述待清洗数据与各个所述聚类中心的距离,确定剩余的所述待清洗数据对应的目标聚类中心;根据所述待清洗数据与所述目标聚类中心的距离,从所述待清洗数据中选定目标清洗数据,并对所述目标清洗数据进行清洗。以无标签数据作为初始的聚类中心进行分类,使得选定的目标清洗数据涵盖了所有可能出现的数据情况,能够提高数据清洗质量。
技术研发人员:吴雨培,孟超超
受保护的技术使用者:北京阿丘科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!